
前言
前段时间在找工作,从好友那打听到一题很不错的面试题:“一张图片从加载到显示的过程中发生了什么?”
当下觉得真是一道好题,覆盖面之广… 只觉得背后一凉,要是问到就当场交代了吧…
本着求知(职)的精神,当然是不能放过这么好的题目,努努力折腾了出来 (再不写要开始上班了…)(再不写要赶版本了…)。
本文把这整个流程分为“加载”、“渲染数据生成”、“渲染”三部分。
图文并茂,争取把东西说得更直白一些。
不过为了避免越写越多… 本文没有完全深入细节,因此,还需要了解相关的基础知识哦
进入正题吧!
一、加载
显示图片的第一步,当然是要先得到图片。
图片的加载分为静态引用和动态加载两种情况。
静态引用时,Cocos会解析出界面依赖的资源,在界面资源加载完成后,通过loadDepends函数,为所有依赖资源创建加载任务(task)经由管线(pipeline.async)进行加载。
动态加载时,我们通过cc.resources.load、cc.assetManager.loadAny等函数进行加载。cocos一样会创建加载任务(task)经由管线(pipeline.async)进行加载。
殊途同归,最终都回到了pipeline.async。pipeline指的是Cocos在引擎中定义的通用加载管线(Pipeline对象实例)。async是异步执行该任务的函数。
让我们来看看这个加载管线!
1. 加载管线
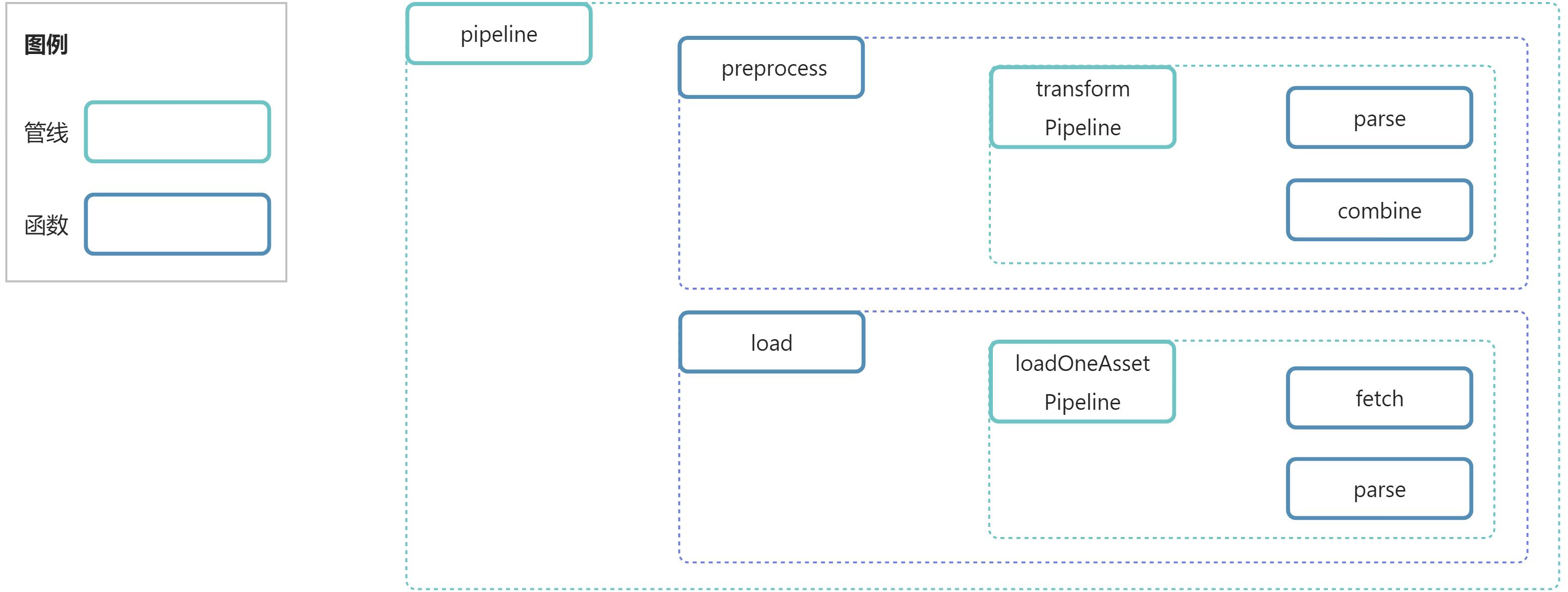
加载管线(上面提到的pipeline)包含preprocess和load两个步骤(函数)。
1.1 preprocesspreprocess函数中包含preprocess自身的逻辑,和transformPipeline子管线。transformPipeline又包含了parse和combine两个步骤。
1.2 load
和preprocess类似,load函数中包含load自身的逻辑,和loadOneAssetPipeline子管线。loadOneAssetPipeline又包含了fetch和parse两个步骤。
有点乱套了?看看图
2. 功能介绍
这么多管线和步骤,它们都是干嘛的呢?
