
使用版本: Cocos Creator 2.4.0
写了一个非常简单的伪·加解密Label字符串的拓展组件(2.4.0)[分享]
源: 最近在研究加解密存档,但是觉得实在太麻烦
诞生: 这两天写了个非常Low的加解密Label组件里面的字符串的拓展组件,
- 需要的朋友,可以研究下,如果有更好的建议,欢迎提议,感谢
个人写的–非常Low的加解密Label组件演示
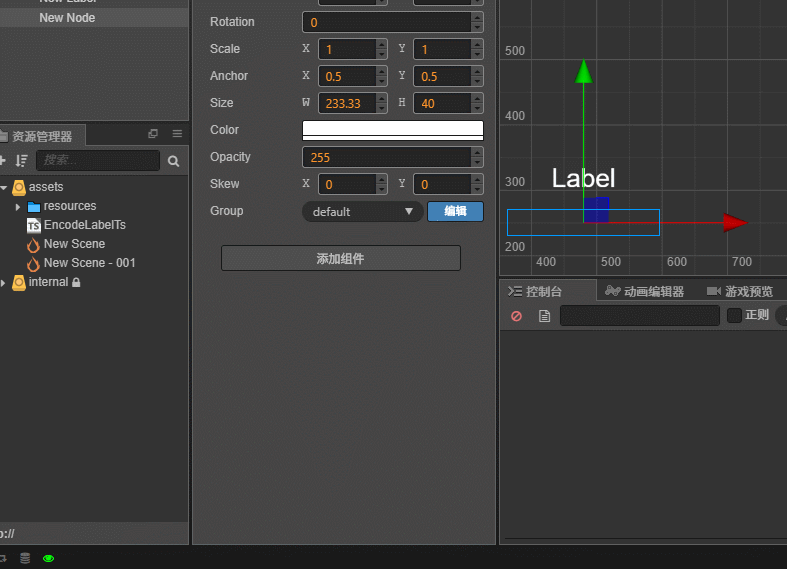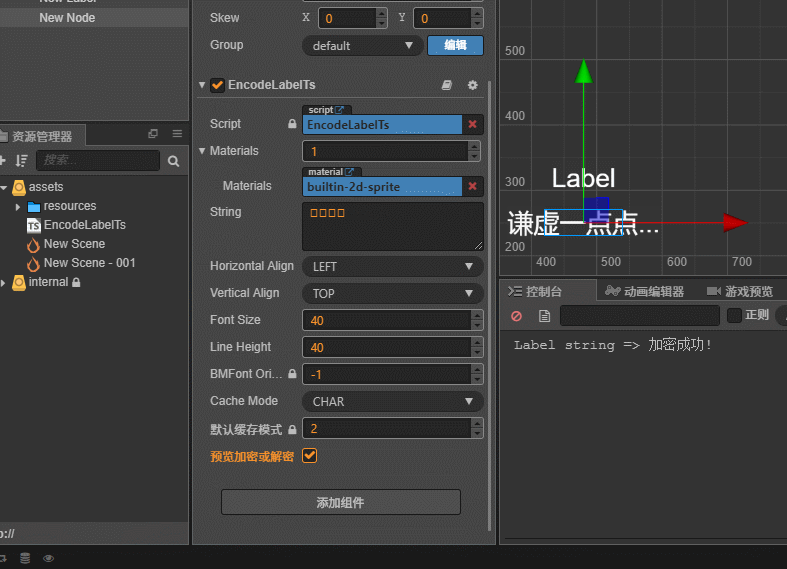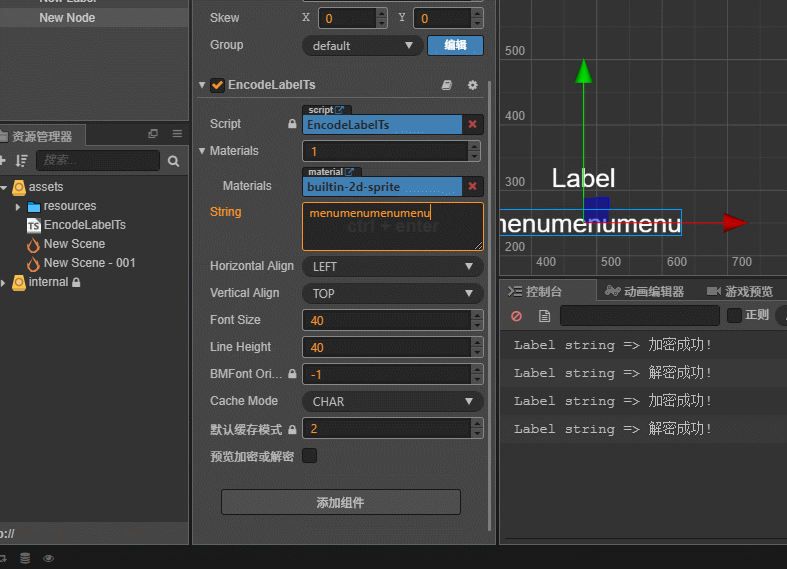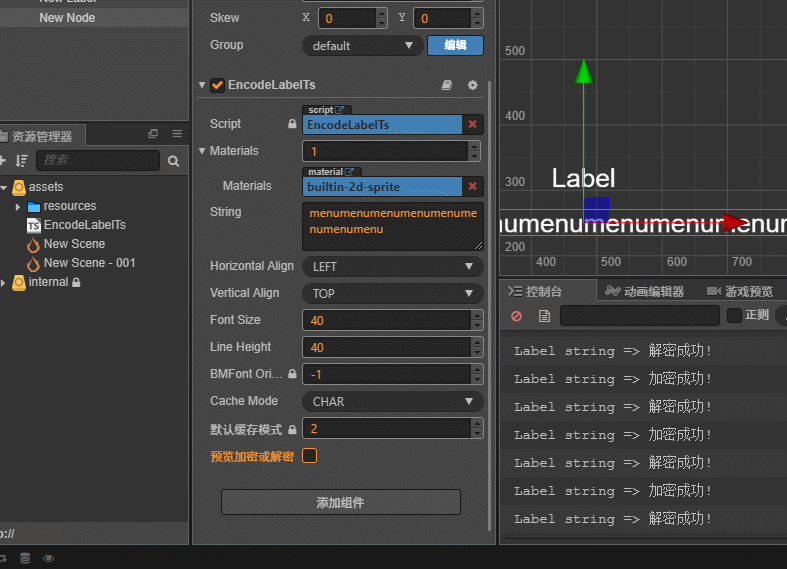
Ts文件:
EncodeLabelTs.zip (4.1 KB)
大家如果想定制自己的组件的属性面板,可以参考这个文章::
CCClass 中属性 property 属性参数的一点理解
Ts源码:
const { ccclass, property, menu, executeInEditMode, requireComponent, playOnFocus } = cc._decorator;
// 加密解密选项::
export enum EnDecodeType {
encodeStr_加密 = 0,
decodeBuf_解密 = 1
};
@ccclass
@menu("加密解密Label")
// @executeInEditMode
// @playOnFocus
export class EncodeLabelTs extends cc.Label {
@property({ displayName: "默认缓存模式", tooltip: "Label默认使用 CHAR 缓存\n可以增加字符串长度\n无法渲染使用特殊自定义的文本格式(不常见字符)\n不能参与动态合图!", readonly: true })
public defaultCacheMode: cc.Label.CacheMode = cc.Label.CacheMode.CHAR;
@property({ displayName: "预览加密或解密", tooltip: "在 Cocos 内预览加密或解密Label内容\n默认关闭预览=>自动加密\n加解密只进行一次!" })
public previewEnDecodeLabel: boolean = false;
@property({ displayName: "加密或解密", type: cc.Enum(EnDecodeType), tooltip: "encodeStr_加密=字符串加密成buffer\nencodeStr_加密=buffer解密成字符串", readonly: true, visible: false })
EnDecodeSelect: EnDecodeType = EnDecodeType.encodeStr_加密;
// 判断加密或者解密的选项:::=>
// @property({displayName:'加解密主要组件代码',type:cc.Component,tooltip:'加解密主要组件代码'})
// @property({ displayName: '加解密组件', tooltip: '加解密主要组件代码' })
// getStrToBufComp: StringToBufferStart = new StringToBufferStart();
// getStrToBufComp: any = new StringToBufferStart();
tempLabelString: string = "";
endDecodeRebackStr: string = "";
tempEnDecodeSelect: any = null;
strlength: number = 0;
reflashUpdateNum: number = 77;
// LIFE-CYCLE CALLBACKS:
onLoad(): void {
this.string = "谦虚一点点...";
this.cacheMode = cc.Label.CacheMode.CHAR;
this.tempEnDecodeSelect = this.EnDecodeSelect;
this.EnDecodeSelect = EnDecodeType.encodeStr_加密;
// this.tempLabelString = this.string;
};
start(): void {
// 合批加载::
this.string = "谦虚一点点...";
this.cacheMode = cc.Label.CacheMode.CHAR;
this.tempLabelString = this.string;
};
update(dt: number): void {
if (new Date().getMilliseconds() > this.reflashUpdateNum) {
if (this.previewEnDecodeLabel) {
this.previewEnDecodeLabel = false;
// this.tempLabelString = this.string;
this.tempEnDecodeSelect = this.EnDecodeSelect;
if (this.EnDecodeSelect != EnDecodeType.encodeStr_加密) {
this.EnDecodeSelect = EnDecodeType.encodeStr_加密;
if (Editor) {
Editor.log("Label string => 解密成功!");
} else {
