ai生成一张图片只需要几分钟,现在克隆音色,我们也只需要几分钟的时间。
这个得感谢国内大神开发的一款大模型,想要下载这个大模型的,自己可以去Github上下载,Github 链接:https://github.com/RVC-Boss/GPT-SoVITS。
下面我们来讲解一下这个模型的用法。
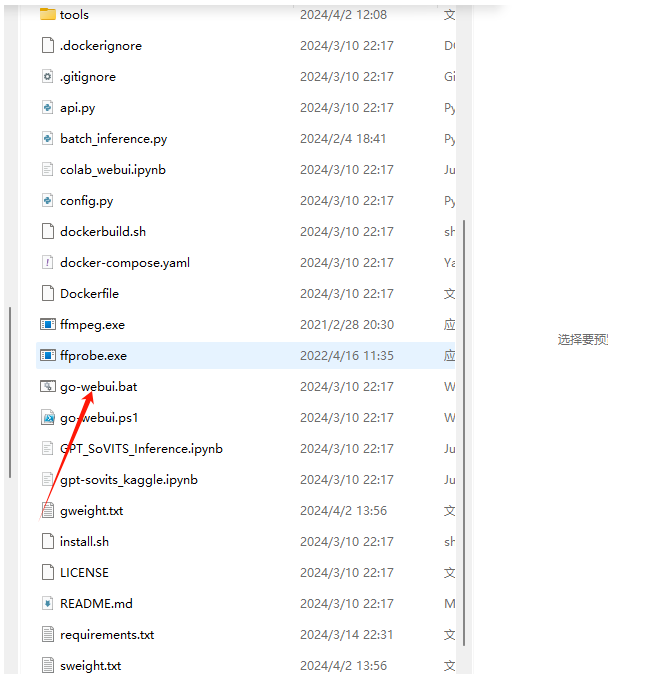
第一:解压运行。只想用它的功能的我们可以直接下载整合包,下载完后,我们先解压整合包,直接打开go-webui.bat文件。
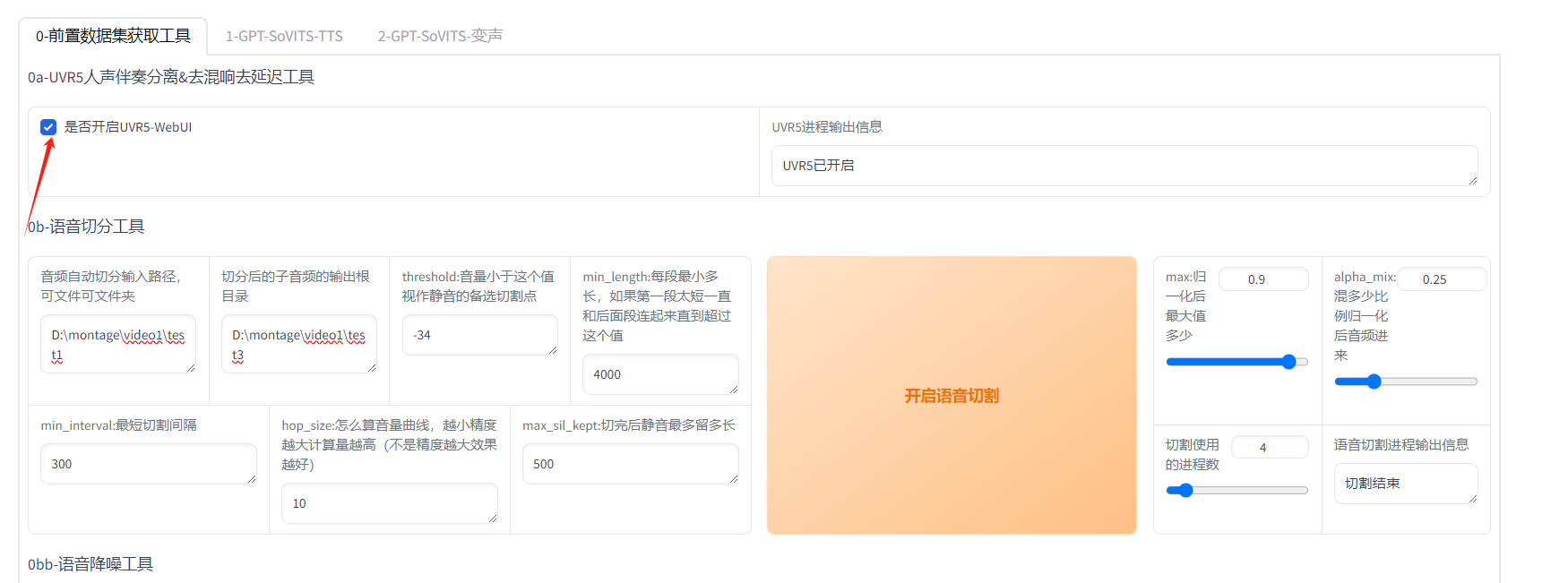
第二:人声分离。进入网页版,然后我们把要克隆的音频下载好,第一步先做人声分离,把需要的人声分离出来。把是否开启UVR5-WebUI这个开关打开就会进入人声分离界面。
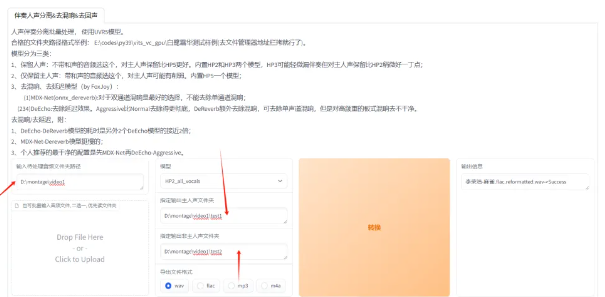
