Cocos js代码在Native侧运行原理
众所周知,cocos的引擎有两套:c++引擎和javascript引擎。在开发游戏的过程中,我们通常是在浏览器中运行调试,最终打包构建之后再放到客户端运行,这两种场景下起作用的便是这两套引擎。为什么我们写的同一份代码,可以分别在两套引擎环境下运行?cocos都为我们做了些什么呢?本文将对这些过程进行详细介绍。
1. js引擎的渲染流程
为了搞清楚双端引擎的差异,首先介绍一下js引擎是怎么渲染。js渲染的流程如下图所示,分为几个阶段。
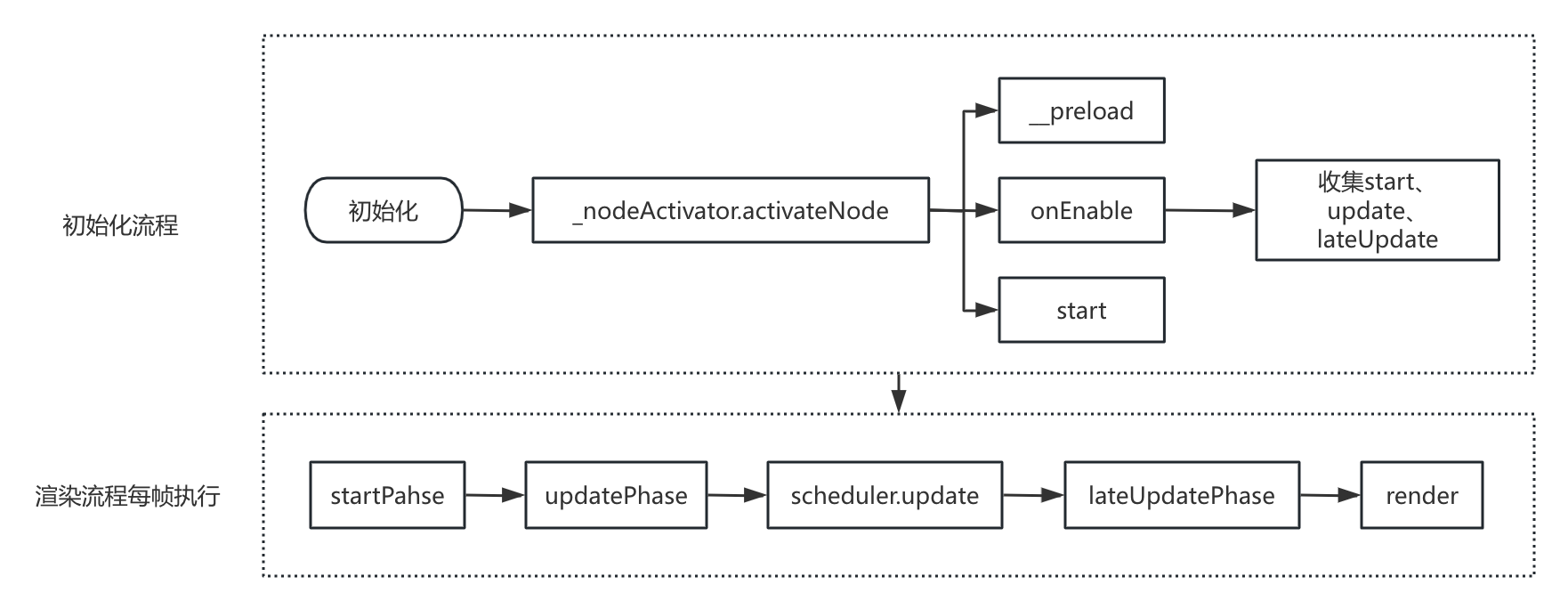
1.1 初始化生命周期方法(__preload、onLoad、onEnable)的执行
初始化阶段,通过cc.director._nodeActivator.activateNode(node, value)方法调用,对node结点进行深度优先遍历,遍历至每一个结点时,会对挂载的组件依次执行__preload、onLoad、onEnable生命周期函数。onEnable执行过程中会收集拥有start、update、lateUpdate生命周期函数的组件,分别放在一个Invoker中。Invoker可以简单理解为一个数组,在特定的时候会遍历其中存放的组件,执行组件的对应生命周期方法。Invoker有不同的种类,适用于不同的生命周期方法,例如:带排序的仅执行一次的OneOffInvoker(用于onLoad、onEnable、start)、不进行排序的仅执行一次的UnsortedInvoker(用于preload)、能重复执行的ReusableInvoker(用于update、lateUpdate)。
上面的收集过程在场景初始化的时候会执行一次,这样就会把场景中所有结点挂载的所有组件的相应生命周期函数执行一次,并收集start、update、lateUpdate生命周期函数,在后续的渲染过程中调用。此外,在修改结点的active属性、parent属性时也会对该结点执行以上过程,但只有onEnable会被再次执行,__preload、onLoad不会再执行了。
场景初始化完成之后,会开始执行CCDirector.mainLoop方法,该方法会在每帧执行,属于渲染流程的核心代码,里面会调用组件的生命周期函数、更新调度器、执行渲染等等,具体包含下面几个重要的流程:
1.2 startPahse
遍历startInvoker存放的组件,执行每个组件的start生命周期方法。startInvoker是OneOffInvoker的实例,因此只会执行一次。
1.3 updatePhase
