
在上一篇文章突破Label的缓存模式(1)-BITMAP中,我们提到CHAR模式的主要风险:字符图集的大小是受限的-总大小只有2048*2048。这里带来的风险是,不能无限制的使用CHAR模式来显示文字,因为有可能在图集重建之前把图集用完,用完的结果将导致后续使用CHAR模式的Label无法再正常显示文字,因为新的字符无法再往这张唯一的图集中继续添加了。
那么我们常规的思路有以下几种:
1. 增加文字图集张数解决限制问题。
2. 发现文字图集已经用完时,改用其它模式。直到文字贴图集重建。
3. 在唯一的一张图集上重复利用。
那么我们依次来分析以上方案的可行性:
1. 增加文字图集的张数
增加文字图集的数量并不复杂,复杂的是它所带来的问题:如果一段文本所引用的字符集索引是:0101010101这样的排列,那么在不做特殊处理的情况下,它的drawcall将会是10个,这将是不可接受的。当然最简单的处理是作个排序,先渲染所有的0,再渲染其它的字符。这样一个文本就要1-2个drawcall。虽然也不高,但是随着文字贴图图集个数增长到N,每个CHAR模式的文本的drawcall将会是1到N之间。这样不稳定的drawcall也是不可接受的,因为不敢批量使用。基于此,可以放弃这个做法,
2. 发现文字图集用完时,改成其它模式
首先不讨论临时改模式的合理性,单是要检查一个LABEL上的文本是不是能用当前图集完全渲染出来都是个麻烦的事,至少增加了许多计算过程。另外,改了缓存模式会导致不可预期的drawcall打断,内存增加,影响动态合批图集等问题。严重一点,如果一直不重建图集,那么无法想象后面的文本会处于多么不可控的显示模式下。因此也可以放弃这个思路了。
3. 在唯一的一张图集上重复利用
这个思路的难点有如下几个:
如何判断某个字符已经是废弃状态。
如何快速找到一个可被重复利用的合适的字符在图集中的位置。
如果找不到一个合适的可重复利用的字符,还有没有可利用的新的图集空间容纳新的字符。
我们依次来讨论这三个问题的可行性:
- 如何判断某个字符已经是废弃状态
文字图集上的每个字符可以用字典记录下它的位置和大小信息,还有一个是被引用的次数。判断废弃的状态可以通过对这个字符的引用次数来决定,例如一个CHAR模式的文本"abcaddae"渲染时,a字符的引用次数是3,b是1,c是1,d是2,e是1,那么文本被移除时,减除相应的引用计数即可。当某个字符的引用计数为0时,即代表它所占的图集位置是个废弃的状态,可以被回收再利用。
- 如何快速找到一个可被重复利用的合适的字符在图集中的位置
在第一点里面,我们创建的字符和图集位置的映射里面,有位置信息和大小信息。先筛选废弃状态再通过大小判断是不能容纳新的字符即可找到可重复利用的目标字符位置。
- 如果找不到一个合适的可重复利用的字符,还有没有可利用的新的图集空间容纳新的字符
这个问题比较好解决,我们在2048*2048的图集上拿出一部分空间作为保留空间先不使用。查找空间时,先查找非保留空间是不有合适位置,再查找是不有可重复利用的废弃空间。如果还没有,再到保留空间里面来添加新字符。 当然有人会说,如果保留空间也被使用完了怎么办(文末有优化方案)?
至此,我们已经分别详述了上面三个方案的可行性,目前看来,只有第三个方案:重复利用废弃字符集能满足要求,而且不会导致内存,drawcall以及其它较大的性能影响。
那么我们接下来解决以上三个问题:
这里,我们以获取字符图集的接口getLetterDefinitionForChar(letter-font.js)为突破口,这个接口是用来查找并添加新的字符,新的查找思路如下:
-
是否已经在当前this._fontDefDictionary._letterDefinitions中存在,存在则直接返回。这是当前的流程中已经有的,保留即可!
-
当前字符图集的安全区是否有足够空间插入新的字符,足够则执行添加新字符的流程。在LetterAtlas中添加字段_safeHeight用于保存当前安全区的图集高度:即2048的高度中有多少是可以随意添加字符集的。这里直接乘以自己设定的比例即可。
具体的查找过程是:
a. 计算新添加的字符的显示高度与宽度。
通过textUtils.safeMeasureText来计算。
b. 在图集的当前游标位置添加新的字符是否能成功(宽度超过2048,或高度超过_safeHeight都算失败)?