目录最好不要有中文名称,提前建好人声保存的目录和背景音保存的目录。
第三:切割音频。在切割音频前建议把所有音频拖进音频软件(如au、剪映)调整音量,最大音量调整至-9dB到-6dB,过高的删除。在切割里面,我们参数保持默认就可以了。
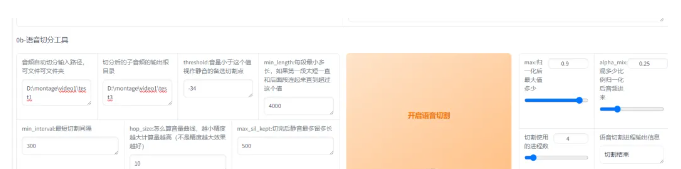
第四:给音频打上文字标注。打标就是给每个音频配上文字,这样才能让AI学习到每个字该怎么读。我们要做的就是配好切割完的音频输入目录,输出目录就好。

运行一下就会生成一个list文件。
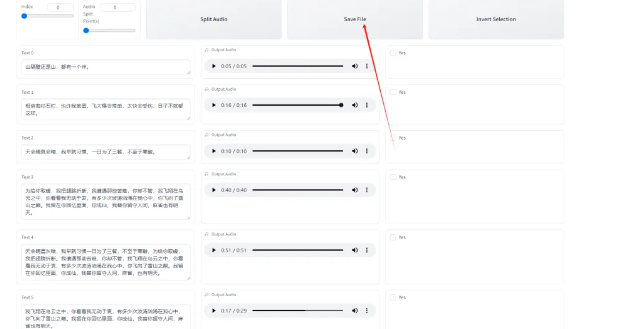
第五:文本标注校对。打开这个勾就会进入文本校对界面。

把文本校对好之后,按一下save file把文件保存下来。
第六:对音频预处理完,我们点击第二列,对模型进行训练和生成。
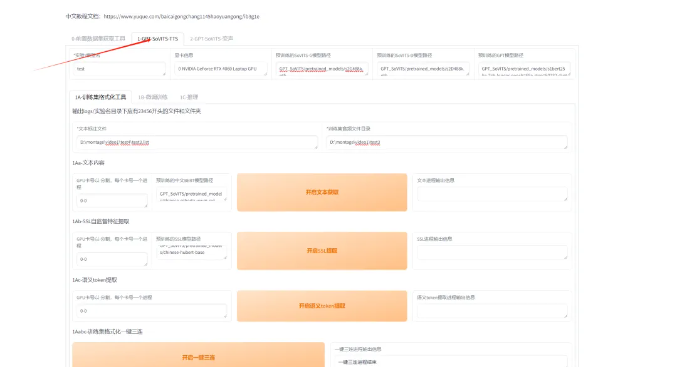