遍历updateInvoker存放的组件,执行每个组件的update生命周期方法。updateInvoker是ReusableInvoker的实例,会在每次渲染循环中执行一次,可以用来更新结点的属性。由于属于热点代码,不适合执行计算量复杂的运算。
1.4 scheduler.update
执行调度函数,动画、粒子、物理、Schedule系列定时器等都在这里进行更新。
1.5 lateUpdatePhase
遍历lateUpdateInvoker存放的组件,执行每个组件的lateUpdate生命周期方法。特性和update生命周期方法一致,区别仅在于执行的时机更靠后,是在所有的动画更新之后执行。
1.6 render
在上面的几个阶段中,可能修改了结点的一些属性,每个结点都有一个标志位_renderFlag,它的不同bit位表示不同的数据修改,各bit位对应的含义如下。当结点的某个属性变更后,_renderFlag的对应bit位会被设置为1。
| 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|
| Final | postRender | children | render | color | opacity | updateRenderData | worldTransfrom | localTransform | Break | Nothing |
| 终结 | 渲染后处理 | 遍历子结点 | 渲染 | 颜色 | 透明度 | 更新渲染数据 | 更新世界矩阵 | 更新Local矩阵 | 空 | 空 |
渲染流程中,根据上表的顺序,从左往右依次执行相应的处理。其中,和顶点数据填充有关的几个过程有:
updateRenderData:根据前面的处理流程得到的数据,计算出渲染数据,渲染数据几乎就是顶点数据了,但渲染数据只是结点自身的顶点数据信息,而最终提交的顶点数据可能由于合批的原因会包含多个结点的顶点数据。
render:取出渲染数据用来填充顶点数据buffer,可能由于合批导致多个结点的渲染数据填充到了一个buffer中。这个buffer数据会在后面的流程中再统一提交给openGL。
2. 渲染流程的接管
以上的部分属于js引擎的逻辑,在客户端运行时,流程则有一些不一样了,不一样的地方源于代码中会有区分逻辑,在core/renderer/index.js文件中,initWebGL方法有以下的逻辑
if (CC_JSB && CC_NATIVERENDERER) {
// native codes will create an instance of Device, so just use the global instance.