c. 能够添加,则走当前的插入新字符的流程。

- 在废弃的字符统计中查找合适的字符大小,如果能找到,则执行废弃字符再复用流程
在letter-font.js中添加字段:
let _unusedLetterList = [];
用于收集已经废弃的字符数组。数组里面存储的是FontLetterDefinition对象。当然FontLetterDefinition对象也需要新加几个字段:
// 字符宽高用于后续被重新复用时判断是否能容纳下新的字符
letter.originW = letterTexture._width;
letter.originH = letterTexture._height;
// hash值是这个TTF字符的唯一标识,由颜色,字号,字体,描边等信息组成
letter.hash = letterTexture._hash;
// 引用计数用于统计当前字符被引用的次数,判断是否是废弃状态
letter.refCount = 0;
查找方法findUnsedLetterFor(char)的逻辑是:
-
判断数组_unusedLetterList是否为空,如果为空则返回null
-
逐个判断废弃字符的originW,originH是否 >= 当前新字符。(后期优化查找效率和命中率的位置就在这里)
-
找到则返回当前的FontLetterDefinition对象,否则返回null。
如果findUnsedLetterFor的返回值不为null,则可以直接调用replaceLetterTexture方法在废弃字符的位置上画上新的字符。
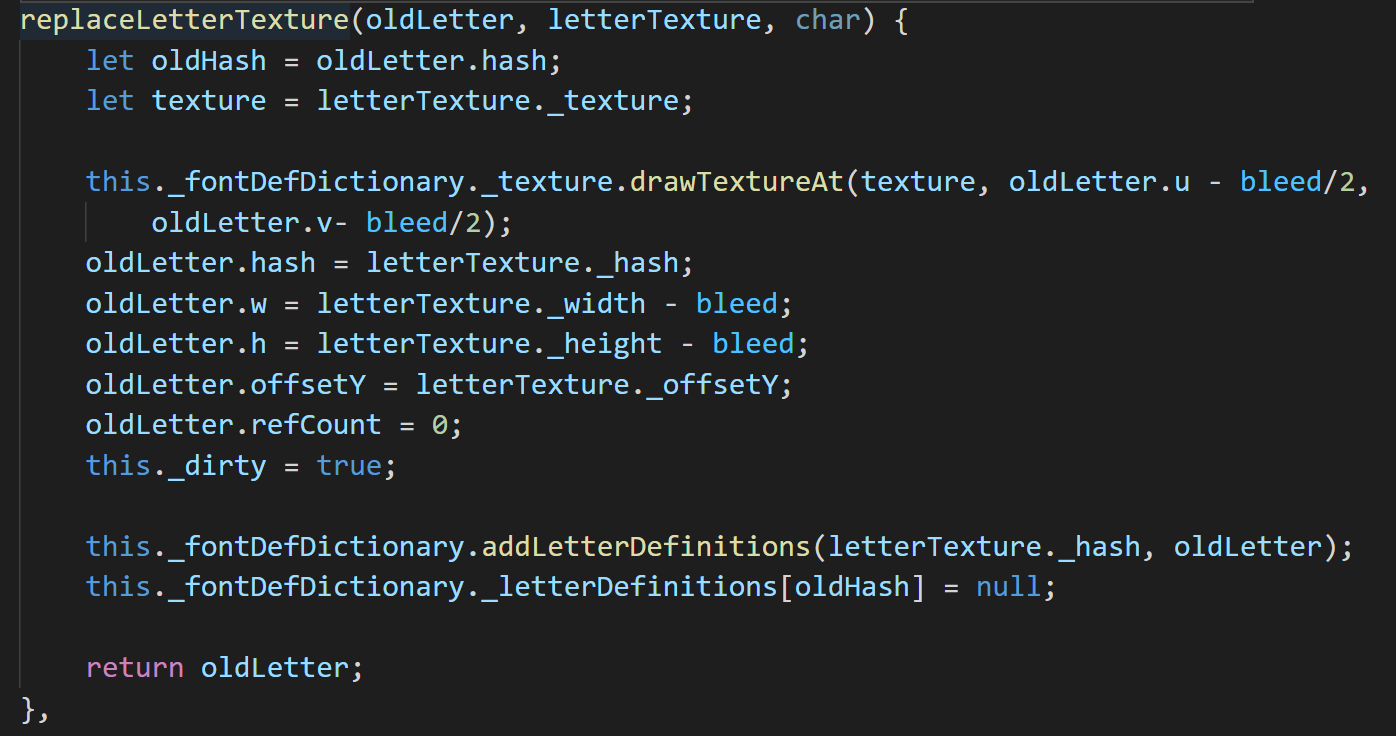
- 在保留区域内判断是否有足够空间添加新字符,如果有,则执行插入流程。
如果执行到这一步,说明新插入的字符大号比较大,前面显示的字符中都未出现过。那么就需要尝试在保留区域内去插入新的字符,这里和前面在安全区内插入字符是同样的过程,不同的是canInsertLabel接口的force参数传入true即可在保留区域内去搜索图集位置。
- 否则报错!