注:Cocos的Task支持一次加载多个文件,因此过程中的RequestItem等对象都使用数组进行了兼容。
2.1 pipeline
Pipeline对象,声明于shared.js(cocos2d\core\asset-manager\shared.js),初始化于CCAssetManager.js(cocos2d\core\asset-manager\CCAssetManager.js)。
加载管线,这一切的入口。串联执行preprocess和load函数。
2.2 preprocess
函数,pipeline管线的第1个步骤。声明于preprocess.js(cocos2d\core\asset-manager\preprocess.js)。
预处理加载任务,将输入的Task转换为RequestItem数组。
本身的工作是处理参数,重要的是调用transformPipeline管线,RequestItem就是transformPipeline管线处理后返回的结果。
2.2.1 transformPipeline
Pipeline对象,声明于shared.js(cocos2d\core\asset-manager\shared.js),初始化于CCAssetManager.js(cocos2d\core\asset-manager\CCAssetManager.js)。
路径转换管线。串联执行parse和combine函数。负责将Task转换为RequestItem数组。
2.2.1.1 parse
函数,transformPipeline的第1个步骤。声明于urlTransformer.js(cocos2d\core\asset-manager\urlTransformer.js)。
获取资源信息,将Task转换为RequestItem数组,作为combine函数的参数。
2.2.1.2 combine
函数,transformPipeline的第2个步骤,声明于urlTransformer.js(cocos2d\core\asset-manager\urlTransformer.js)。
基于parse函数处理结果(RequestItem数组)中的信息,组装出完整的资源路径,路径仍然放在RequestItem对象中。
2.3 load
函数,pipeline管线的第2个步骤。声明于load.js(cocos2d\core\asset-manager\load.js)。
主要逻辑是调用loadOneAssetPipeline管线,加载所有的RequestItem。
2.3.1 loadOneAssetPipeline
Pipeline对象,声明并初始化于load.js(cocos2d\core\asset-manager\load.js)。
加载单个资源管线。串联执行fetch和parse函数。负责加载并解析资源文件。
2.3.1.1 fetch
函数,loadOneAssetPipeline管线的第1个步骤。与loadOneAssetPipeline一起声明。
通过packManager.load函数加载文件。packManager是处理打包资源的辅助类,包含加载、缓存等,定义于cocos2d\core\asset-manager\pack-manager.js。
加载再深入一层是downloader.download函数,downloader是用来下载资源的辅助类,会根据不同的资源类型调用不同的下载方式。定义于cocos2d\core\asset-manager\downloader.js。
图片会通过downloadBlob函数进行下载。
再深入一层,是downloadFile函数,定义于cocos2d\core\asset-manager\download-file.js。downloadFile函数(网页环境下)本质上是通过XMLHttpRequest来实现文件的下载的。到此为止 就不深入了啊…  。
。
2.3.1.2 parse
函数,loadOneAssetPipeline管线的第2个步骤。与loadOneAssetPipeline一起声明。
通过parser.parse函数将fetch函数下载到的资源解析为对应的资源对象。parser定义于cocos2d\core\asset-manager\parser.js。parser函数中,根据不同文件类型,定义了多种解析函数,比如图片使用parseImage函数,可以将Blob数据转换为ImageBitmap对象。
另外,parser函数中对非原生资源还会调用loadDepends函数,加载其依赖项(比如SpriteFrame的依赖项是Texture)。
在依赖项加载完成后,会自动调用对应的set函数,如SpriteFrame._textureSetter。
加载流程
看完功能介绍还是挺乱?不要急,这里用“加载静态引用的SpriteFrame”的例子带你看懂!
