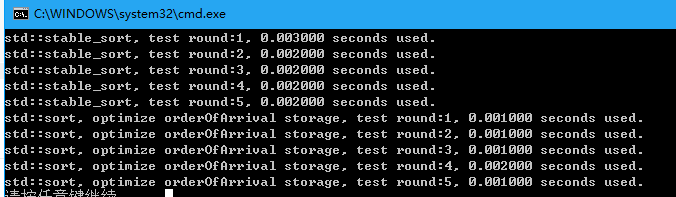
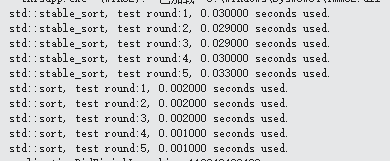
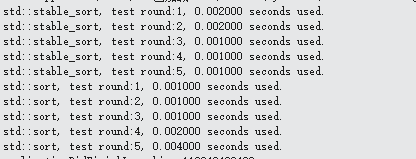
经过测试,这里提出优化方案(使用位操作合并localZOrder和OrderOfArrival, 存储为64位整数)
OrderOfArrival优化代码:
std::vector<std::pair<int, int>*> vec2;
for (auto i = 0; i < 100000; ++i)
vec2.push_back(new std::pair<int, int>(2, i + 1));
clock_t start = 0;
for (int i = 0; i < 5; ++i) {
start = clock();
std::stable_sort(vec2.begin(), vec2.end(), [](const std::pair<int, int>* l, const std::pair<int, int>* r) {
return l->first < r->first;
});
printf("std::stable_sort, test round:%d, %lf seconds used.\n", i + 1, (clock() - start) / (double)CLOCKS_PER_SEC);
}
for (int i = 0; i < 5; ++i) {
start = clock();
std::sort(vec2.begin(), vec2.end(), [](const std::pair<int, int>* l, const std::pair<int, int>* r) {
return *(long long*)l < *(long long*)r;
});
printf("std::sort, optimize orderOfArrival storage, test round:%d, %lf seconds used.\n", i + 1, (clock() - start) / (double)CLOCKS_PER_SEC);
}
X64程序测试结果, X86没明显性能提升