cc.log("Label string => 解密成功!");
};
} else {
this.EnDecodeSelect = EnDecodeType.decodeBuf_解密;
if (Editor) {
Editor.log("Label string => 加密成功!");
} else {
cc.log("Label string => 加密成功!");
};
};
this.En_De_codeStr(this.string);
};
};
};
/**
* @description: 加密或者解密字符串(包含中文,英文加密,加密后密文长度较小)
*/
public En_De_codeStr(strOrData: any): void {
if (this.tempEnDecodeSelect == EnDecodeType.encodeStr_加密) {
this.string = this.En_codeStr(strOrData);
} else {
this.string = this.De_codeBuf(strOrData);
};
return null;
};
public En_codeStr(strDatas: string): any {
// this.string = "谦虚𝌆𝌆";
let getStrToBufComp = new StringToBufferStart();
this.strlength = getStrToBufComp.push_StringWithUtf8(strDatas);
// 十六进制的字符串
let endRebackCont_HEX = null;
// getStrToBufComp.to_String32() || getStrToBufComp.to_String16();
let endRebackCont_TenArr = this.newto_String16To10(strDatas);
let getNewArrBuf = new Uint8Array(endRebackCont_TenArr);
let endRebackStr = this.dUb_Uint8ArrayToString(getNewArrBuf);
endRebackCont_HEX = endRebackStr;
// cc.log('Editor En_codeStr=strDatas>', [strDatas]);
// let endRebackCont_Ten = getStrToBufComp.to_String16To10(endRebackCont_HEX);
this.endDecodeRebackStr = getStrToBufComp.get_StringWithUtf8(this.strlength);
// URI编码的字符串
// let endRebackCont_URI = encodeURI(strDatas);
return endRebackCont_HEX;
};
public De_codeBuf(strDatas: any): any {
return this.endDecodeRebackStr;
};
public newto_String16To10(endRebackCont_HEX: any): any {
let result = [], tempShowHex = "";
let tempArrHex = endRebackCont_HEX.split("");
for (let i = 0; i < tempArrHex.length; i += 2) {
// (Number("0xe8")).valueOf(16);
tempShowHex = "0x" + tempArrHex[i] + tempArrHex[i + 1];
result.push(Number((Number(tempShowHex)).toString(10)));
};
return result;
};
public dUb_stringToUint8Array(str: any): Uint8Array {
var arr = [];
for (var i = 0, j = str.length; i < j; ++i) {
arr.push(str.charCodeAt(i));
};
var tmpUint8Array = new Uint8Array(arr);
return tmpUint8Array;
};
public dUb_Uint8ArrayToString(fileData: any): string {
var dataString = "";
for (var i = 0; i < fileData.length; i++) {
dataString += String.fromCharCode(fileData[i]);
};
return dataString;
};
};
interface UnicodeIsnOk {
unicode?: number
ok: boolean
};
interface UnicodeLength {
unicode?: number
len: number
};
export class StringToBufferStart {
bufferDataArr: number[];//uint8array
private readOffset: number;
constructor() {
this.bufferDataArr = [];
this.readOffset = 0;
}
initWith_Uint8Array(array: ArrayLike<number>, len?: number) {
len = len || array.length;
this.bufferDataArr = [];
