
---- 2.2.0 beta.2 更新: 在 iOS 上使用 V8 引擎取代 JSC , 所以2.2.0 beta.2 之后的开发者理论上不会再遇到这个问题----
由于我们项目正在使用的 2.1.x 版本在 iOS 上发热很严重, 所以 2.2.0-alpha-5 出来的第一时间, 我就开始试着把我们项目在2.2.0上跑起来看看效果.
测试期间我遇到了几个小bug, 我能修的都已经提交PR, 有几个已经被合并进主仓库, 等下个版本出来的时候就会修复, 所以不再展开叙述.
这个帖子主要是来说一下我上周花了一周时间理清的一个 JavascriptCore(JSC) 的bug 是如何通过 2.2.0 让我们的项目崩溃的.
如果你知道这个在JSC上会打印出来什么, 那这个坑你是踩过的…
(()=>{
let k = 0;
Promise.resolve().then(()=>{
k = 1;
})
console.error(k);
console.error(k);
})();
Ps: 我们是一个捕鱼项目, 全程测试机型是 iPhone 6s, 12.3.1
-
起初, 我从大厅界面进入游戏打鱼场景的时候, 感觉比2.1有了一丝卡顿, 主要表现在logic frame的短时间大幅度增加, 过场的加载界面logic frame 峰值大约是从之前的 50ms 提升到 150ms 左右, 但是由于是载入界面, 卡顿并没有实际的影响, 所以并没有过多关注这个问题.
-
进入打鱼场景后, 发现流畅度和2.1 一样, 我们项目仍是能跑到60fps, 但是发热有非常明显的缓解, 原来5分钟烫手, 现在10分钟温温热, 大致看了一下, 在native 上, cocos 现在在C++层增加了一个NodeProxy, 保存了js中的cc.Node的一些渲染需要的属性, 重头的渲染计算都放在了C++层, 这样就解决了iOS上JSC不能JIT, 导致JS代码执行过重的计算时发热量比较大的问题, 给cocos 团队点个
 .
. -
打鱼到15分钟左右的时候, 游戏突然卡死了, 在Xcode里 看到, 原因是某个节点的是自己的子节点, 所以在遍历子节点的时候无限递归, 然后爆栈了
-
既然是因为 “自己是自己的子节点” 产生的bug, 那么顺着这个想法, 我做了一处改动, 提交了一个PR