前面提到过,不论是静态引用,还是动态加载,都会变成Task进入加载流程,区别并不大。
静态引用时,Task的输入(input)是uuid(prefab中记录着每个引用资源的uuid)。
动态加载时,Task的输入(input)是文件路径(代码运行时调用load传递的参数)。
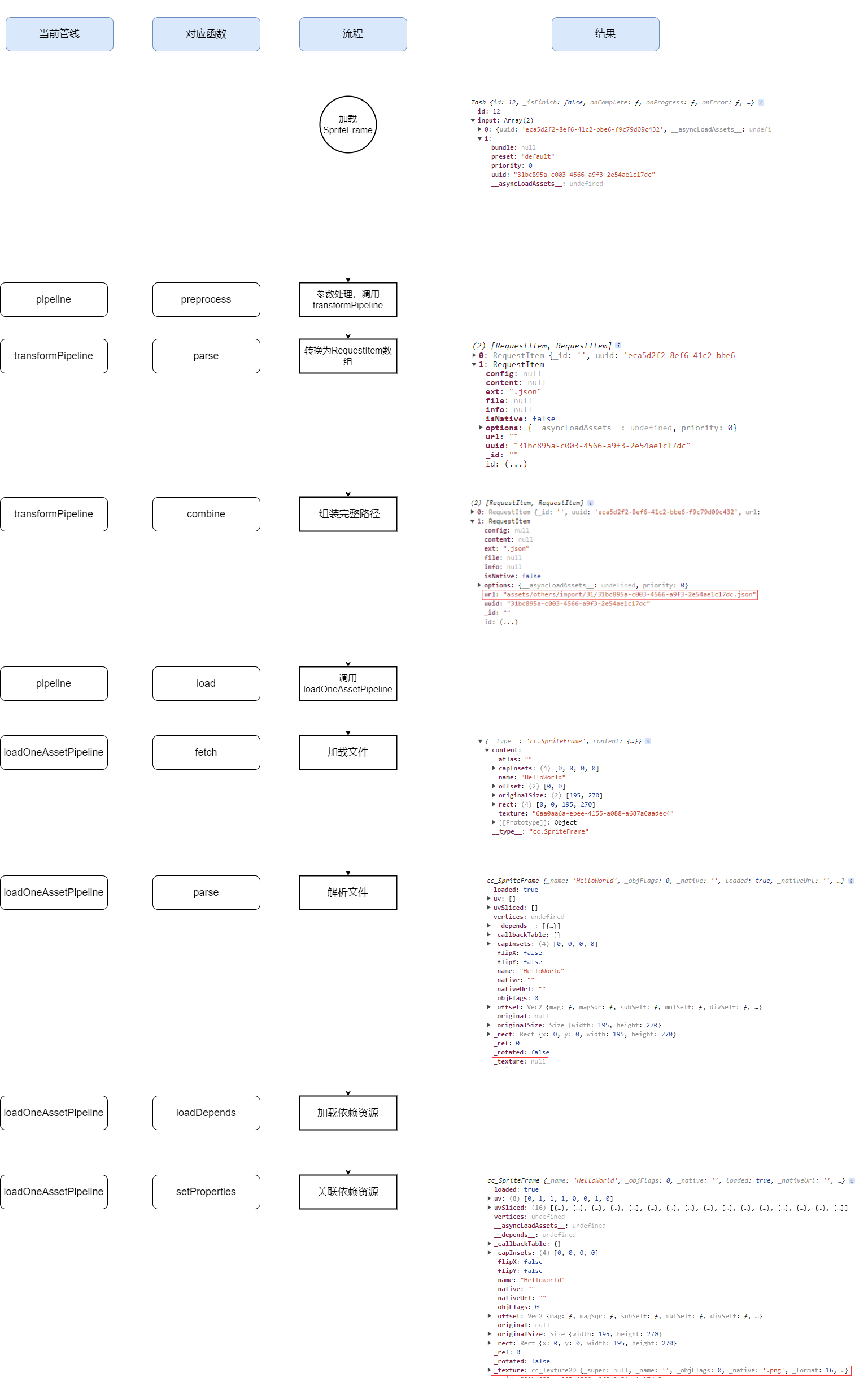
现在我们已经能在代码中访问这张图片了!
二、数据转换
显示图片的第二步,需要将图片的相关数据转换成GPU能够理解的格式,才能提交给GPU进行渲染。
那GPU都需要哪些数据呢?