for (let i = 0; i < len && i < array.length; i++)
this.bufferDataArr[i] = array[i];
this.readOffset = 0;
}
get_Uint8Array(): number {
if (this.readOffset + 1 > this.bufferDataArr.length)
return null;
return this.bufferDataArr[this.readOffset++];
}
push_Uint8Array(value: number): void {
if (value > 255)
throw Error("StringToBufferStart pushUint8 value need <= 255");
this.bufferDataArr.push(value);
}
get_Uint16Array(): number {
if (this.readOffset + 2 > this.bufferDataArr.length)
return null;
let uint1 = this.get_Uint8Array();
let uint2 = this.get_Uint8Array();
return (uint1 << 8) | uint2;
}
push_Uint16Array(value: number): void {
this.push_Uint8Array((value >> 8) & 0xFF);
this.push_Uint8Array(value & 0xFF);
}
get_Uint32Array(): number {
/*js的位运算仅限在4字节32位。如果想要扩展到8字节64位,那么只能用乘除加减的方法。*/
if (this.readOffset + 4 > this.bufferDataArr.length)
return null;
let uint1 = this.get_Uint16Array();
let uint2 = this.get_Uint16Array();
return uint1 * 65536 + uint2;
}
push_Uint32Array(value: number): void {
this.push_Uint16Array((value >> 16) & 0xFFFF);
this.push_Uint16Array(value & 0xFFFF);
}
get_Int64Ar(): number {
let hi = this.get_Uint32Array();
let lo = this.get_Uint32Array();
if (hi >> 31 == 1)
return -(hi * 4294967296 + lo);
return hi * 4294967296 + lo;
}
push_UnicodeWithUtf8(value: number): void {
if (value <= 0x7F) {
this.push_Uint8Array(value);
} else if (value <= 0xFF) {
this.push_Uint8Array((value >> 6) | 0xC0);
this.push_Uint8Array((value & 0x3F) | 0x80);
} else if (value <= 0xFFFF) {
this.push_Uint8Array((value >> 12) | 0xE0);
this.push_Uint8Array(((value >> 6) & 0x3F) | 0x80);
this.push_Uint8Array((value & 0x3F) | 0x80);
} else if (value <= 0x1FFFFF) {
this.push_Uint8Array((value >> 18) | 0xF0);
this.push_Uint8Array(((value >> 12) & 0x3F) | 0x80);
this.push_Uint8Array(((value >> 6) & 0x3F) | 0x80);
this.push_Uint8Array((value & 0x3F) | 0x80);
} else if (value <= 0x3FFFFFF) {//后面两种情况一般不大接触到,看了下protobuf.js中的utf8,他没去实现
this.push_Uint8Array((value >> 24) | 0xF8);
this.push_Uint8Array(((value >> 18) & 0x3F) | 0x80);
this.push_Uint8Array(((value >> 12) & 0x3F) | 0x80);
this.push_Uint8Array(((value >> 6) & 0x3F) | 0x80);
this.push_Uint8Array((value & 0x3F) | 0x80);
} else {//Math.pow(2, 32) - 1
this.push_Uint8Array((value >> 30) & 0x1 | 0xFC);
this.push_Uint8Array(((value >> 24) & 0x3F) | 0x80);
this.push_Uint8Array(((value >> 18) & 0x3F) | 0x80);
this.push_Uint8Array(((value >> 12) & 0x3F) | 0x80);
this.push_Uint8Array(((value >> 6) & 0x3F) | 0x80);
this.push_Uint8Array((value & 0x3F) | 0x80);
