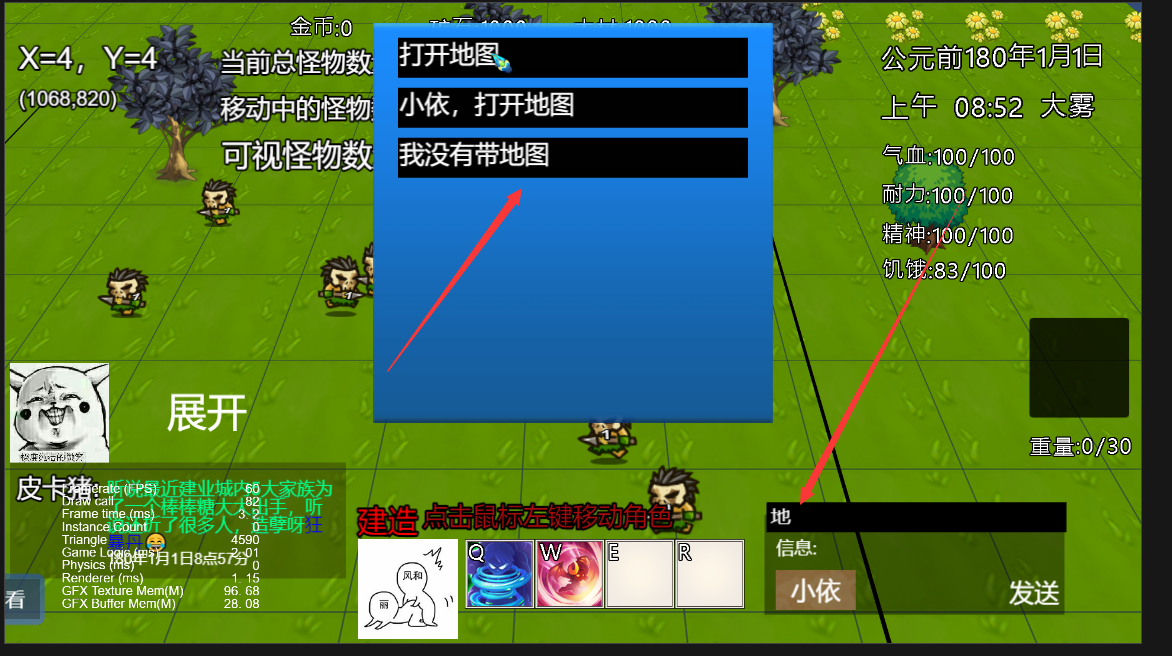
比如 我有 3条语句
1:打开地图
2:好饿呀
3:我没有带地图呀
如果玩家输入 “地” 的话,应该返回 1和3,想要得到 1和3的话,一般情况下要遍历一次才能得到。
如果信息有10万左右,遍历显然是无法接受的。
麻烦问一下各位大佬,是不是只能用内存换取效率了,有没有更好的算法?

比如 我有 3条语句
1:打开地图
2:好饿呀
3:我没有带地图呀
如果玩家输入 “地” 的话,应该返回 1和3,想要得到 1和3的话,一般情况下要遍历一次才能得到。
如果信息有10万左右,遍历显然是无法接受的。
麻烦问一下各位大佬,是不是只能用内存换取效率了,有没有更好的算法?
如果要求效率 我想的是 可以不可以预先已经查询过了 ,常用汉字500个 如果输入一个地的键值对就是地:[1,3] 就得到我们预先设置好的13两个值 然后直接查找13 这样不就是快很多了吗.
可以的,我现在就用的这种方法,效率是很高,但是占内存,这就是内存换效率。
因为数据实在太多,近10万左右,我就问一下看看有没有更好的方法。比如特别牛的算法什么的,如果有满足的就可以剩下很多内存
是键值对占用内存?还是 查询13占用内存?. 那能不能再键值对的值上在家一个键值对.值是某个文件从某个开头到某个结尾…这样就是查询本地文件了.均衡一下 速度会慢一点 但是占用内存不是很大了.还可以分成很多个小文件 ,
我想了一会 一个想法也不知道合适不合适 常用汉字3-5百 打开地图 打开这四个字是关联的.打没 这两个字是不关联的,先吧你所有的文字都进行一遍文字前后文字关联对比.然后生成算法 ,比如上面三段文字,我输入一个 地 自动关联地前面的一个文字和后面一个文字 上面的数据可以得知 地后面一定是图 地前面可能是开和带 …貌似没思路了 …感觉输入法不就是这样联想输入吗
这些前提都得存起来,不可能动态生成的,动态做的话,效率更低
快很,字典树hash级别,来一条处理一条,这集合维护
我也想过这个 但是我不明白的是 一句话的拼音 怎么用一个字的拼音找到这句话的哈希呢?
10万级数据的字典树应该也得存起来吧,用唯一ID去查找,如果不提前存起来,就得动态生成,然后查找,如果提前生成,就占用内存,应该是这样的吧
好像我理解有问题,我再想想
按照我现在的需求感觉用不上这么高深的数据结构,字典树和 Map 对于我现在的需求感觉没啥区别,字典树一个节点存“地”,这个地有3个返回值,那么这个地的节点下面还会有3个节点来存这些数据,查找是很快,但是内存一点没少。
我现在的实现方法是用Key Value的方式,value是一个数组,用来存所有满足的信息,所以,key会有很多,这个key 应该就相当于 字典树的节点。这是我现在的理解,有不对的地方,希望能大佬能帮忙指出来
服务器来算就没这烦恼了
10万条 内存毫无压力啊 假如你上百万千万以上才会有压力
10万条确实压力不大,但是还有别的功能,因为项目比较大,是需要稍微考虑一下的,如果有好的解决方案的话会更好
不如数据库?
目前单机单线程项目,想做到极致,实在不行,在考虑其他的,谢谢
感觉在处理这个问题上,DFA还不如 字典树的数据结果,有理解不到的地方,还望指正,感谢建议
单机单线程可用本地数据数据库
当然数据库本身可能多线程事务处理
但查询对建立了索引的表来说应该是强项
我主要的问题是在内存上面,其实使用Key Value的方式效率我已经能接受了,主要就是实时反馈,效率上已经没问题了。我这个问题可能还展现不了这两个算法的优点,这两个算法复杂度比key Value的方式更高,但内存上,其实并没有减少,感谢您的建议,我再多观察观察