
creator2.4.x 使用cc.AssetsManager管理资源,使用Asset Bundle 作为资源模块化工具。
默认bundle有internal、main,分别是引擎内置bundle,以及用户默认bundle;
如果主动创建了assets/resources文件夹,还会多一个resources bundle。
资源加载分为静态加载和动态加载
直接被编辑器节点树引用的资源,实例化时,引擎会自动静态加载;
需要动态加载的资源,一般放在resources目录下,使用cc.resources.loadAny加载;
但是家在资源本质上都是通过cc.AssetsManager的pipeline加载管线进行加载的
以下是一个已经配置为bundle的文件夹,以及其构建目录
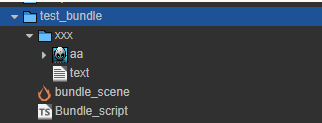
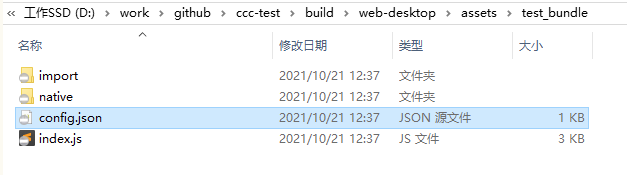
import文件夹里都是json文件,存放cc.Asset资源的序列化信息,bundle所有的资源如cc.SceneAsset、cc.SpriteFrame、cc.Texture2D、cc.TextAsset等都会存在这里。Text或Json这类文本资源直接就内容填在这里了,非文本资源存则会声明依赖的是的哪些文件。
native文件夹是真正的资源文件目录,存放所有非文本资源,如图片、字体等文件。
config.json文件是上面所有这些资源的关联配置描述,存放资源路径和uuid的对应关系。
以下是uuid解码后的config.json:
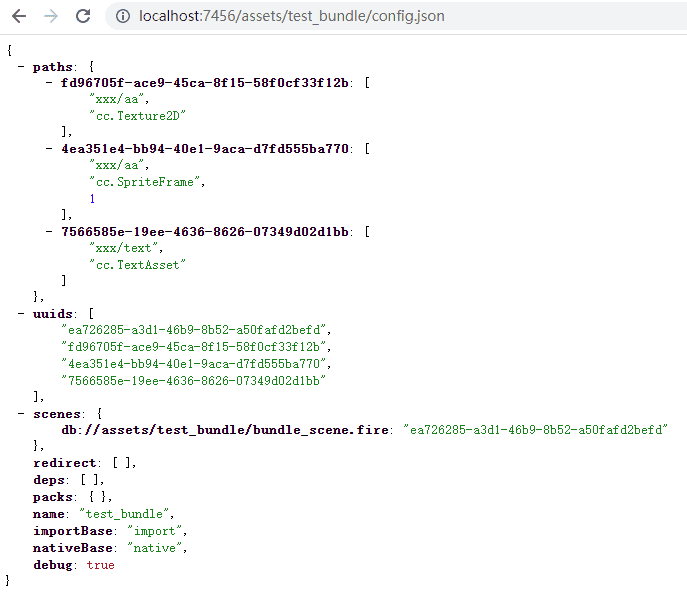
调用loadBundle实际上就是缓存这个config配置,并不会缓存相应的资源,用到资源前,必须调用bundle.load开启加载流程。
cc.assetManager.loadBundle("test_bundle",(err,bundle:cc.AssetManager.Bundle)=>{
if(err){
return;
}
bundle.load("xxx/aa",cc.SpriteFrame,(err,frame:cc.SpriteFrame)=>{
if(err){
return;
}
cc.log("---------frame加载成功")
});
})
我们今天主要研究的就是this.test_bundle.load("xxx/aa",cc.SpriteFrame)的内容了。
######简单描述一下加载流程:
1. parse,根据path找到uuid,“xxx/aa”=>“4ea351e4-bb94-40e1-9aca-d7fd555ba770”
2. combine,根据uuid找到import下的配置文件路径 “assets/test_bundle/import/4e/4ea351e4-bb94-40e1-9aca-d7fd555ba770.json”
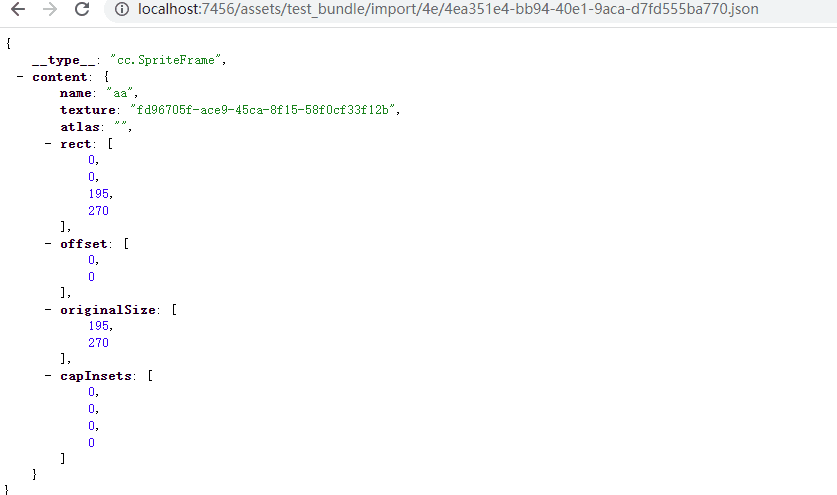
3. downloader下载该json配置文件,parse解析、反序列化该文件,生成一个cc.SpriteFrame对象,但是该对象暂无texture资源。此时本次加载管线执行完毕。
4. 再看看有没有要加载的依赖,有的话开启新的加载管线进行加载。此次依赖一个texture资源,uuid=“fd96705f-ace9-45ca-8f15-58f0cf33f12b”

也是先加载import下的json配置,然后创建cc.Texture2D对象,它依赖的就是native下的同名文件:
“assets/test_bundle/native/fd/fd96705f-ace9-45ca-8f15-58f0cf33f12b.png”
5. texture资源也加载完成以后,通过setProperties设置关联,将该texture赋值给第三步生成的cc.SpriteFrame
6. 加载完成,回调
######画了个加载管线的简易流程图:
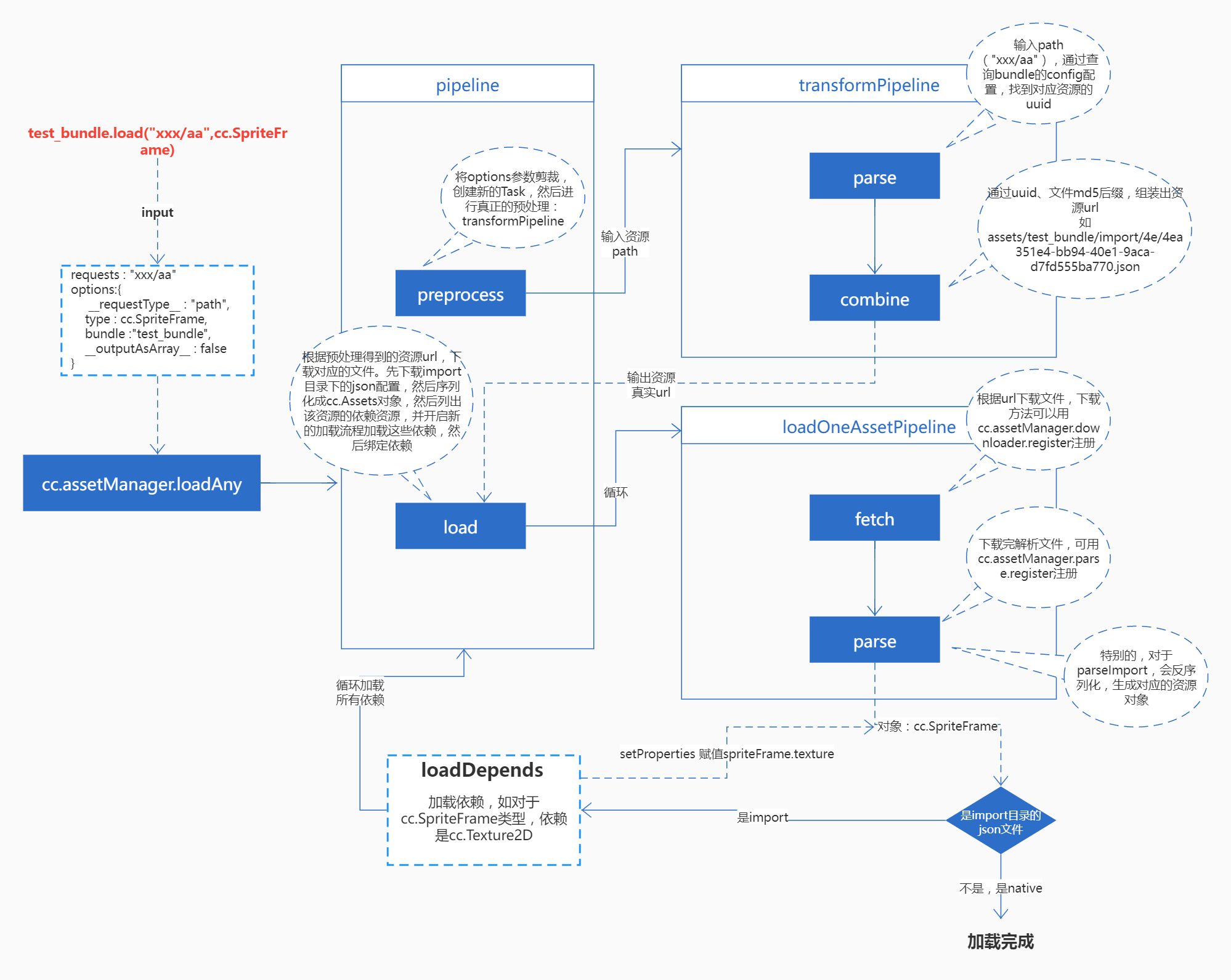
####下面,我们跟着代码一步步走
bundle.load调用cc.AssetManager.loadAny,传入初始化的options参数