assertNotSelfChild should check start from this, not this->getParent()
但是我知道这个只是某个bug的表现形式, 为什么会出现要把自己插到自己的子节点里, 这才是真正要找寻的问题, 于是我便开始看这里相关的代码 -
分析NodeProxy, 可以看到里边有一个notifyUpdateParent, 是根据this->_parentInfo 里的unitID 和 index 从一个叫做 NodeMemPool 里获取的parent节点, 然后更新该节点的父节点的, 理所当然的, 我认为问题出在这个_parentInfo里.
-
几经测试, 发现这个问题出现几率非常低, 我把测试服的游戏房间的出鱼策略调整的非常激进, 一直出各种boss鱼, 并且开启一击必杀, 但即使这样, 也并不是必现, 而是可能好几分钟才会出现一次, 这给我的测试带来了效率上的问题, 所以我着手搭建一个demo, 根据我的分析, 这里应该是在频繁创建并且回收节点的时候, 没有做好回收机制, 导致的这个unitID 和 index 的错乱, 所以我就搭建了一个非常简单的demo: 随机的, 大量的, 频繁的创建和回收节点, 每帧创建200个或者销毁200个(如果有的话), 达到10000个节点时, 切换场景, 并在新场景的脚本的onLoad里再切换回原场景, 可惜bug并没有复现, 测试代码如下:
Ps: 虽然没有复现想要的bug, 但是却无意间发现了一个内存泄漏的问题, 已经提交给cocos官方团队
-
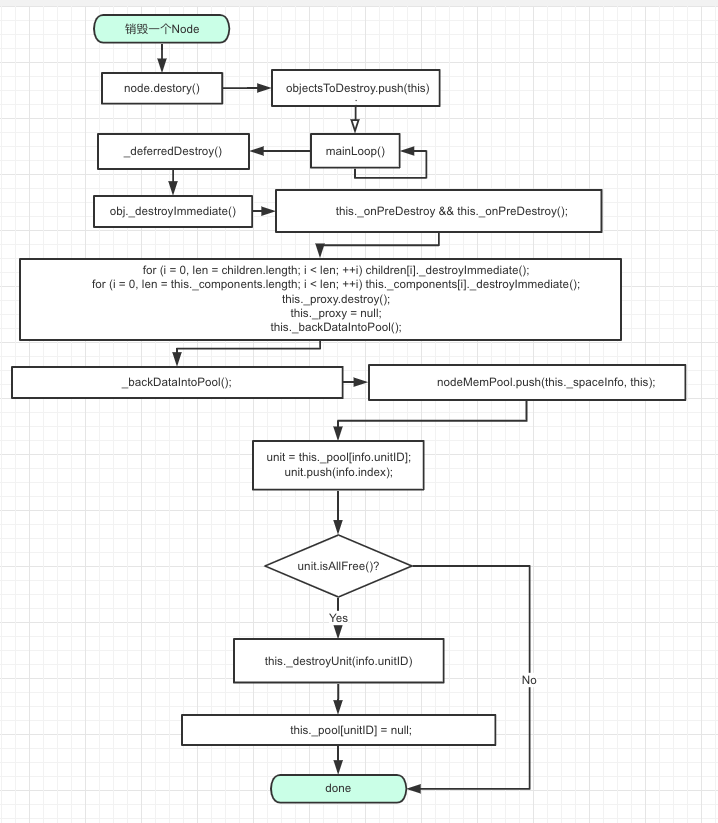
看来是只在我们项目里才能出现这个bug了, 没办法, 我开始从代码层面直接去分析这个问题. 经过一段无头苍蝇一样的查找, 我最终决定好好分析一下NodeMemPool相关的代码, 试图彻底搞明白 unitID 和 index 的整个生命周期, 于是我做了一个这样的流程图 (spaceInfo其实还有很多渲染相关的数据, 但是因为和生命周期关联不大, 所以我没有列出来. 还有, 请原谅我不会UML, 只好乱写, 凑合看吧):
我是这么理解 node, nodeMemPool, unit , unitID, index, 和spaceInfo的:



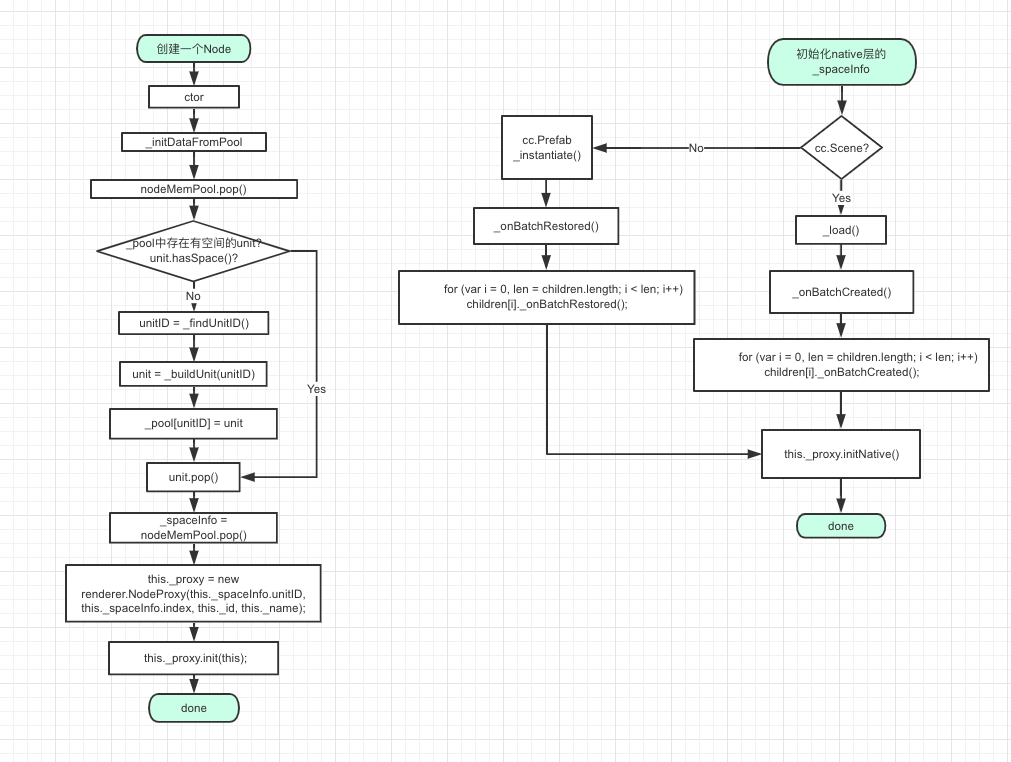
- 假如node是个人的话, nodeMemPool 可以理解为是一个造车厂, unit就是一辆公交车;
- 当出现一个人(node) 需要坐车的时候(ctor()), 先判断造车厂(nodeMemPool)里的所有车(unit)中, 有没有存在空座位的车(unit.hasSpace()), 如果不存在有空座位的车的时候, 就查找一下目前空闲的车编号(unitID), 然后造一辆车出来, 然后把车上一个座位号(index)和车的编号(unitID)生成的车票(_spaceInfo)交给这个人, 让这个人坐到车里面去;
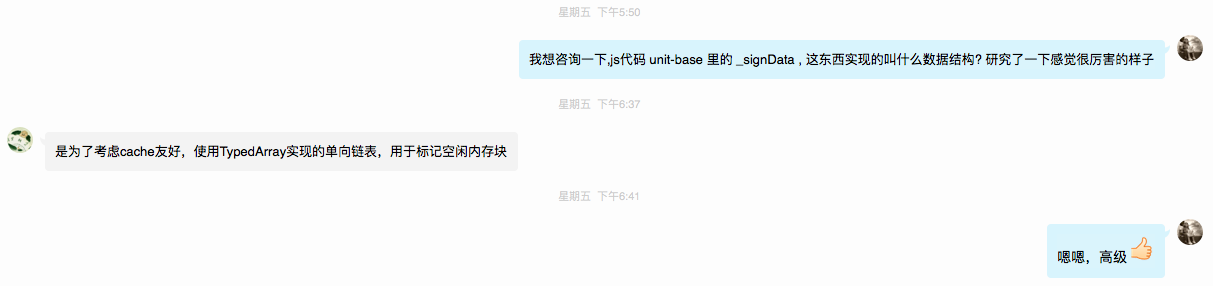
- 当有人下车时(node.destory()), 根据这个人车票(_spaceInfo)上的的车编号(unitID), 找到这辆车(unit), 然后把这个人的座位(index)还回去(unit.push(index)), 这时判断一下车(unit)上空不空(unit.isAllFree()), 如果车空了, 就把车炸了, 把车的编号(unitID) 还回造车厂(nodeMemPool), 这样下次再需要造车的时候, 就可以再次使用这个车编号(unitID)了.
-
了解了unitID和index的原理后, 我开始在代码里加大量的埋点日志, 然后发现一种情况, 就是可能会存在有人要下车, 但是车已经被炸了…
-
确定是unit里的问题之后, 我开始研究unit中是如何判断车需要被炸掉的(unit.isAllFree()), 还在base-unit中发现了一个很神奇的写法: 用数组(_signData)加一个额外的标记(_data[0]) 作出了链表 进而实现了栈结构
我把实现代码摘出来, 有兴趣的小伙伴可以了解一下
-
我开始以为是_signData这种写法会有问题, 于是记录了每个unit的pop和push的操作(this.record)
在出bug时拿出记录的’黑盒子’,放在自己实现的signData里重现这个, 最终发现有个车票被两个人挨着下车!!中间没人上来!, 也就是说有车票同时被两个人持有了!