换个思路,如果我们想要画画,我们需要知道什么?
画什么?怎么画(漫画/写实/抽象)?画哪里?
画什么:纹理
怎么画:材质(shader)、顶点数据…
画哪里:坐标
让我们来挨个看它们是怎么产生的!
画什么
画画总要找个参考物吧,在渲染中就是纹理啦。纹理虽然存储在SpriteFrame中,但渲染时其实是通过材质传递给GPU的。
回到上一小节的最后,当图片加载完成后,会通过SpriteFrame的_textureSetter函数,设置SpriteFrame的纹理属性(_texture)。
跟踪一下调用栈,顺序是_textureSetter -> _refreshTexture。
在Sprite中,spriteFrame的set函数会调用_applySpriteFrame函数,进而更新材质中的纹理。
调用栈是_applySpriteFrame -> _updateMaterial -> material.setProperty
其中最关键的代码是material.setProperty('texture', texture);这样就把SpriteFrame的纹理给到了材质。
那材质是怎么把纹理给到GPU的呢?
材质(Material)的属性会传递给Effect,Effect又会把属性传递给Pass。
调用栈是material.setProperty -> effect.setProperty -> effect._setPassProperty -> pass.setProperty
在提交渲染数据时(base-renderer._draw),会从pass中获取声明的所有uniform参数(纹理),传递给device。
调用栈是base-renderer._draw -> base-renderer._setProperty -> device.setTexture
随后,进入device.draw函数中,在这里,会进行顶点数据、纹理等内容的提交,我们暂时只关心纹理的部分。
调用栈是base-renderer._draw -> device.draw -> _commitTextures -> gl.bindTexture
就这样,我们的纹理从SpriteFrame中,一层一层地传递,最后通过gl.activeTexture和gl.bindTexture函数将对应的纹理数据提交给GPU。
注:纹理对象会在GPU中缓存,所以最后传递给GPU的时候,只需要传递Texture2D的_glID属性就可以了。
怎么画
2.1 材质
这里的材质主要指shader及其参数。纹理作为参数之一,在前面已经单独说过了。
与提交纹理的逻辑类似,同样在提交渲染数据时(base-renderer._draw),会根据当前pass的_programName属性,通过programLib.getProgram函数得到Program实例。
Program实例中包含了顶点着色器和片元着色器的代码、声明的属性等信息,在创建时会提交给GPU。
在device.draw函数中,如果Program发生了切换,就会自动更新Program。
Program也会在GPU中缓存,所以只需要通过gl.useProgram(program._glID),就可以实现指定。
2.2 顶点数据
来到大家熟悉的部分了。顶点数据,一般包含渲染坐标、纹理坐标、颜色数据。
为什么会把顶点数据放到“手法”这个分类下呢?
一般情况下我们不太会直接改顶点数据。比如颜色,我们会通过节点的颜色间接调整。那其他的部分呢?
说个常见的,九宫格图片,其实就是通过顶点数据实现的。一般的图片只需要6个顶点,但九宫格图片,需要16个顶点。通过把一张图片拆分成多个部分(更多的顶点数据)的方式,实现了图片的拉伸渲染。
通过顶点数据也可以实现翻转、旋转、缩放等效果,这么看就能跟“手法”搭上边了吧?
