
众所周知,做游戏主要敌人之一就是渲染批次,批次越高,每帧销毁的时间可能就会越多,机器也就发热的厉害。一般的优化合批方案相信大家已经了解不少了,但是遇到类似于list,group之类的,里面有大量重复组件,但是里面又有文字、特效或者spine动画分层叠加,这时就会出现各种阻断合批,但是我们又不想改变原有逻辑和层级,或者改动起来非常麻烦。我们又该怎么做呢,这里就讨论下这种情况该怎么优化。
先看看效果:
优化前:
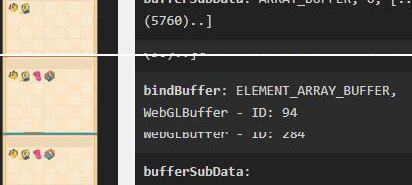
优化后:
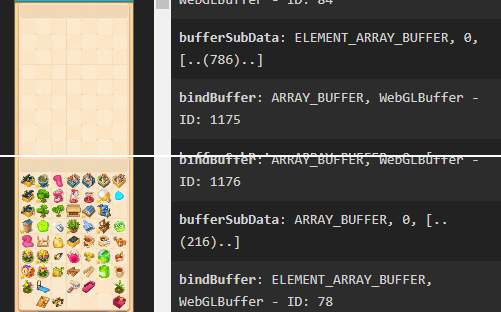
这只是其中一个主要模块的优化,优化后,drawcall减少了20%,之后再加上其他模块优化,保守估计总共能减少30%左右。
核心就在于需要重新排列渲染顺序,需要将组件中的重复类型一次绘制,这样就能让引擎将重复类型合批了。因此,我们需要修改ui的walk函数,这里不对引擎进行修改,直接对函数进行重写。
UI.prototype.walk = function(node: Node, level = 0) {
...
// 判定是否需要对节点进行优化
let data = node["__children_pref__"];
if(data) {
if (children.length > 0 && !node._static) {
// 将深度优先转换为广度优先
let caches: Node[][] = [];
for (let i = 0; i < children.length; ++i) {
let child = children[i];
if(child["__ignore_pref__"]) {
this.walk(child, level);
}else{
if(!child._static) {
if(data.level == 2) {
child = child.children[0];
}
for(let k=0;k<child.children.length;k++) {
if(!caches[k]) {
caches[k] = [];
}
caches[k].push(child.children[k]);
}
}
}
}
// 这里才真正的决定渲染顺序,将先渲染同类型节点
for(let i=0;i<caches.length;i++) {
let arr = caches[i];
for(let j=0;j<arr.length;j++) {
let oldLv = level;
this.walk(arr[j], level);
level = oldLv;
}
}
}
}else{
// 原递归函数,不需要优化的节点继续走此分支
if (children.length > 0 && !node._static) {
for (let i = 0; i < children.length; ++i) {
const child = children[i];
this.walk(child, level);
}
}
}
...
}
至此核心逻辑已经写完,接下来我们只需要暴露两个函数,就能做到一句代码进行渲染优化。
// 标记下此节点需要进行优化,
//childLevel 表示需要到达此节点下第几级才会渲染(针对fairygui的处理,而且只处理了等于2的情况,不要再walk中进行太多的逻辑操作,
// 注意:被跳过的层级节点将不会被渲染,如有需要自行处理)
export function preformanceNodeRenderer(node: Node, childLevel = 2) {
node["__children_pref__"] = {
level: childLevel,
};
}
// 标记那些节点不属于优化节点
export function ignorePreformance(node: Node) {
node["__ignore_pref__"] = true;
}
最终项目中,只需要一句代码就能优化列表类型的批次啦。
let root = this.bg_merge.node.children[0];
preformanceNodeRenderer(root);
ignorePreformance(root.children[0]);
下图展示我们项目中的列表层级:
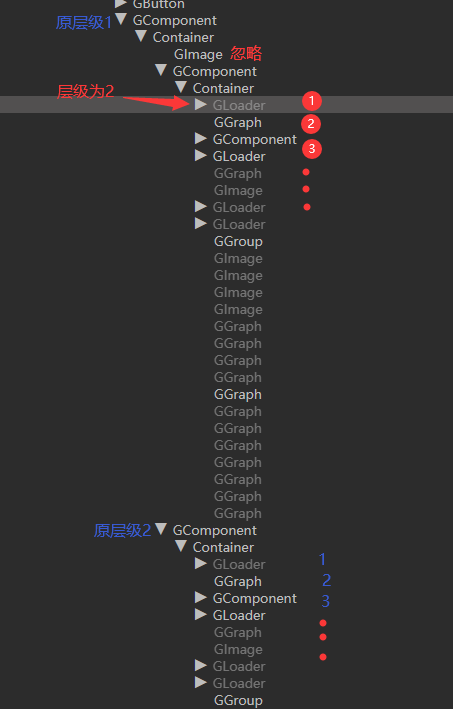
标有需要的层级将会在同一批次中渲染。
注意:
- 列表中的元素需要保持数量一直
- 不能改变列表中元素的顺序
- 同一层级的元素,需要相同图集相同材质球才能合批
- 列表元素间不要有重叠,否则造成层级错误
希望官方能为UI添加sortingOrder属性,这样就能通过改变值来改变渲染排序,实在不行将walk中的排序暴露出来,避免为了添加这个功能去覆盖引擎代码,造成代码浪费。
这里感谢下@ Bool Chen 在这篇帖子 性能优化1-列表渲染优化|社区征文 提供思路