load (paths, type, onProgress, onComplete) {
var { type, onProgress, onComplete } = parseLoadResArgs(type, onProgress, onComplete);
cc.assetManager.loadAny(paths, { __requestType__: RequestType.PATH, type: type, bundle: this.name, __outputAsArray__: Array.isArray(paths) }, onProgress, onComplete);
},
loadAny对参数进行校验,以适配不同的重载,然后创建Task,开启一个管线加载任务
loadAny (requests, options, onProgress, onComplete) {
var { options, onProgress, onComplete } = parseParameters(options, onProgress, onComplete);
options.preset = options.preset || 'default';
requests = Array.isArray(requests) ? requests.concat() : requests;
let task = new Task({input: requests, onProgress, onComplete: asyncify(onComplete), options});
pipeline.async(task);
}
pipeline是在AssetManager初始化的:
//this.pipeline管线分为preprocess和load两个管道
this.pipeline = pipeline.append(preprocess).append(load);
pipeline.async即按管道顺序异步执行,先调用preprocess进行预处理,然后拿预处理后的结果再调用load。
preprocess函数在core/asset-manager/preprocess.js下:
function preprocess (task, done) {
var options = task.options, subOptions = Object.create(null), leftOptions = Object.create(null);
///省略若干行,主要是剪裁options
// transform url
let subTask = Task.create({input: task.input, options: subOptions});
var err = null;
try {
task.output = task.source = transformPipeline.sync(subTask);
}
catch (e) {
err = e;
for (var i = 0, l = subTask.output.length; i < l; i++) {
subTask.output[i].recycle();
}
}
subTask.recycle();
done(err);
}
先对options参数进行剪裁,创建一个新的Task,再调用transformPipeline管线真正进行预处理,
transformPipeline也是再AssetManager里初始化的,分为parse和combine两个管道,
这两步没有异步操作,所以是同步执行两个管道,transformPipeline.sync
this.transformPipeline = transformPipeline.append(parse).append(combine);
parse和combine函数都在core/assets-manager/urlTransformer.js下,顾名思义,该文件的主要作用就是进行url转换,根据输入的资源相对路径,转换为实际的资源url。
parse函数主要逻辑:
case RequestType.PATH:
if (bundles.has(item.bundle)) {
var config = bundles.get(item.bundle)._config;