经过以上所有步骤都无法找到合适的图集时,就要报错提醒了。
解决了新字符的添加逻辑后,我们需要处理引用计数的逻辑了,即什么时候加引用计数,什么时候减引用计数。
- 引用增加
字符被使用时增加引用计数,也就是在排版时。即在BmfontAssembler._multilineTextWrap(bmfont.js)方法中。
let destLetter = shareLabelInfo.fontAtlas.getLetterDefinitionForChar( … )
if (destLetter && destLetter.hash) {
// 把当前label引用到的字符添加到引用数组里面,便于执行减引用计数
this._refLetters.push(letterDef.hash)
// 增加引用计数
destLetter.refCount++
}
上面代码中要判断destLetter.hash是否是非空,原因是BMFont和ttf的char模式是走的一套字符显示流程,只是字符图集不同,一个是静态生成好的,一个是动态生成的。而hash值是我们在动态插入字符到字符图集时生成的,因此通过hash为非空可以判断当前是ttf-char文本的显示流程。
- 引用减少
逻辑上应该在label被移除时做引用计数的减少,但是如果一个文本一直在改变 ,那么这个label要记住所有被它显示过的字符,没必要而且太占图集。因此我们简化一下,每次重新渲染前,我们先对当前label引用到的字符做减引用计数,即释放引用。重新渲染时会执行重新排版的流程,这时候再把新显示的文本的字符增加引用,这样就不担心label上的字符的频繁更新了。
具体的释放引用的时机在BmfontAssembler(bmfont.js)类中增加onRecycle接口(重写Assembler的新增同名接口),在这里对_refLetters数组中的对象逐个减引用。
_refLetters这个对象是BmfontAssembler类新加的数组成员。
onRecycle接口的调用时机有两个:
-
BmfontAssembler.updateRenderData: 即重新渲染整个label时,先释放当前引用到的字符。
-
RenderComponent.onDestroy: 即渲染组件被移除时,释放当前引用到的字符。
最后要适配Native平台,还需要做一个修改:
在AssemblerBase类中增加void onRecycle()的空实现,然后做js-binding即可。
最后看下测试Demo,测试代码如下:

Demo功能描述:在一个label上频繁更新大段文本内容,每次都随机设置字号(10-30之间),随机设置颜色。(为便于测试,把文字贴图大小改为1024*1024,安全区为80%)
然后看log,中有无getLetterDefinitionForChar失败的Log, 查看文字图集显示效果如下:

其结果是保留区还有一部分空间。
最后,对上面的这个实现还有可以优化的地方:
如果情况比上面Demo更复杂,这里还有一个可优化空间是,把originH设置为当前行的行高,这样能显著提高重用率。(目前是使用该位置的字符第一次创建时的高度,并没有扩展为当前行高)
还可以选定2个字号,把整张贴图按这两个字号的高度来分块,分别用缩小的方式来显示比自己小的字号文本。这样能更好地复用所有贴图空间。
综上,再次对Label的三种缓存模式做一个总结:
CHAR:改进后的CHAR模式接近"无限"的复用能力,同时不增加Drawcall和贴图图集的消耗。仅多消耗可以忽略不计的内存和CPU消耗。
NONE: 用于显示比较特殊大小的文字,或者几乎不会重用的文字时推荐用NONE模式。
BITMAP: 改进后的BITMAP是可以少量使用的,但是基于其它两种模式的优点来说,BITMAP显得可有可无。(相比于BITMAP可以动态合批到动态图集与其它碎图批渲染,个人更倾向使用CHAR模式让它能跟其它文本合批渲染)
后期预告:论坛中发现一些用户对动态合批有各种使用和效率上的吐槽,基于此,我们后续将推出一篇关于如何优化动态合批的文章,把我们自己的经验分享出来,希望能帮到大家。敬请期待。
关于乐府互娱
乐府互娱成立于2019年,是一家专注于精品移动游戏研发和运营的明星初创企业。
公司核心团队是《少年三国志》《少年西游记》系列作品的原班人马,其中制作人、策划、技术、美术、UI、发行等模块核心成员已共事多年,拥有成熟的研发产品体系和管理体系。
团队长期深耕卡牌手游等品类,具备敏锐的嗅觉和高效的研运能力,以长线游戏研发运营著称,打造过数款月流水过亿的产品,包括《少年三国志》《少年西游记》等,游戏累计流水近100亿元。
公司在成立之初即获得资本市场高度认可,目前已完成天使轮和A轮融资。短期内,乐府将结合自身优势,继续致力于中轻度卡牌手游的深耕细作,保持在该领域的头部地位。
在长期,乐府会重点聚焦于“游戏工业化”之路,在自研自发的前提下,继续打造经典游戏IP。