this.device = gfx.Device.getInstance();
this.scene = new renderer.Scene();
let builtins = _initBuiltins(this.device);
this._forward = new renderer.ForwardRenderer(this.device, builtins);
let nativeFlow = new renderer.RenderFlow(this.device, this.scene, this._forward);
this._flow.init(nativeFlow);
}
else {
let Scene = require('../../renderer/scene/scene');
let ForwardRenderer = require('../../renderer/renderers/forward-renderer');
this.device = new gfx.Device(canvas, opts);
this.scene = new Scene();
let builtins = _initBuiltins(this.device);
this._forward = new ForwardRenderer(this.device, builtins);
this._handle = new ModelBatcher(this.device, this.scene);
this._flow.init(this._handle, this._forward);
}
可以看到,在客户端Native运行时,scene、_forward、flow这些变量都是从renderer这个名称下创建出来的,在cocos-engine里面直接搜索是搜索不到它们的实现的,这是因为renderer下面的所有方法都是由运行在Native的c++代码注入的。在c++引擎代码仓库的cocos2d-x/cocos/scripting/js-bindings/auto/jsb_renderer_auto.cpp文件中,以下代码便是在global中注入renderer和其下的各种方法
bool register_all_renderer(se::Object* obj)
{
se::Value nsVal;
if (!obj->getProperty("renderer", &nsVal))
{
se::HandleObject jsobj(se::Object::createPlainObject());
nsVal.setObject(jsobj);
obj->setProperty("renderer", nsVal);
}
se::Object* ns = nsVal.toObject();
js_register_renderer_ProgramLib(ns);
js_register_renderer_EffectBase(ns);
js_register_renderer_Camera(ns);
js_register_renderer_ForwardRenderer(ns);
...
return true;
}
我们以forward-renderer为例,它在ForwardRenderer下注入了renderCamera、init、render方法,当js侧调用了这些方法时,代码的执行便会转到c++侧这些方法实现的地方来,进一步便来到了cocos2d::renderer::ForwardRenderer中。名称以js_register开头的这些函数只负责执行注册逻辑,把js的参数转换成c++侧对应类的参数,再把执行流程转交给c++侧对应类。
bool js_register_renderer_ForwardRenderer(se::Object* obj)
{
auto cls = se::Class::create("ForwardRenderer", obj, __jsb_cocos2d_renderer_BaseRenderer_proto, _SE(js_renderer_ForwardRenderer_constructor));
cls->defineFunction("renderCamera", _SE(js_renderer_ForwardRenderer_renderCamera));
cls->defineFunction("init", _SE(js_renderer_ForwardRenderer_init));
cls->defineFunction("render", _SE(js_renderer_ForwardRenderer_render));
cls->defineFinalizeFunction(_SE(js_cocos2d_renderer_ForwardRenderer_finalize));
cls->install();
JSBClassType::registerClass<cocos2d::renderer::ForwardRenderer>(cls);
__jsb_cocos2d_renderer_ForwardRenderer_proto = cls->getProto();
__jsb_cocos2d_renderer_ForwardRenderer_class = cls;
se::ScriptEngine::getInstance()->clearException();
return true;
}
在cocos-engine代码中通过CC_NATIVERENDERER来区分js和Native逻辑,只有一小部分逻辑是这么做的,其它大多数的类则是通过下面的jsb adapter适配层来实现。
3. jsb adapter适配层
jsb adapter适配层有单独的代码仓库,专门用于处理Native侧和js侧不同的逻辑,通过覆盖js侧函数的方式来实现不同的逻辑。以RenderFlow为例,js侧的类都挂载在cc名称空间下,这里首先拿到cc.RenderFlow,然后覆盖了它的init和render方法。对于大多数类,jsb adapter只会覆盖js引擎类中的部分方法,所以代码实际运行的时候有的方法还是会执行js引擎中的方法。需要两个代码仓库结合起来看,才能确定执行的到底是哪个方法。
let RenderFlow = cc.RenderFlow;
RenderFlow.init = function (nativeFlow) {
cc.EventTarget.call(this);
this._nativeFlow = nativeFlow;
};
RenderFlow.render = function (scene, dt, camera = null) {
_rendering = true;
...
this._nativeFlow.render(scene._proxy, dt, camera);
_dirtyTargets = _dirtyWaiting.slice(0);
_dirtyWaiting.length = 0;
_rendering = false;
};
4. 重要结点信息的传递
虽然js侧的部分代码逻辑会被native或者jsb adapter拦截,但关键的node结点还是在js侧创建的,而node结点在整个渲染过程中又是必不能少的,c++侧虽然拦截了一些类的实现,但要渲染的话也需要知道node结点树。js侧的node结点信息是如何传递给c++的呢?