经过了成吨的埋点测试, 批量上了各种锁, 并且大幅度降低了车的载客量(unit的总容量), 最后发现了这个非常隐蔽的问题:




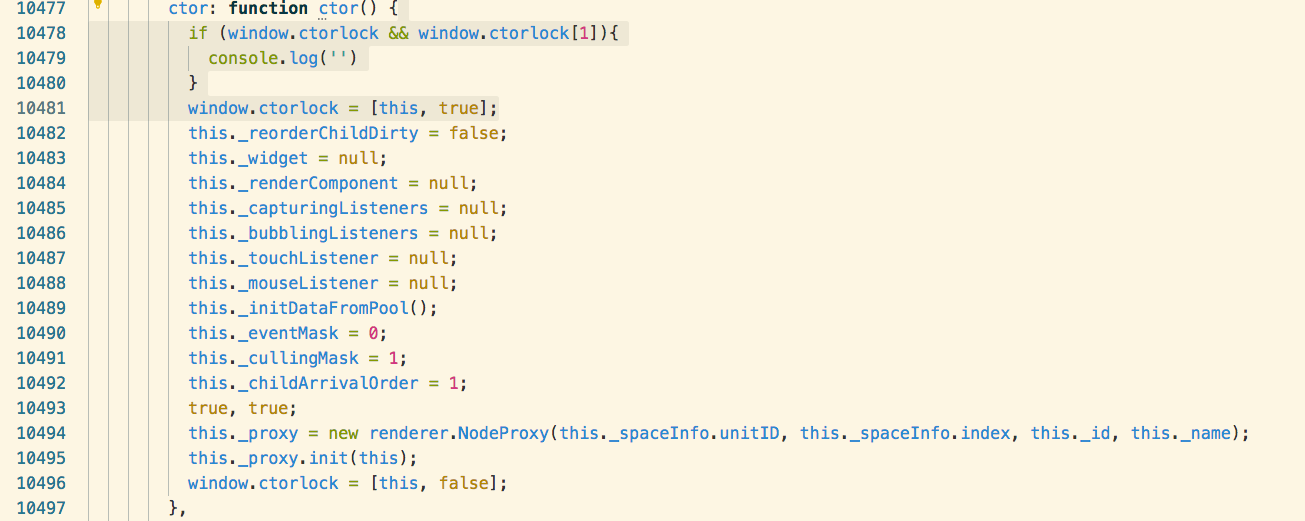
而这个问题, 说出来我自己都不信: 代码里的一些锁莫名的被锁上了!! 例如上边这个 ctorlock , 是在cc.Node的构造函数里, 这一段代码无疑是同步阻塞执行的, 但是我在10479行console.log(’’) 上打的断点, 还是会走到!!!
11. 最后我通过观察调用栈, 发现了一个奇妙的事情, 如图
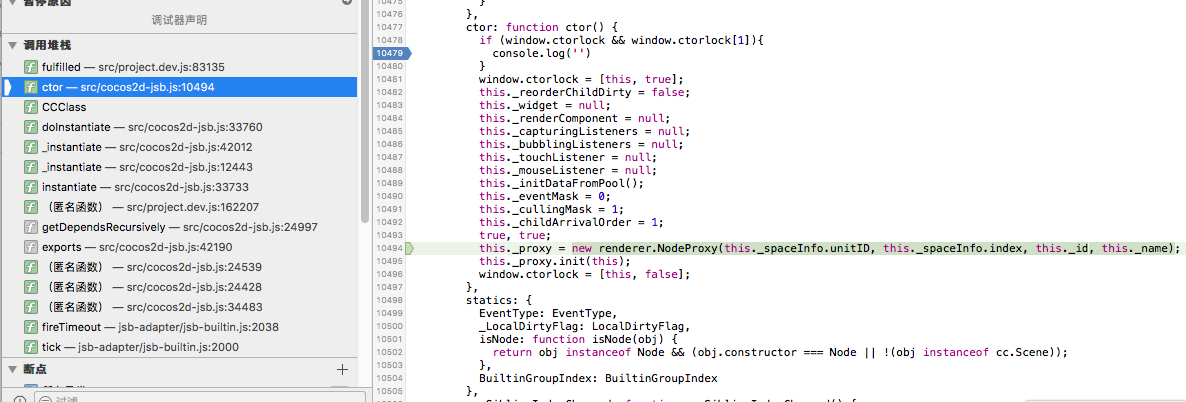

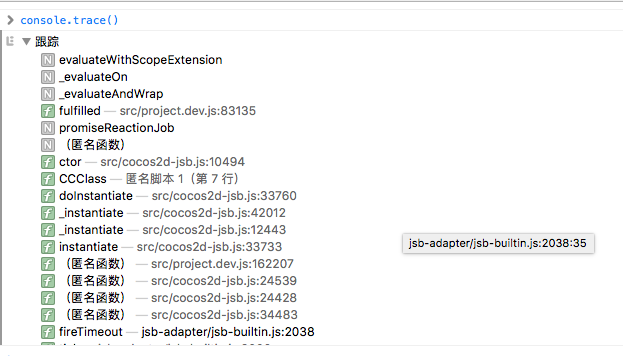
本来在走ctor里的new renderer.NodeProxy(), 然后突然执行起来了我项目逻辑代码里的一处 Promise 的 then 里的方法(promiseReactionJob)!!