var info = config.getInfoWithPath(item.path, item.type);
if (info && info.redirect) {
if (!bundles.has(info.redirect)) throw new Error(`you need to load bundle ${info.redirect} first`);
config = bundles.get(info.redirect)._config;
info = config.getAssetInfo(info.uuid);
}
if (!info) {
out.recycle();
throw new Error(`Bundle ${item.bundle} doesn't contain ${item.path}`);
}
out.config = config;
out.uuid = info.uuid;
out.info = info;
}
out.ext = item.ext || '.json';
break;
先找到对应的bundle配置,再根据目标文件名、Asset类型查找对应的资源info,然后保存资源uuid。
这一操作引擎也有导出,如 var info = bundle.getInfoWithPath('image/a', cc.Texture2D);
本次调用后,查到uuid=“4ea351e4-bb94-40e1-9aca-d7fd555ba770”
然后是combine:
// ugly hack, WeChat does not support loading font likes 'myfont.dw213.ttf'. So append hash to directory
if (item.ext === '.ttf') {
url = `${base}/${uuid.slice(0, 2)}/${uuid}${ver}/${item.options.__nativeName__}`;
}else {
url = `${base}/${uuid.slice(0, 2)}/${uuid}${ver}${item.ext}`;
}
其实就是用资源的uuid拼凑出资源路径
本次调用后,
base=“assets/test_bundle/import”,
uuid=“4ea351e4-bb94-40e1-9aca-d7fd555ba770”,
ver="",item.ext = “.json”
所以url = “assets/test_bundle/import/4e/4ea351e4-bb94-40e1-9aca-d7fd555ba770.json”
preprocess流程这就走完了。
然后是load管道,就是对得到的资源url进行下载、解析,主要用到loadOneAssetPipeline
var loadOneAssetPipeline = new Pipeline('loadOneAsset', [
function fetch (task, done) {
var item = task.output = task.input;
var { options, isNative, uuid, file } = item;
var { reload } = options;
if (file || (!reload && !isNative && assets.has(uuid))) return done();
packManager.load(item, task.options, function (err, data) {
item.file = data;
done(err);
});
},
function parse (task, done) {
var item = task.output = task.input, progress = task.progress, exclude = task.options.__exclude__;
var { id, file, options } = item;
if (item.isNative) {
parser.parse(id, file, item.ext, options, function (err, asset) {