}
}
get_UnicodeWithUtf8(): UnicodeLength {
let result;
let start = this.get_Uint8Array();
if (start == null)
return null;
let n = 7;
while (((start >> n) & 1) == 1)
n--;
n = 7 - n;
if (n == 0)
result = start;
else
result = start & (Math.pow(2, 7 - n) - 1);
for (let i = 1; i < n; i++) {
let follow = this.get_Uint8Array();
if ((follow & 0x80) == 0x80) {
result = result << 6 | (follow & 0x3F);
} else {
//不是标准的UTF8字符串 直接取第一个。
result = start;
this.change_ReadOffset(1 - n);
n = 0;
break;
}
}
return { unicode: result, len: n == 0 ? 1 : n };
}
parse_UnicodeFromUtf16(ch1: number, ch2: number): UnicodeIsnOk {
if ((ch1 & 0xFC00) === 0xD800 && (ch2 & 0xFC00) === 0xDC00) {
return { unicode: (((ch1 & 0x3FF) << 10) | (ch2 & 0x3FF)) + 0x10000, ok: true }
}
return { ok: false }
}
push_StringWithUtf8(value: string): number {
let oldlen = this.bufferDataArr.length;
for (let i = 0; i < value.length; i++) {
let ch1 = value.charCodeAt(i);
if (ch1 < 128)
this.push_UnicodeWithUtf8(ch1);
else if (ch1 < 2048) {
this.push_UnicodeWithUtf8(ch1);
} else {
let ch2 = value.charCodeAt(i + 1);
let UnicodeIsnOk = this.parse_UnicodeFromUtf16(ch1, ch2);
if (UnicodeIsnOk.ok) {
this.push_UnicodeWithUtf8(UnicodeIsnOk.unicode);
i++;
} else {
this.push_UnicodeWithUtf8(ch1);
}
}
}
return this.bufferDataArr.length - oldlen;
}
get_StringWithUtf8(len: number): string {
if (len < 1)
return "";
if (this.readOffset + len > this.bufferDataArr.length)
return "";
let str = "";
let read = 0;
while (read < len) {
let UnicodeLength = this.get_UnicodeWithUtf8();
if (!UnicodeLength) {
break;
}
read += UnicodeLength.len;
if (UnicodeLength.unicode < 0x10000) {
str += String.fromCharCode(UnicodeLength.unicode);
} else {
let minus = UnicodeLength.unicode - 0x10000;
let ch1 = (minus >> 10) | 0xD800;
let ch2 = (minus & 0x3FF) | 0xDC00;
str += String.fromCharCode(ch1, ch2)
}
}
return str;
}
push_StringWithUtf16(value: string): number {
let oldlen = this.bufferDataArr.length;
for (let i = 0; i < value.length; i++) {
let ch = value[i].charCodeAt(0);
this.push_Uint16Array(ch);
}
return this.bufferDataArr.length - oldlen;
}
get_StringWithUtf16(len: number): string {
if (len < 1)
return "";
if (this.readOffset + len > this.bufferDataArr.length || len % 2 != 0)
return "";
let str = "";
for (let i = 0; i < len; i += 2) {
let ch1 = this.get_Uint16Array();
let ch2 = this.get_Uint16Array();
str += String.fromCharCode(ch1, ch2);
}
return str;
}
push_Uint8List(val: ArrayLike<number>) {
for (let i = 0; i < val.length; i++)
this.push_Uint8Array(val[i]);