在c++侧有一个类NodeProxy,和js侧的CNode是对应的,c++侧的渲染便是基于NodeProxy的结点树来进行的,所以问题在于怎么构建这个对应关系。
4.1 Node-unit对于结点属性的统一管理
在CNode的构造函数中,有下面这几行代码。
if (CC_JSB && CC_NATIVERENDERER) {
this._proxy = new renderer.NodeProxy(this._spaceInfo.unitID, this._spaceInfo.index, this._id, this._name);
this._proxy.init(this);
}
其中的_spaceInfo在双端数据共享上很关键,在_initDataFromPool函数中初始化的。
if (!this._spaceInfo) {
this._spaceInfo = nodeMemPool.pop();
let spaceInfo = this._spaceInfo;
this._matrix = cc.mat4(spaceInfo.localMat);
Mat4.identity(this._matrix);
this._worldMatrix = cc.mat4(spaceInfo.worldMat);
...
}
nodeMemPool是Node-unit的管理池,Node-unit在构造的时候会创建128个长度的各类数据buffer。在Node-unit的父类UnitBase中,_spacesData存放着这些buffer不同区段的数据,如下图所示,_spacesData[i]中的dirty使用dirtyList第i块位置的数据,zOrder使用zOrderList第i块位置的数据,_spacesData相对应的也有128个数据。_spacesData的使用情况由UnitBase中的_data和_signData来表示。_signData是一个256长度数组,偶数位表示对应的_spacesData数据块是否空闲,奇数位表示下一个可用的_spacesData数据快的索引。_data是只有2个数据的数组,_data[0]表示下一个可用_spacesData数据块的索引,_data[0]表示已经使用的数据块的数量。nodeMemPool.pop函数会从_spacesData中获取一块可用的空间,存放在CNode的_spaceInfo变量中。如果空间不足,nodeMemPool会创建一个新的Node-unit实例。
let NodeUnit = function (unitID, memPool) {
UnitBase.call(this, unitID, memPool);
let contentNum = this._contentNum; // 这个值默认为128
this.trsList = new FLOAT_ARRAY_TYPE(contentNum * TRS_Members);
this.localMatList = new FLOAT_ARRAY_TYPE(contentNum * LocalMatrix_Members);
this.worldMatList = new FLOAT_ARRAY_TYPE(contentNum * WorldMatrix_Members);
if (CC_JSB && CC_NATIVERENDERER) {
this.dirtyList = new Dirty_Type(contentNum * Dirty_Members);
this.parentList = new Parent_Type(contentNum * Parent_Members);
this.zOrderList = new ZOrder_Type(contentNum * ZOrder_Members);
this.cullingMaskList = new CullingMask_Type(contentNum * CullingMask_Members);
this.opacityList = new Opacity_Type(contentNum * Opacity_Members);
this.is3DList = new Is3D_Type(contentNum * Is3D_Members);
this.nodeList = new Node_Type(contentNum * Node_Members);
this.skewList = new FLOAT_ARRAY_TYPE(contentNum * Skew_Members);
this._memPool._nativeMemPool.updateNodeData(
unitID,
this.dirtyList,
this.trsList,
this.localMatList,
this.worldMatList,
this.parentList,
this.zOrderList,
this.cullingMaskList,
this.opacityList,
this.is3DList,
this.nodeList,
this.skewList
);
}
}
for (let i = 0; i < contentNum; i ++) {
let space = this._spacesData[i];
...
if (CC_JSB && CC_NATIVERENDERER) {
space.dirty = new Dirty_Type(this.dirtyList.buffer, i * Dirty_Stride, Dirty_Members);
space.zOrder = new ZOrder_Type(this.zOrderList.buffer, i * ZOrder_Stride, ZOrder_Members);
...
}
}

目光转到jsb adapter中,可以看到node-proxy有以下实现。_zOrderPtr指向了spaceInfo.zOrder的属性,在zorder发生了变化之后,会调用updateZOrder把最新的zorder存放进去。由此可知,NodeUnit中的zOrderList变量存放的是各个结点的zorder信息,其它的数据字段也是一样的。
cc.js.mixin(renderer.NodeProxy.prototype, {
_ctor () {
this._owner = null;
},
// owner也就是CNode结点
init (owner) {
this._owner = owner;
let spaceInfo = owner._spaceInfo;
this._owner._dirtyPtr = spaceInfo.dirty;
this._dirtyPtr = spaceInfo.dirty;
this._parentPtr = spaceInfo.parent;
this._zOrderPtr = spaceInfo.zOrder;
...
owner._proxy = this;
...