if (err) return done(err);
item.content = asset;
progress.canInvoke && task.dispatch('progress', ++progress.finish, progress.total, item);
files.remove(id);
parsed.remove(id);
done();
});
}
else {
var { uuid } = item;
if (uuid in exclude) {
///省略若干
}
else {
if (!options.reload && assets.has(uuid)) {
///省略若干
}
else {
parser.parse(id, file, 'import', options, function (err, asset) {
if (err) return done(err);
asset._uuid = uuid;
loadDepends(task, asset, done, true);
});
}
}
}
}
]);
第一步fetch,调用packManager.load,间接调用downloader.download,根据文件的后缀名来调用对应的下载方法,默认下载方法映射如下(core/asset-manager/downloader.js):
// dafault handler map
var downloaders = {
// Images
'.png' : downloadImage,
'.jpg' : downloadImage,
'.bmp' : downloadImage,
'.jpeg' : downloadImage,
'.gif' : downloadImage,
'.ico' : downloadImage,
'.tiff' : downloadImage,
'.webp' : downloadImage,
'.image' : downloadImage,
'.pvr': downloadArrayBuffer,
'.pkm': downloadArrayBuffer,
// Audio
'.mp3' : downloadAudio,
'.ogg' : downloadAudio,
'.wav' : downloadAudio,
'.m4a' : downloadAudio,
// Txt
'.txt' : downloadText,
'.xml' : downloadText,
'.vsh' : downloadText,
'.fsh' : downloadText,
'.atlas' : downloadText,
'.tmx' : downloadText,
'.tsx' : downloadText,
'.json' : downloadJson,
'.ExportJson' : downloadJson,
'.plist' : downloadText,
'.fnt' : downloadText,
// font
'.font' : loadFont,
'.eot' : loadFont,
'.ttf' : loadFont,
'.woff' : loadFont,
'.svg' : loadFont,
'.ttc' : loadFont,
// Video
'.mp4': downloadVideo,
'.avi': downloadVideo,
'.mov': downloadVideo,
'.mpg': downloadVideo,
'.mpeg': downloadVideo,
'.rm': downloadVideo,
'.rmvb': downloadVideo,
// Binary
'.binary' : downloadArrayBuffer,
'.bin': downloadArrayBuffer,
'.dbbin': downloadArrayBuffer,
'.skel': downloadArrayBuffer,
'.js': downloadScript,
'bundle': downloadBundle,
'default': downloadText
};
我们也可以自定义下载功能,如: cc.assetManager.downloader.register(".png",func)