不同渲染组件的顶点数据缓存、提交方式不太一样。
Sprite一般情况下数据保持不变,所以Cocos帮我们做了缓存,只有位置等属性发生变更才会刷新。
Spine其中的图片可能频繁发生缩放、位移,因此顶点数据会实时计算(根据选的缓存方式)。
数据首先要提交给Cocos,进行相关的处理。
调用栈:CCDirector.mainLoop -> renderer.render -> RenderFlow.render -> RenderFlow.visitRootNode -> RenderFlow._children -> RenderFlow._render -> Assembler2D.fillBuffers
有点长。简单理解可以是,Cocos每帧都会通过comp._assembler.fillBuffers函数来让所有渲染组件进行数据提交。
最后的Assembler2D是普通Sprite对应的Assembler类SimpleSpriteAssembler的父类,渲染组件不同,对应的类可能不同。
visitRootNode函数执行时,如果节点的坐标、颜色、顶点数据等内容发生了变更,会调用对应的更新函数。fillBuffers函数中,会将数据存入缓存(buffer)中,一般是MeshBuffer(cocos2d\core\renderer\webgl\mesh-buffer.js)。
接着是Cocos将数据提交给渲染引擎。
当合批被打断或者全部渲染组件提交完成后,会通过ModelBatcher._flush函数将缓存(buffer)中的数据转存为Model(cocos2d\renderer\scene\model.js),Model被Scene持有(渲染场景,非cc.Scene。定义于cocos2d\renderer\scene\scene.js)。
Model中持有的顶点数据是一个引用,并不包含实际的数据,提交渲染时,和图片一样,通过glID进行引用。
所有渲染组件的数据提交之后,Cocos会将所有Model(即_buffer)上传,此时顶点数据和索引数据才真正地被交给GPU。
好像也没有那么复杂?来上点强度 。
。
2.3 最后但很 重 要
我们开发过程中还有很多内容,它们都可以轻易改变渲染结果,比如摄像机、节点顺序、Mask…
因此,Cocos还需要再做亿点点处理,才能将这些绘制的需求提交给GPU,完成渲染。
在这个过程中会出现非常多辅助类,有些在前面提到过,总结整理一下(原生和Web有些类不一样,这里用Web说明):
| 类 | 作用 | 路径 |
|---|---|---|
| ModelBatcher | 管理Model的辅助类,还有顶点数据buffer的辅助函数,只有1个。 | cocos2d\core\renderer\webgl\model-batcher.js |
| Model | 每个Model对应1个同批次的数据,持有顶点数据(InputAssembler)、Effect等。 | cocos2d\renderer\scene\model.js |
| Scene | 渲染场景,只有1个。和游戏里用的cc.Scene不是一个东西。 | cocos2d\core\renderer\index.js |
| View | 视图,和相机一一对应,用来保存相机的depth、clearFlags、renderStages等信息。 | cocos2d\renderer\core\view.js |
| DrawItem | 和Model一一对应,用来保存Model中的信息。这个类没有类声明。 | cocos2d\renderer\core\base-renderer.js |
| StageInfo | 和view._stages列表项一一对应,持有对应的StageItem数组,和stage。这个类没有类声明。 | cocos2d\renderer\core\base-renderer.js |
| StageItem | 可以进行渲染的最终对象。DrawItem和view._stages一一配对组合出的对象,保存DrawItem中的信息,和对应的渲染passes。这个类没有类声明。 | cocos2d\renderer\core\base-renderer.js |
回到代码。先拉高层级,看看Cocos提交数据的完整流程(后续内容配合下方的流程图食用更佳)。
调用栈:CCDirector.mainLoop -> renderer.render -> RenderFlow.render -> ForwardRenderer.render -> base-renderer._render -> ForwardRenderer._opaqueStage -> ForwardRenderer._drawItems-> ForwardRenderer._draw
也有点长,前三个函数和前面说过的一样,都是主循环中调用渲染的逻辑。后面的步骤中,数据还会经过多次处理,才最终要求GPU进行绘制。
ForwardRenderer.render函数中,会将Scene中的每个相机的信息进行提取,转为View。随后,调用_render 函数(声明于父类base-renderer)对每个View进行渲染。
base-renderer._render函数中,会遍历Scene中的所有Model,筛选_cullingMask与View匹配的Model,将 其中的数据提取到DrawItem,放入_drawItemsPools。DrawItem包含顶点数据引用、effect、材质uniform变量等。
之后,根据view._stages,再遍历_drawItemsPools中的所有item,组合成stage+item的StageItem。StageItem会根据stage分组为StageInfo,StageInfo存放于_stageInfos属性中。
在所有DrawItem完成分组之后,对_stageInfos进行遍历,调用stage对应的渲染函数。比如常见的"opaque",对应的就是ForwardRenderer._opaqueStage。
ForwardRenderer._opaqueStage函数中,会进行内置uniform的更新(如cc_matView、cc_cameraPos),随后调用_drawItems函数渲染所有的stageItems。_drawItems函数里只是遍历,调用_draw函数对每个stageItem进行渲染。
ForwardRenderer._draw函数中,还会根据节点更新cc_matWorld等变量。
主要工作是遍历所有pass(effect中的多pass),在其中通过device.setVertexBuffer、device.setIndexBuffer等函数提交顶点数据等内容。
并设置所有uniform变量(含纹理),调用相关函数根据pass中的参数设置混合方式、深度测试开关等内容。
这些数据都会被缓存在device中,最最最后,调用device.draw函数渲染刚刚上传的数据。
device.draw函数中,web平台下会调用对应的API,如gl.bindBuffer、gl.bindTexture等函数将数据提交给GPU,最后调用gl.drawElements、gl.drawArrays函数进行渲染。
图来了(流程图包含了完整的流程,本小节相关的内容在横向分割线之后,即“Cocos → GPU”) !