},
updateZOrder () {
this._zOrderPtr[0] = this._owner._localZOrder;
let parent = this._owner._parent;
if (parent && parent._proxy) {
parent._proxy._dirtyPtr[0] |= RenderFlow.FLAG_REORDER_CHILDREN;
}
},
})
4.2 NodeProxy对于结点属性的使用
上面介绍了结点属性是如何管理和更新的,接下来再看看C++是如何使用这些数据的。c++的NodeProxy类的构造函数如下图。
NodeProxy::NodeProxy(std::size_t unitID, std::size_t index, const std::string& id, const std::string& name) {
NodeMemPool* pool = NodeMemPool::getInstance();
UnitNode* unit = pool->getUnit(unitID);
UnitCommon* common = pool->getCommonUnit(unitID);
_signData = common->getSignData(_index);
_dirty = unit->getDirty(index);
_localZOrder = unit->getZOrder(index);
...
}
在上面的NodeUnit构造函数中,有一行代码:this._memPool._nativeMemPool.updateNodeData。_nativeMemPool是renderer.NodeMemPool的对象,而后者也就是上面的NodeMemPool。updateNodeData方法的调用将NodeUnit的各种数据buffer传递给了c++侧,c++侧通过NodeMemPool类将这些参数保存了下来,unitID用于区分不同的NodeUnit实例。通过4.1节开头的代码可知,NodeProxy构造函数的参数指的都是spaceInfo里面的信息。由于UnitNode保存的是128个结点数据的buffer,通过spaceInfo可以获取到本结点对应的数据。
至此,就完成了CNode结点数据从js侧传递到c++侧的流程。总结上面的流程可知,C++侧的NodeProxy只是js CNode的代理,CNode相关的数据通过NodeMemPool、NodeUnit等类的帮助批量(128个)传递给C++。CNode的属性众多,但并不是所有属性都会传递给C++,从4.1节展示的代码看,只有11个属性会进行传递。
5. 纹理组件渲染全流程
以上几部分介绍了渲染的通用流程,下面以使用频率较高的纹理渲染组件CSprite为例,看看C++侧是怎么实现纹理的渲染的。
每一个渲染组件都会有一个assembler,assembler负责维护更新顶点数据,不同的渲染组件顶点数据的更新逻辑不一样,CSprite组件有Simple、Slice、Tiled等几种模式,每种模式都对应着一个专门的assembler,本文以Simple模式的assembler为例来讲解。
Simple模式的assembler继承自Assembler2D,实现了updateRenderData、updateUVs和updateVerts 3个方法。updateRenderData用于更新渲染数据renderData,由于顶点数据每帧都要填充,如果每帧都去计算会很低效,因此便有了renderData用来保存计算出来的顶点数据。在每帧渲染的时候,只需要把renderData中保存的顶点数据拿去填充顶点缓冲buffer就可以了。updateRenderData里面会调用updateUVs和updateVert来更新UV数据和顶点坐标数据。虽然updateRenderData会被每帧调用,但只有在_vertsDirty为true时才会更新顶点数据。
updateRenderData (sprite) {
this.packToDynamicAtlas(sprite, sprite._spriteFrame);
if (sprite._vertsDirty) {
this.updateUVs(sprite);
this.updateVerts(sprite);
sprite._vertsDirty = false;
}
}
将renderData中的顶点数据填充到顶点缓冲buffer,是在父类Assembler2D的fillBuffers中进行的。fillBuffers取出_renderData中保存的数据,获取一个通用的mesh buffer,mesh buffer里面存放的是真正会传递给顶点缓冲的顶点数据。下面的代码中,在把顶点数据设置完后,mesh buffer会在收集到足够的顶点数据后、在合适的时机再进行传递,避免每个渲染组件都要传递数据造成的低效。
fillBuffers (comp, renderer) {
let renderData = this._renderData;
let vData = renderData.vDatas[0];
let iData = renderData.iDatas[0];
let buffer = this.getBuffer(renderer); // 这里获取到的是ModelBatcher中通用的mesh buffer
let offsetInfo = buffer.request(this.verticesCount, this.indicesCount);
// fill vertices
let vertexOffset = offsetInfo.byteOffset >> 2,
vbuf = buffer._vData;
if (vData.length + vertexOffset > vbuf.length) {
vbuf.set(vData.subarray(0, vbuf.length - vertexOffset), vertexOffset);
} else {
vbuf.set(vData, vertexOffset);
}
...