首先我们先把模型名字命名好,然后把文本标注文件和音频文件的目录填写进去,点击一键三连。
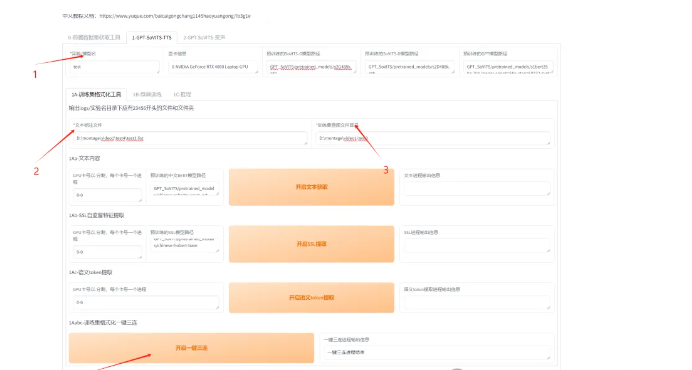
第七:对模型进行微调,点击微调模型的按钮,对模型进行微调,还有batch_size不要太高,高了会爆显存。
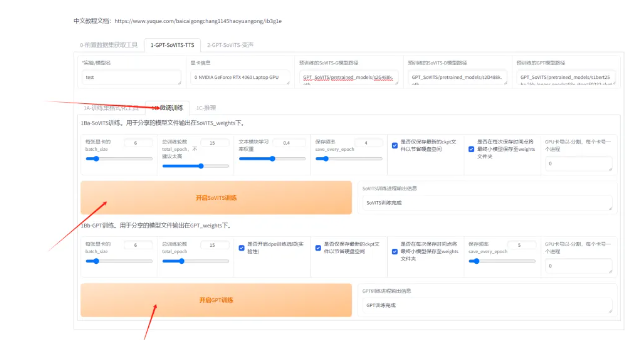
第八:利用模型生成音频。点击推理的按钮,打开推理ui界面,我们就可以利用自己的模型生成音频了。
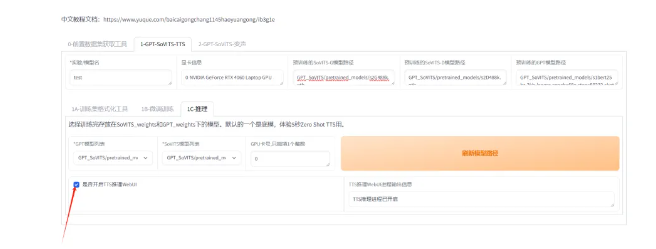
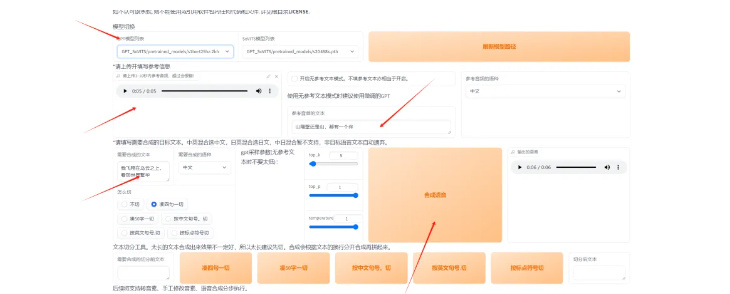
第九:生成目标音频。找到我们生成的模型,然后添加一段参考音频,把音频文字写上去,在下面输入我们要生成音频的文本,最后点击合成语音,这样我们就完整地克隆了一个音色。