
大家好,我是晓衡!
上周我花了3天的时间,体验测试了一款 Creator 3.x 性能优化工具:98K动态分层合批 。
它能将 DrawCall 超过 1000+ 次的 2D 界面,实现运行时节点分层排序,利用引擎动态合图 + 批量渲染能力,从底层将 DrawCall 优化到个数位。
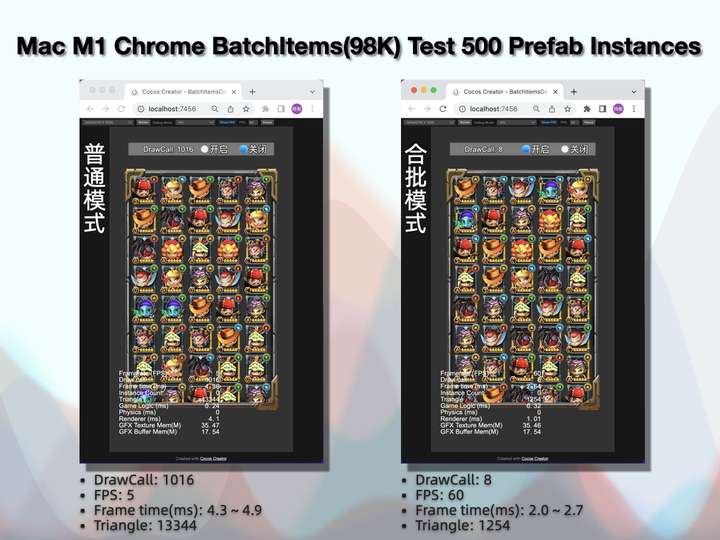
测试案例是一个 2D 背包界面,我在 ScrollView 中动态创建了 500 个 item 元素。你可以看到,开启合批优化后 DrawCall 从 1016 直接降到了 8,游戏帧率也从 5 帧直接拉满到 60 帧。
这里是H5测试体验链接,你也可以试一下:
- Cocos Creator | BatchItems 98K动态分层合批 支持H5、小游戏、原生等多个平台,而我的测试目标是,观察对比在不同平台环境上,使用 98K 优化前后的性能表现差异。
合批优化测试对比
先给出我的测试结果,一共测试了 7 个环境:
-
Mac M1 Chrome 桌面浏览器
-
realme X50 Pro Android 原生
-
realme X50 Pro Android 微信小游戏
-
OPPO R11s Plus Android 原生
-
OPPO R11s Plus Android 微信小游戏
-
iPhone11 微信小游戏
-
iPhone7 微信浏览器
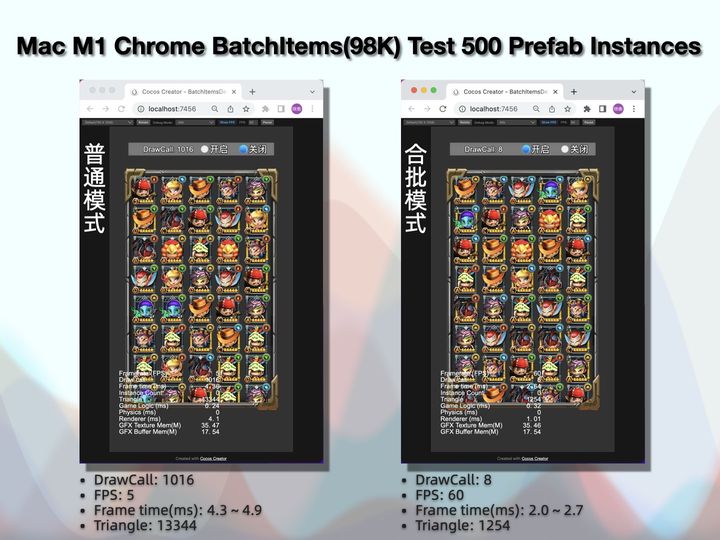





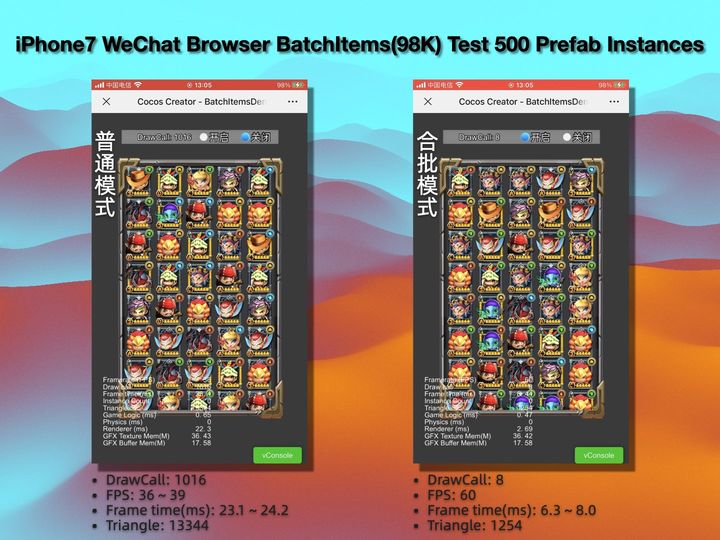
以上测试环境数据,我整理了个表格,方便大家对比优化关后的效果:
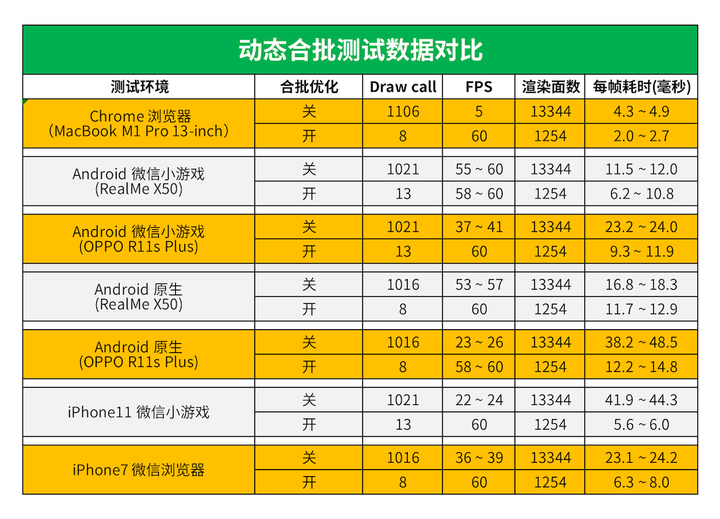
如果你觉得看数据表还是很费劲的话,可以直接看晓衡这个结论:
- 开启合批优化后,所有平台都能跑到 60 帧,ScrollView列表滑动流畅;
- 除减少 DrawCall 外,还启了渲染剔除,降低了渲染面数
- 优化前后差异对比是:Mac m1 Chrome > 低端原生 > 低端小游戏 > 中高端原生&小游戏
Mac m1 Chrome浏览器上的优化性能最佳,这是我万万没想到的,不论是 Mac 还是 Windows 系统,都是如此。未合批前仅仅只有 5 帧,在列表上滑动,非常卡顿,基本上无法使用。开启合批后,直接拉满到60帧,列表滑动流畅。
其次是在 iPhone 上,小游戏上的优化比浏览器要好,未合批前不到 30 帧,开启合批后满帧 60,列表滑动也更顺滑。
然后是在 Android 手机上,中高机型未合批前就能达到 50 ~ 60 帧,优化后提升不到 10 帧的样子,不看调试数值感觉不明显。低端机型的优化效果不错,有 20 ~ 30 帧的提升,硬件性能越低优化后的效果越好。
最后,我在多说一点,就是在 iPhone 和 Android 低配机型上,原生性能要低于H5和小游戏,优化效果会好。下面是我构建的 APK 安装包,感兴趣的伙伴可以来体验一下:
- 链接: https://pan.baidu.com/s/12aEvOL9fQrpyB4Xs--OALg?pwd=4znt 提取码: 4znt
测试数据和结论有了,我们再深入一点,98K动态分层合批的核心是对 DrawCall 的优化,初学游戏开发的小伙伴,可能会有疑问:
DrawCall 是什么?为什么减少 DrawCall 能提升游戏的性能?合批又是个什么鬼?