最右侧内容(每个步骤产出的结果)可以辅助了解它们的作用哦~ 结果图示中,每个文本及其下方的方框表示一个对象,方框内的对象都是其属性(截图的话属性太多了…)。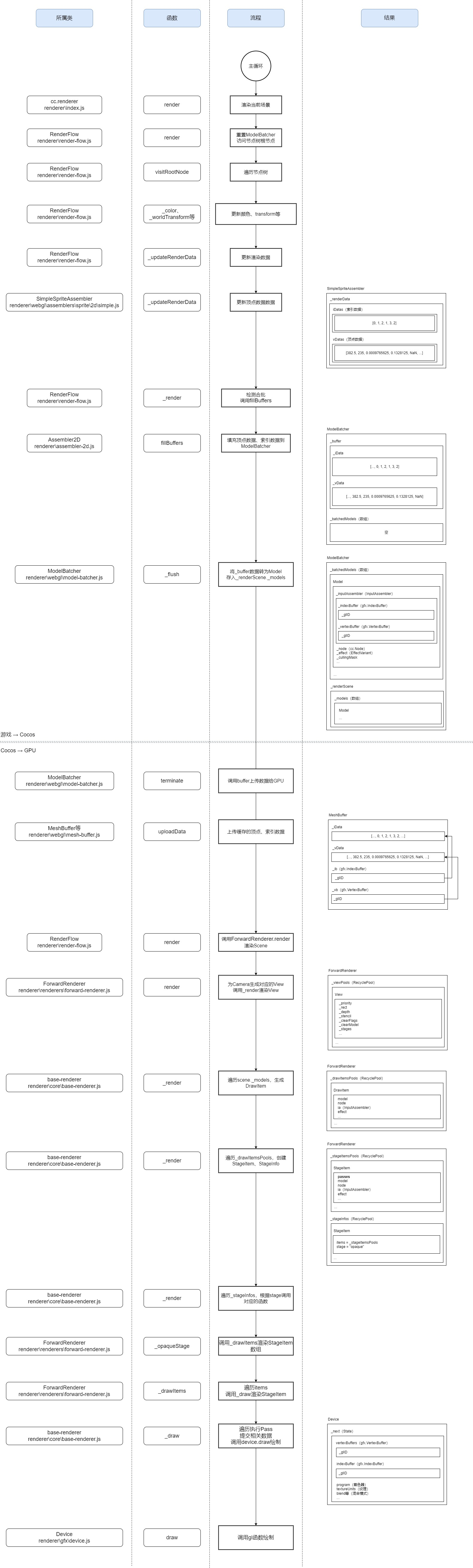
画哪里
我们刚刚好像有提到画哪里这件事…
emmmm… 所谓的画哪里,已经被顶点数据包含了…
三、渲染
终于到了最后一步了!Cocos帮我们把数据交给GPU之后,终于要真真正正地开始画了!
渲染这块还不是我的舒适圈,分享一张觉得非常非常非常棒的图,基于这张图简单讲讲吧(希望我的说法能够让你更直白地理解它们):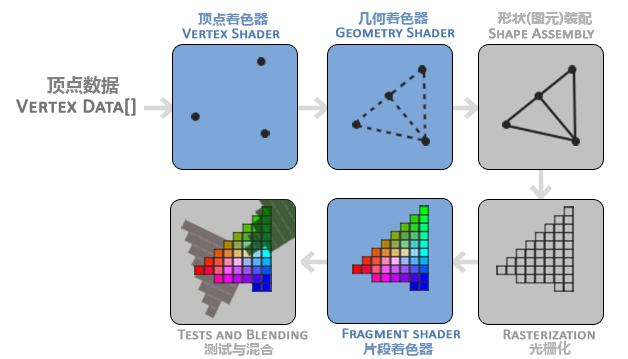
图中最常见的就是顶点着色器和片段着色器。这是我们在开发中会接触到的部分,就是Shader。通过这两个着色器,我们可以让GPU在一定程度上按照我们的想法去进行绘制,实现模糊、波纹等特殊效果。
让我们来渲染我们的图片!