}
get_Uint8List(len?: number): Uint8Array {
len = len || this.bufferDataArr.length;
return new Uint8Array(this.bufferDataArr.slice(this.readOffset, this.readOffset + len));
}
to_String16(): string {
let result = "";
for (let i = 0; i < this.bufferDataArr.length; i++) {
let ch = this.bufferDataArr[i].toString(16);
result += ch.length == 1 ? "0" + ch.toUpperCase() : ch.toUpperCase();
}
return result;
}
to_String32(): string {
let result = "";
for (let i = 0; i < this.bufferDataArr.length; i++) {
let ch = this.bufferDataArr[i].toString(32);
result += ch.length == 1 ? "0" + ch.toUpperCase() : ch.toUpperCase();
}
return result;
}
to_String16To10(endRebackCont_HEX: any): any {
let result = [], tempShowHex = "";
let tempArrHex = endRebackCont_HEX.split("");
for (let i = 0; i < tempArrHex.length; i += 2) {
// (Number("0xe8")).valueOf(16);
tempShowHex = "0x" + tempArrHex[i] + tempArrHex[i + 1];
// result += ch.length == 1 ? "0" + ch.toUpperCase() : ch.toUpperCase();
result.push(Number((Number(tempShowHex)).toString(10)));
};
return result;
};
to_Uint8Array(): Uint8Array {
let array = new Uint8Array(this.bufferDataArr.length);
for (let i = 0; i < this.bufferDataArr.length; i++)
array[i] = this.bufferDataArr[i];
return array;
}
change_ReadOffset(len: number) {
this.readOffset = Math.max(0, Math.min(this.bufferDataArr.length, this.readOffset + len))
}
};
// @ts-ignore
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'srcBlendFactor', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'dstBlendFactor', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'actualFontSize', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'fontFamily', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'overflow', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'enableWrapText', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'font', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'useSystemFont', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'BMFontOriginalSize', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'spacingX', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'cacheMode', 'visible', true);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'enableBold', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'enableItalic', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'enableUnderline', 'visible', false);
// @ts-ignore
cc.Class.Attr.setClassAttr(EncodeLabelTs, 'underlineHeight', 'visible', false);
module.exports = EncodeLabelTs;




 您看有更好的优化方式吗?
您看有更好的优化方式吗?