而有过游戏开发经验,又爱思考的老铁多半会问:
道具背包这类应用场景,一个 item 混合有复杂的图片、文字,98K是如何避免 DrawCall 被打断的?
下面我就来尝试一下,能否将上面几个问题说清楚,你可以更加清楚知道是否适合在自己的项目中使用98K合批优化。
理解Drawcall与合批
DrawCall 是什么?
- 简单来讲 CPU 准备好渲染数据,提交给 GPU 进行绘制的这个过程就是一次 DrawCall
为什么减少 DrawCall 能提升游戏的性能?
- GPU 渲染图像的速度非常非常快;
- CPU 的内存\显存读写、数据处理和渲染状态切换,相比 GPU 非常非常慢;
- 大量的 DrawCall 会让 CPU 忙到焦头烂额,而 GPU 大部分时间都在摸鱼。
因此,尽可能一次性将更多的渲染数据提交给 GPU,减少 CPU 的工作时间,从而提升游戏性能。
什么是合批?
- 简单来说,组织更多渲染数据提交给 GPU 的过程,称之为“批量渲染”简称“合批”;
- 但要实现合批的前提是:渲染数据必须一致。
更多关于 DrawCall 优化的理解,可以阅读陈皮皮的这篇文章:Cocos Creator 性能优化:DrawCall
举个例子
比如像下面这样的节点树结构,就无法实现合批:
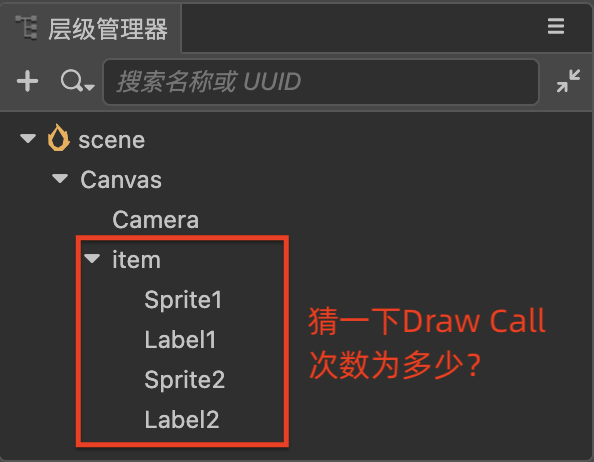
因为 item 节点下的 Sprite 与 Label 节点渲染类型不同,并相互间隔排列,引擎无法向 GPU 批量提交渲染数据。
因此渲染一个 item 需要 DrawCall 4次:Sprite → Label → Sprite → Label。
我们调整一下 item 下的节点顺序,像下面这样:
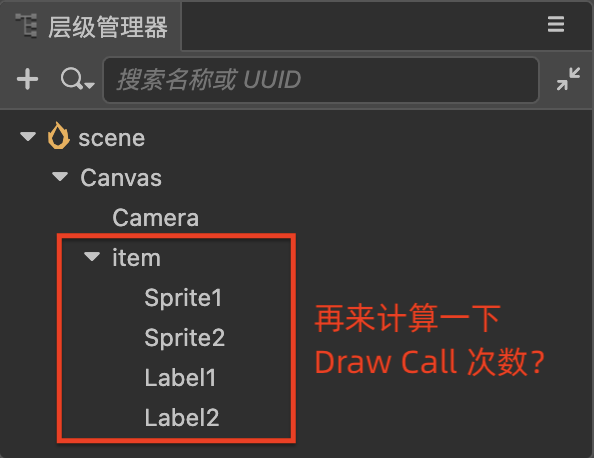
试试你能计算出上图中的 DrawCall 值吗?在 Creator 引擎中预览运行游戏,在画面左下角,你会看到 DrawCall 的值显示为 3。
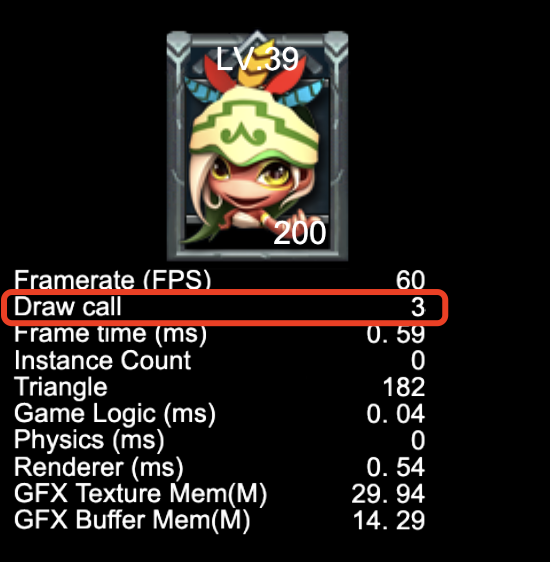
细心的你这时可能会问:为什么 DrawCall 是 3 而不是 2 呢?