GPU拿到顶点数据后,会通过顶点着色器,确认最终在屏幕上的位置,图片一共是6个顶点。如果没有改顶点着色器,这一步只会做简单的坐标转换。
随后(一般没有几何着色器)图元装配会将这6个顶点连成2个三角形。
光栅化阶段,将三角形转换成实际上的像素点。
对每个像素点调用片段着色器,确定它们最终的颜色值。如果没有改片段着色器,这一步会根据纹理坐标,取对应像素的颜色值,可能会做平滑处理(比如缩放图片)。
最后做测试、混合工作,比如使用Mask组件及图片的混合处理。
也想展开写写… 但实在没有深度的知识,还是不献丑了。网上关于渲染流程的文章非常非常多。大家可以自行研究研究~
如果你想了解更多,可以看看(虽然不是WebGL,但也很有参考意义)主页 - LearnOpenGL CN
四、一些其他的想法
这个小节是一些个人看法,可跳过(后面的其实都可以跳过)。
看完这么长的文章,不知道你有没有一种神奇的仿佛知识融会贯通(但是又好像什么都不懂)的感觉… 如果有一定是我写的不够好哈哈哈哈哈。
最后回到客户端的毕生之敌,DrawCall!
解决问题的第一步是面对问题!
怎么理解DrawCall和DrawCall优化呢?前面谈画画也有提到一些。
一次DrawCall,又称为绘制指令。
丢掉这些名词,就是让GPU画画。我们告诉GPU按照什么画,画哪里,画成什么样。
GPU只能记住一批参数,但是可以让它可劲画,虽然记性不好,但熟练啊,效率又高。
所以我们连续绘制同一张图片,性能是最优的。
但是一直画一张图,显然不符合也不能满足游戏的需求啊。
那咋办?GPU既然只能记住一张图,那… 一张图里有很多小图片也是能理解的吧?
于是合图的优化方式出现了!在一张图里把用到的都塞进去!再通过顶点数据告诉GPU,我只需要你画这么小一部分哦~
所以连续绘制相同图集的图片,性能也是极优的。
到了这里,基本就是常见的DrawCall优化做的事情了。我们合图(静态、动态),并千方百计地让相同图集的元素一起渲染,让GPU一次性画尽可能多的东西。
再后来… 大家发现GPU你小子不是可以记住一批参数吗,多记几张图片不过分吧?
本来GPU根据顶点数据画固定的东西就行了。图片一多,我们还得再告诉GPU每次要按照哪张图片画,比如顶点数据(当然方法应该也是有多种的)。
再到这里,可能不同的情况(设备、游戏)会有不同的效果,虽然DrawCall降低了,但GPU画效率却没有那么高。
好了没有了。再聊就是盲区了。
结尾
本文的初衷是希望能够简单清楚地表达,一张图片从硬盘到屏幕这中间的过程。
粗了讲,就是加载、数据转换、渲染。
细了讲,加载管线、摄像机、渲染组件、渲染流、合批、顶点数据、shader、渲染管线… 大概每个都能单独开一篇…
所以把本文作为一个引子吧,这里面的每个部分,都值得我们去研究。
希望大家看完之后能有一点收获…
很长,所以很感谢你看完了。
涉及的内容很广,如果有不对的地方,烦请指教。
啊终于结尾了!!!
很难描述现在的心情,我从来没有写过这么难写的文章!!!
写细了怕长,写粗了怕没有写出重点。用字怕难以理解,用图怕表达不出精髓。
这篇文章写了很久很久,在面试结束之后就开始写了,现在我已经入职一个月了
好巧不巧,面试的时候我也被问到了这个问题(的一部分),更巧的是,虽然准备了但依旧答得稀巴烂…
当时脑袋一片空白… 浅浅答了第一层哈哈哈哈。然后主动表示再深入就不知道了避免丢人
最初计划在入职前完成它的,但它实在比我想的更复杂,也花了很多时间思考,到底怎么表现才能够更简单易懂。就是入职后… 就没什么时间了
现在人在厦门延趣,《叫我大掌柜》、《寻道大千》都是我们公司的作品(研发),如果感兴趣可以聊聊~