然后我就发现不只new renderer.NodeProxy(), 其他所有执行native binding code 的地方都会可能会出现这种问题, 由此, 我怀疑执行native code 的时候, 是不是存在一个潜在的await, 虽然代码看起来是同步, 但是其实会产生一个异步, 导致我Promise里的任务插空执行了, 带着这个疑问, 我做了一些测试…
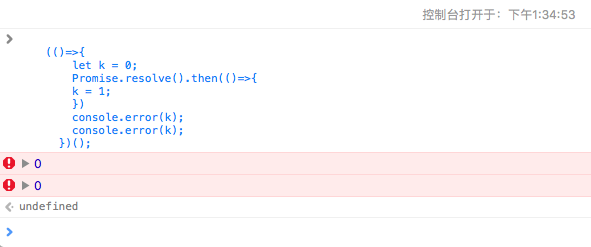
回到最上边的例子, 在chrome和iOS的safari上, 执行, 结果都是 打印出来 0 和 0
chrome:

safari:
而在神奇的iPhone的JSC上:
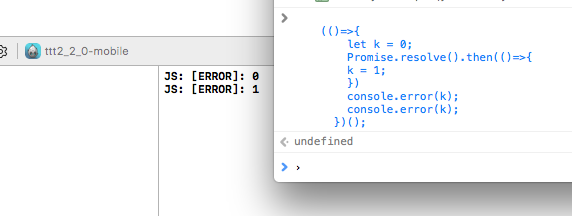
打印出来 0 1 啊摔
最终确定了这件事情:
在JSC上, 执行 native code 之后, 会把所有microtask 队列里的任务给执行了!!
(了解Tasks, microtasks, queues 和 schedules)
Ps: 个人理解的 Task(macrotask) 队列 和 microtask 队列的关系, 就像 一个安检通道, task就是普通通道, 而mircotask就是vip通道, 虽然安检门每次只能过一个人(js本身单线程), 但是每次保安都会等通过一个普通人时, 看一下vip通道有没有人, 如果有, 就让所有vip先过去, 再让下一个普通人通过, 并再次检查vip通道有没有人; 如果vip通道没有人, 则直接让下一个普通人通过, 并再次检查vip通道有没有人, 依次循环往复…
就是所有通过 async( Promise ) 的实现异步的代码, 都会在这个过程中出现时序错乱!!!
