
js的版本很多,暂时先不写了
本文重点介绍c++
首先大家要明白 原理都是一样的,cocos从 2dx起 一直以来的 渲染顺序就是 就是 由父类向子类遍历,所以同一个父类是在一级.
但是这是不是符合制作需求?那这个时候问题就来了,尤其是现在的ccc时代,大量的预制体的存在,使得很难像以前一样把所有子类全部放在一个父类下还要同级,当然了,jare也说了 camera,把需要同级对象用同一个group, 放在camera里用同一个depth 放一起, 这样渲染顺序也是可以保证的 不过总好像怪怪的…
那这里就教下大家 如何 c++ 再次对子类 进行分层处理
2.2以后都需要这样处理 本版本基于2.2
首先有4个文件需要修改

nodeproxy是c++node的对应类,主要存放了node 的属性,后期渲染 就是用的这里的属性
首先 我们 看下 我们魔改的 源码
void NodeProxy::getBatchChildern(cocos2d::Vector<NodeProxy*> &batchChildren, NodeProxy* node)
{
batchChildren.pushBack(node);
for (const auto& child : node->_children)
{
getBatchChildern(batchChildren, child);
}
}
/////////////////////////////////////////
void NodeProxy::render(NodeProxy* node, ModelBatcher* batcher, Scene* scene)
{
if (!node->_needVisit || node->_realOpacity == 0) return;
bool needRender = *node->_dirty & RenderFlow::RENDER; if (node->_needRender != needRender) { if (node->_assembler) node->_assembler->enableDirty(AssemblerBase::VERTICES_OPACITY_CHANGED); node->_needRender = needRender; } // pre render if (node->_assembler && needRender) node->_assembler->handle(node, batcher, scene);
node->reorderChildren();
if (node->_isAutoBatch)
{
cocos2d::Vector<NodeProxy*> batchChildren;
for (const auto& child : node->_children)
{
getBatchChildern(batchChildren, child);
}
#if CC_64BITS
std::sort(std::begin(batchChildren), std::end(batchChildren), [](NodeProxy* n1, NodeProxy* n2) {
return (n1->_autoRenderLevel < n2->_autoRenderLevel);
});
#else
std::stable_sort(std::begin(batchChildren), std::end(batchChildren), [](NodeProxy* n1, NodeProxy* n2) {
return n1->_autoRenderLevel < n2->_autoRenderLevel;
});
#endif
for (const auto& child : batchChildren) {
child->closeRenderChild();
auto traverseHandle = child->traverseHandle;
traverseHandle(child, batcher, scene);
}
}
else {
if (node->_isRenderChild)
{
for (const auto& child : node->_children)
{
auto traverseHandle = child->traverseHandle;
traverseHandle(child, batcher, scene);
}
}
}
// post render
bool needPostRender = *(node->_dirty) & RenderFlow::POST_RENDER;
if (node->_assembler && needPostRender) node->_assembler->postHandle(node, batcher, scene);
}
这里的代码意思很简单 就是对node的子类进行排序,改变渲染顺序
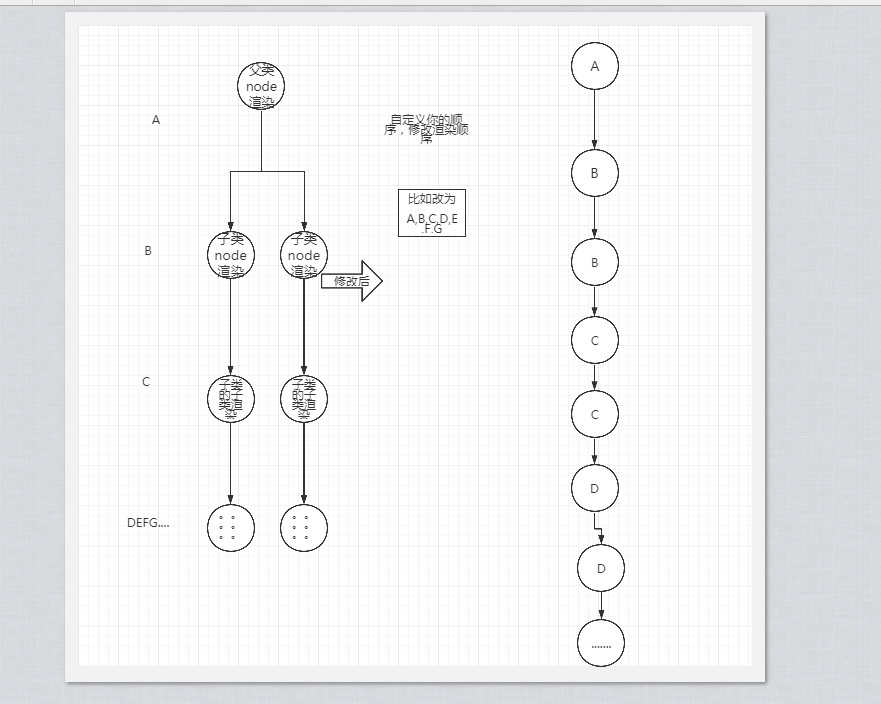
改完 注册号相应的c++类就可以了 晚点 上demo
2020/07/10
返回
github 宕机…码云炸了…尴尬…demo已经 更新 就是没反应…
camera 分层 渲染的方法 实测 是不行的哦