本次调用downloadJson方法,回调一个json对象:
var downloadJson = function (url, options, onComplete) {
options.responseType = "json";
downloadFile(url, options, options.onFileProgress, function (err, data) {
if (!err && typeof data === 'string') {
try {
data = JSON.parse(data);
}
catch (e) {
err = e;
}
}
onComplete && onComplete(err, data);
});
};
然后存储该json对象,
packManager.load(item, task.options, function (err, data) {
item.file = data;
done(err);
});
这就下载完了,然后调用parse.parse进行解析,也是根据后缀名查找对应的解析方法:
var parsers = {
'.png' : parser.parseImage,
'.jpg' : parser.parseImage,
'.bmp' : parser.parseImage,
'.jpeg' : parser.parseImage,
'.gif' : parser.parseImage,
'.ico' : parser.parseImage,
'.tiff' : parser.parseImage,
'.webp' : parser.parseImage,
'.image' : parser.parseImage,
'.pvr' : parser.parsePVRTex,
'.pkm' : parser.parsePKMTex,
// Audio
'.mp3' : parser.parseAudio,
'.ogg' : parser.parseAudio,
'.wav' : parser.parseAudio,
'.m4a' : parser.parseAudio,
// plist
'.plist' : parser.parsePlist,
'import' : parser.parseImport
};
同样,也可以自定义解析功能,如: cc.assetManager.parsers.register(".png",func)
这里用的是parseImport:
parseImport (file, options, onComplete) {
if (!file) return onComplete && onComplete(new Error('Json is empty'));
var result, err = null;
try {
result = deserialize(file, options);
}
catch (e) {
err = e;
}
onComplete && onComplete(err, result);
}
其实就是反序列化,这里就是生成一个cc.SpriteFrame对象。
parser.parse(id, file, 'import', options, function (err, asset) {
if (err) return done(err);
asset._uuid = uuid;
loadDepends(task, asset, done, true);
});
到这里本次管线就到尾声了,我们需要的cc.SpriteFrame对象也创建了,但是是一个空的对象,没有绑定texture纹理,而loadDepends就是干这个的。
就是获取到所有依赖资源,开启新的加载管线,加载完成以后调用setProperties进行绑定。
var missingAsset = setProperties(uuid, asset, map);
如上图调用关系,最终会绑定依赖的纹理,至此加载真正完成,完成回调。
bundle.load("xxx/aa",cc.SpriteFrame,(err,frame:cc.SpriteFrame)=>{
if(err){
return;
}
cc.log("---------frame加载成功")
});