不用怀疑,你计算的 DrawCall 为 2 是正确的,因为引擎这里会占用一次 DrawCcall,具体为什么,我们后面来说原因,你也可以思考一下!
98K是如何避免 DrawCall 被打断?
要想避免 DrawCall 被打断,首先要理解什么是 DrawCall 打断!
通过上面的举例,不知道你没有点感觉了。我们再来看多个 item 节点树 DrawCall 情况又会是怎么样的呢?
在层级管理器中,我们再复制一颗 item 节点树出来,见下图所示:
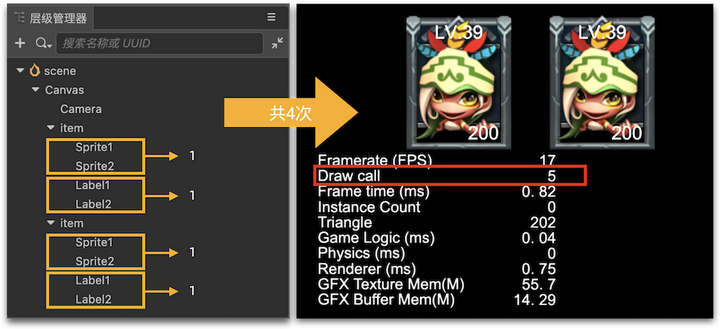
从上图可以看出,两颗 item 节点树时又出现:item1(Sprite → Label) → item2(Sprite → Label) 交替的情况,合批就这样被打断了。
聪明的我立马会想到,将所有 item 下的节点合并不就好了,像下图这样:
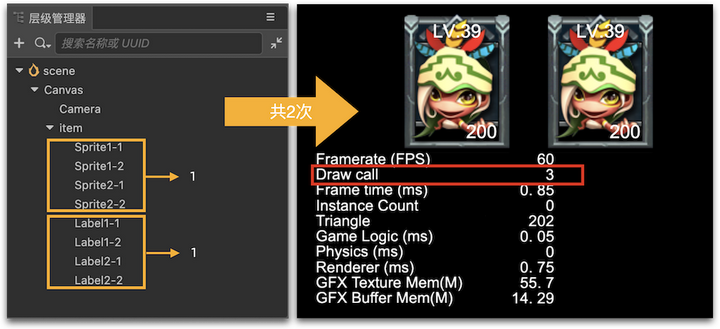
效果是不是很好?6 个节点只有 2 次 DrawCall !就这样干?
有经验的你问题又来了,我们的逻辑代码通常是以单个 item 为单位建立的对象,如果将类型节点点合并到一起,上层逻辑代码岂不是要乱成一锅粥?
优化的方法是知道了,但代价太大,不知道如何下手!