}
再看jsb adapter中对应assembler的实现(engine/assemblers/sprite/2d/simple.js文件)。c++侧的SimpleSprite2D对该assembler进行了扩展
let proto = cc.Sprite.__assembler__.Simple.prototype;
let nativeProto = renderer.SimpleSprite2D.prototype;
proto.updateWorldVerts = function(comp) {
this._dirtyPtr[0] |= cc.Assembler.FLAG_VERTICES_DIRTY;
};
proto._extendNative = function () {
nativeProto.ctor.call(this);
};
...
jsb adapter对RenderData进行了修改,创建了c++侧的RenderDataList对象,并通过setRenderDataList方法将RenderDataList对象传递给assember。在RenderData中创建了新的buffer(用于存放顶点数据)时,updateMesh也会将这个buffer传递给c++侧的RenderDataList,因此c++就能直接访问到js侧填充好的渲染数据。
let proto = cc.RenderData.prototype;
cc.RenderData.prototype.init = function (assembler) {
this._renderDataList = new renderer.RenderDataList();
assembler.setRenderDataList(this._renderDataList);
this._nativeAssembler = assembler;
};
let originUpdateMesh = proto.updateMesh;
proto.updateMesh = function (meshIndex, vertices, indices) {
originUpdateMesh.call(this, meshIndex, vertices, indices);
if (vertices && indices) {
this._renderDataList.updateMesh(meshIndex, vertices, indices);
}
}
经过上面的步骤,渲染数据有了,assembler有了,还需要将它们串起来。jsb adapter对Assembler类也进行了扩展,Assembler类是SimpleSprite2D的父类,在初始化函数init中,会调用node._proxy.setAssembler方法将自己传递给NodeProxy对象,这样通过NodeProxy就能访问到该结点相关的assembler了。
let originInit = cc.Assembler.prototype.init;
let Assembler = {
init (renderComp) {
originInit.call(this, renderComp);
if (renderComp.node && renderComp.node._proxy) {
renderComp.node._proxy.setAssembler(this);
}
},
}
c++侧的SimpleSprite2D类的fillBuffers方法和js侧的Assembler2D的fillBuffers方法作用是一样的,所做的事情也差不多,从渲染数据renderData中获取顶点数据,传递给c++侧的mess buffer,后续再由mess buffer上传至顶点缓冲。
void SimpleSprite2D::fillBuffers(NodeProxy* node, ModelBatcher* batcher, std::size_t index)
{
// _datas即RenderDataList对象,由于SimpleSprite2D的祖先类是Assembler,所以有渲染数据_datas
RenderData* data = _datas->getRenderData(0);
MeshBuffer* buffer = batcher->getBuffer(_vfmt);
auto& bufferOffset = buffer->request(4, 6);
uint32_t vBufferOffset = bufferOffset.vByte / sizeof(float);
float* dstWorldVerts = buffer->vData + vBufferOffset;
memcpy(dstWorldVerts, data->getVertices(), 4 * _bytesPerVertex);
6. 总结
本文首先介绍了cocos js引擎的渲染流程,接着介绍了cocos c++引擎如何对js引擎部分逻辑进行接管,jsb adapter如何处理c++引擎的差异逻辑,js引擎的Node结点数据如何传递给c++引擎,实现两端的数据共享。最后以CSprite渲染组件为例,结合jsb adapter,详细介绍了c++如何实现的纹理渲染。其它的渲染组件在工作流程上也有类似的各种差异化处理。由此可知,一个组件在web侧和c++侧的工作方式完全不一样,c++属于底层语言,相比于js来说,执行渲染会更加高效,所以原生的各种渲染组件都会由c++来接管。如果是我们自己写的渲染组件,由于缺少c++的接管实现,实际上就全部是由js来渲染了,在对渲染性能有较高要求的场景,甚至可能需要有我们自己的c++接管实现。