嘿嘿嘿, 是不是知道为什么在iOS上总是会出一些莫名其妙的bug, 有些还是加个打印(console.log)就好了? 因为console.log也是native code…
恰巧我们项目里大量的使用了async来创建各种的prefab, 这样导致在需要创建的prefab超级多时, 会出现这种情况:
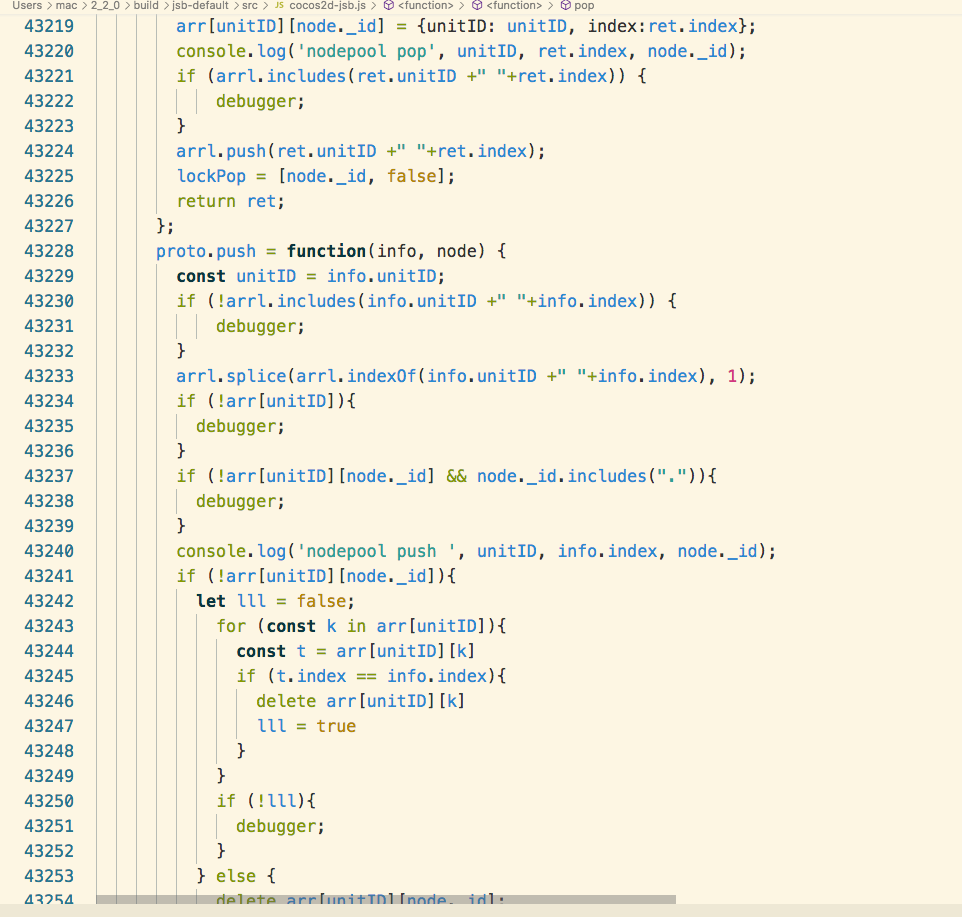
- 一个人A 要上车, 造车厂发现没有空车, 要造一辆, 查找现在空闲的车编号(unitID) 比如是19号车编号可以造, 于是此时unitID=19, 造车的时候这期间会执行一次通知C++层的操作, 把车编号传到底层去—this._memPool._nativeMemPool.updateNodeData(unitID,…)
- 而这个操作是执行native code, 于是可能刚好我的microtask 里还有一个人B要上车, 执行完native code 会导致这个B在19号车造好之前来造车厂, 造车厂发现没有空车(19号车造了一半, 并没有被加入到库存名单里(_pool), 还无法被搜索到), 所以造车厂又找到可以使用19这个车编号(unitID), 再造一辆车…等到第二辆车造完了, 库里标记19的车就变成了第二辆车(pool[unitID] = findUnit);
- 这时就有A和B两个人都持有19车(unitID)0号座(index)的车票…
- 而之后A虽然在19号车上坐, 但是他在下车的时候会从第二辆车上下下来…这样等于第二辆车多了张票, 就会存在最后一个人下车的时候, 车已经不在了, 进而产生一个调用 undefined.push(index) 的 bug.
- 而因为实例化prefab的时候是先创建父节点,然后子节点, 所以如果A是B的父节点, 那么当出问题时, A和B就有同样的unitID和index; 当B在notifyUpdateParent里要通过unitID和index找父节点时找到有同样unitID和index的自己. 这样就导致了最初的爆栈问题.
最终我个人的解决方案就是, 使用setTimeout实现的Promise polyfill, 这样Promise就进到macrotask(Task) 队列了, 这样等于只有一个队列, 执行native binding code之后, microtask 是空的, 就不会有任何怪事发生.
河南郑州的老乡们, 有找工作的大佬可以发简历给我帮内推
ztory#foxmail.com
另寻Java服务端大佬一枚
官方小编按:感谢巨佬反馈,确实 iOS 上的一些崩溃问题是这个地方引起的,这是 iOS 自带的 JavaScriptCore 导致的 bug。我们会尝试在 2.2.1 启用 JavaScriptCore,来彻底避免这个错误。