这个问题一直困扰我多年,一直没找到可行的解决方案,直到遇到98K动态合批的开发者。
这里不得不说下 98K动态合批 的强悍,就在于它可以让你无视 item 子节点顺序和层级关系,只需要在上层容器节点上添加 BatchItems 组件,最大程度上保证合批不被中断,实现该节点树的渲染优化。
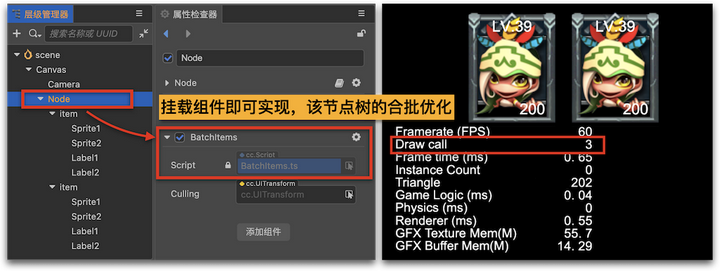
其代码实现原理是:
- 拦截引擎渲染开始事件,对节点树下的所有子节点按类型重新分层排序;
- 拦截引擎渲染结束事件,立即还原渲染前的节点树排序,从而实现无入侵式的合批优化;
- BatchItem组件唯一的 Culling 属性是可选的,它会拿 Culling 属性所指定的矩形区,与容器中 item 矩形做相交测试,将不在 Culling 区的元素从渲染队列中剔除掉。
应用场景
需要注意的是98K合批优化,仅适用于 2D UI 界面的优化,特别是具有大量重复结构的 item 场景如:背包系统、滑动列表、技能栏、聊天界面等,以下应用场景供大家参考。
背包系统
频道列表
游戏排行榜
聊天界面
04 注意事项
我在使用 98K编写前面那个背包测试工程时,踩到几个坑有几点需要注意:
-
item 下子节点名字不能重复需保持唯一性;
-
多个同结构的 item 子节点名字需要保持一致;
-
节点的 Layer 属性需保持相同,建议统一为 UI_2D;
-
需要手动开启引擎的动态合图和关闭清除图片缓存开关;
- dynamicAtlasManager.enabled = true;
- macro.CLEANUP_IMAGE_CACHE = false;
-
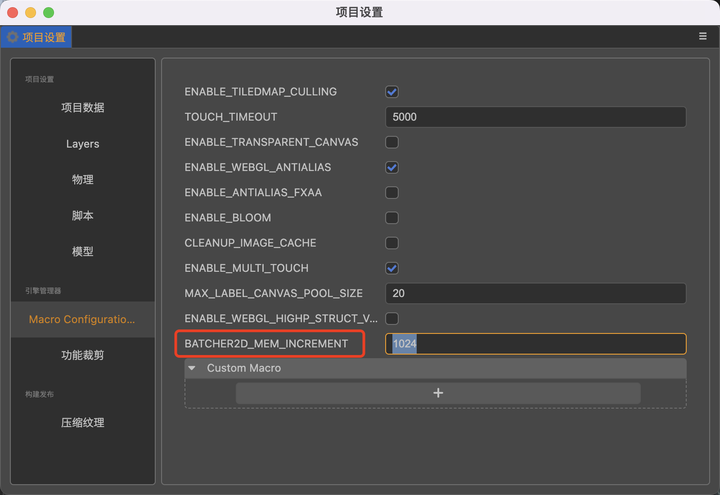
充分使用引擎的动态合图,将尽量多的图片合并,需要增大项目设置中 BATCHER2D_MEM_INCREMENT 宏的参数值
结语
最后,我再小结一下 98K动态分层合批 的整体感受!
它非常适用于像背包系统、滑动列表、聊天消息这类 2D UI 场景。
如果因游戏中因节点太多导致图文分层原因,打断合批造成 DrawCall 剧增影响性能和增加发热问题,98K合批可以说是首选的优化工具。
当然,你也可以使用虚拟列表的技术并不用创建出所有的 item,但我的感受是98K更为简单粗暴、立杆见影,能结合使用效果更定会更佳。
而从多个环境平台的测试效果来看:
- 桌面浏览效果最佳,如果你是做 H5 页游,那再适合不过
- 再次是 iPhone 浏览器、小游戏优化效果显著
- 然后是中低端的 Android 也比较推荐
下面是 H5 | Android 测试链接,强烈建议你也来体验一下,欢迎留言说说在你的设备上体验感受。
H5测试链接:
Android测试包下载
- 链接: https://pan.baidu.com/s/12aEvOL9fQrpyB4Xs--OALg?pwd=4znt 提取码: 4znt
Cocos Store下载链接
希望晓衡的分享能够对大家有所帮助和启发, 我会继续挖掘 Cocos Store 上的优秀作品分享给大家。动态合批还有哪些更多应用场景呢?欢迎一起来讨论!