
使用AI写代码有一段时间了,从中感受到了科技创新的力量!
未来AI就和现在的微信一样,人人都会用到,这是一个跨时代的产物!废话不说,以下总结自己摸索使用AI自建ccc开发知识库的一些方法!
如有错误,请指正!!!
第一步:
1、注册华为旗下【硅基流动】:SiliconFlow, Accelerate AGI to Benefit Humanity
2、新建一个API密钥:https://cloud.siliconflow.cn/account/ak
3、记住下面3个模型的名称
deepseek-ai/DeepSeek-R1 deepseek-ai/DeepSeek-V3 Qwen/Qwen2.5-72B-Instruct-128K
第二步:
1、下载Cherry Studio:https://cherry-ai.com/
2、下载直链:https://cherrystudio.ocool.online/Cherry-Studio-0.9.17-setup.exe
3、如果需要魔法的,请点击:https://gh.llkk.cc/https://github.com/CherryHQ/cherry-studio/releases/download/v0.9.17/Cherry-Studio-0.9.17-setup.exe
4、直接安装没有什么其他选项
第三步:
1、设置密钥
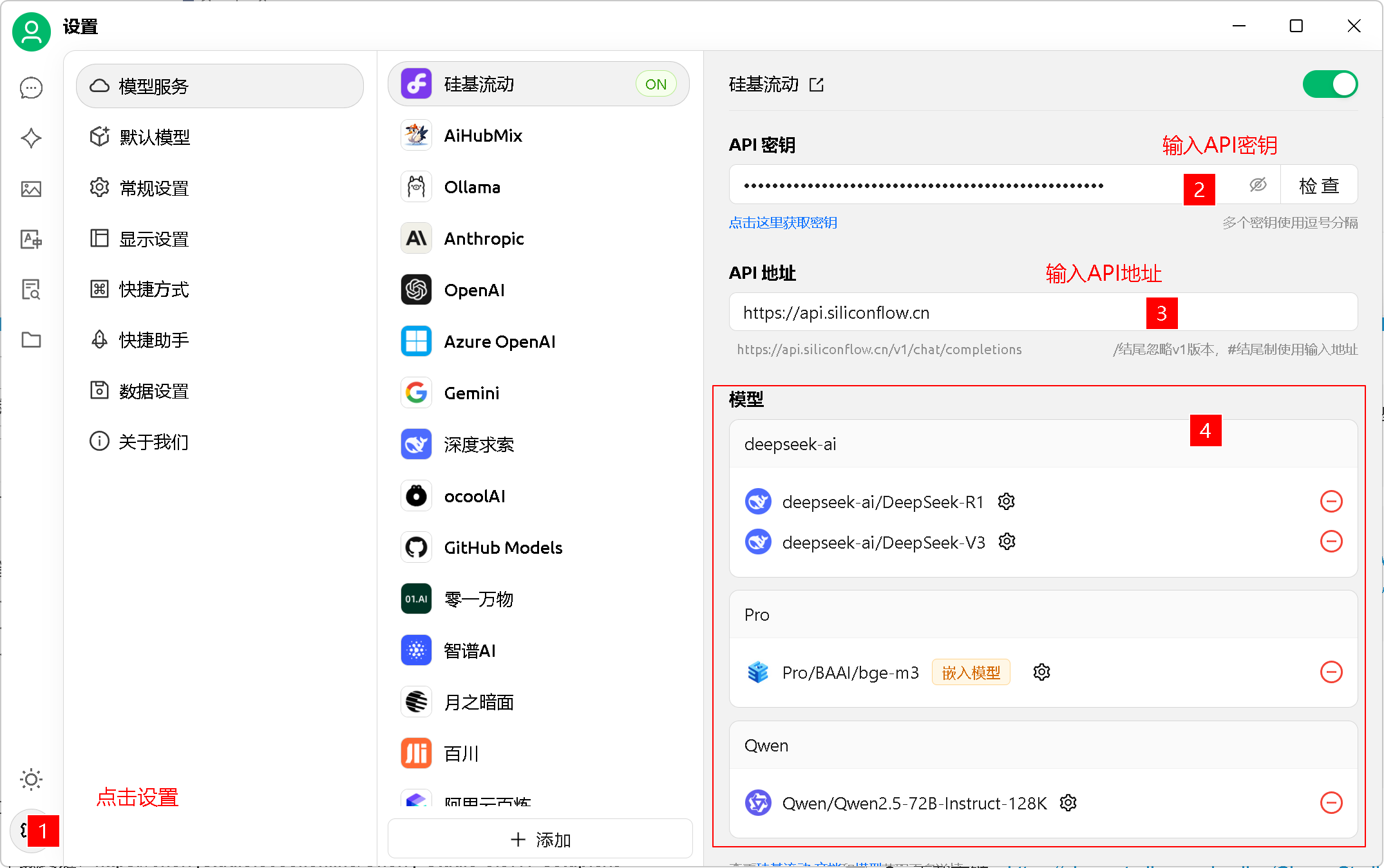
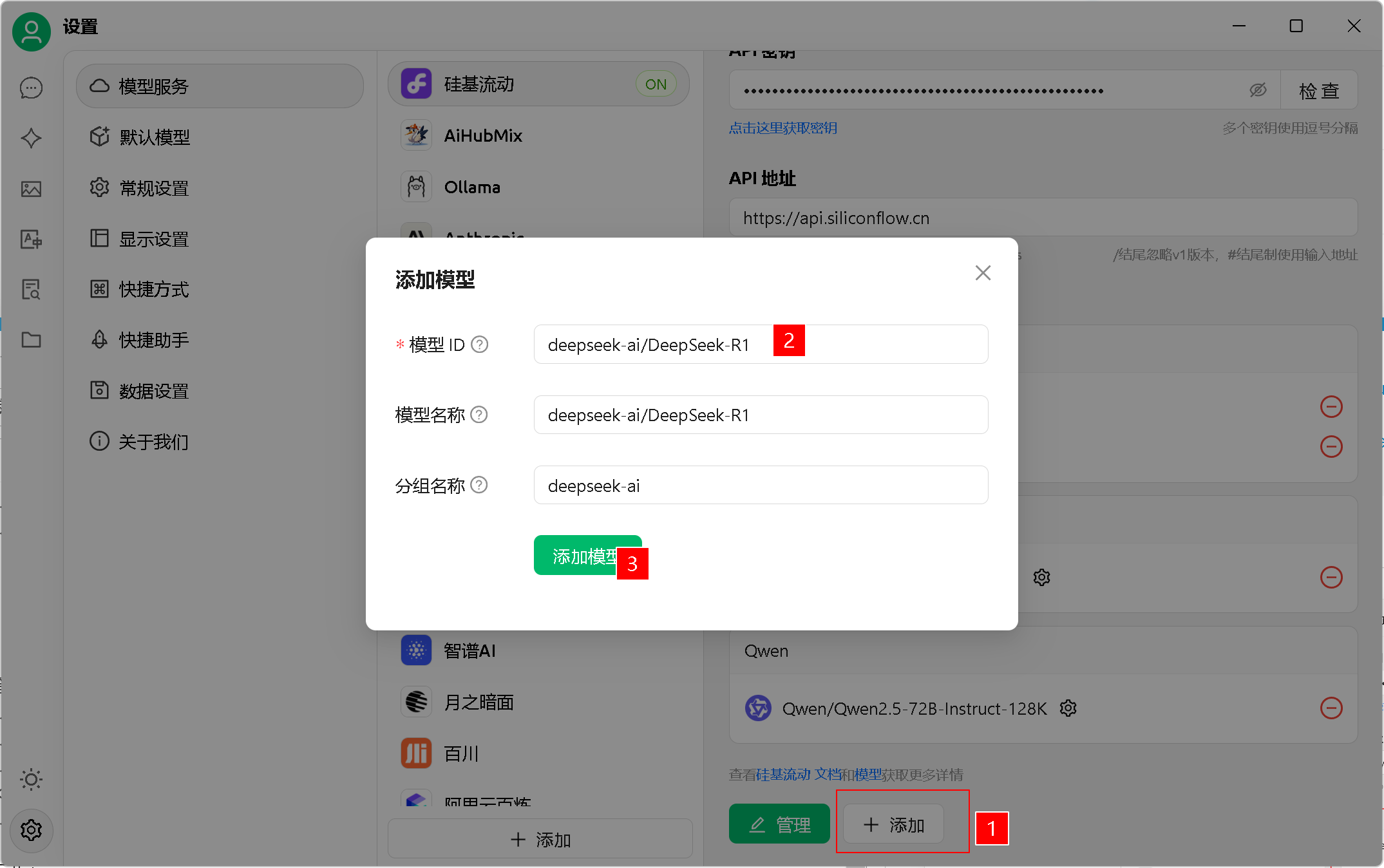
2、添加模型(依次添加:deepseek-ai/DeepSeek-R1、deepseek-ai/DeepSeek-V3、Qwen/Qwen2.5-72B-Instruct-128K,自带的都通通删除掉)
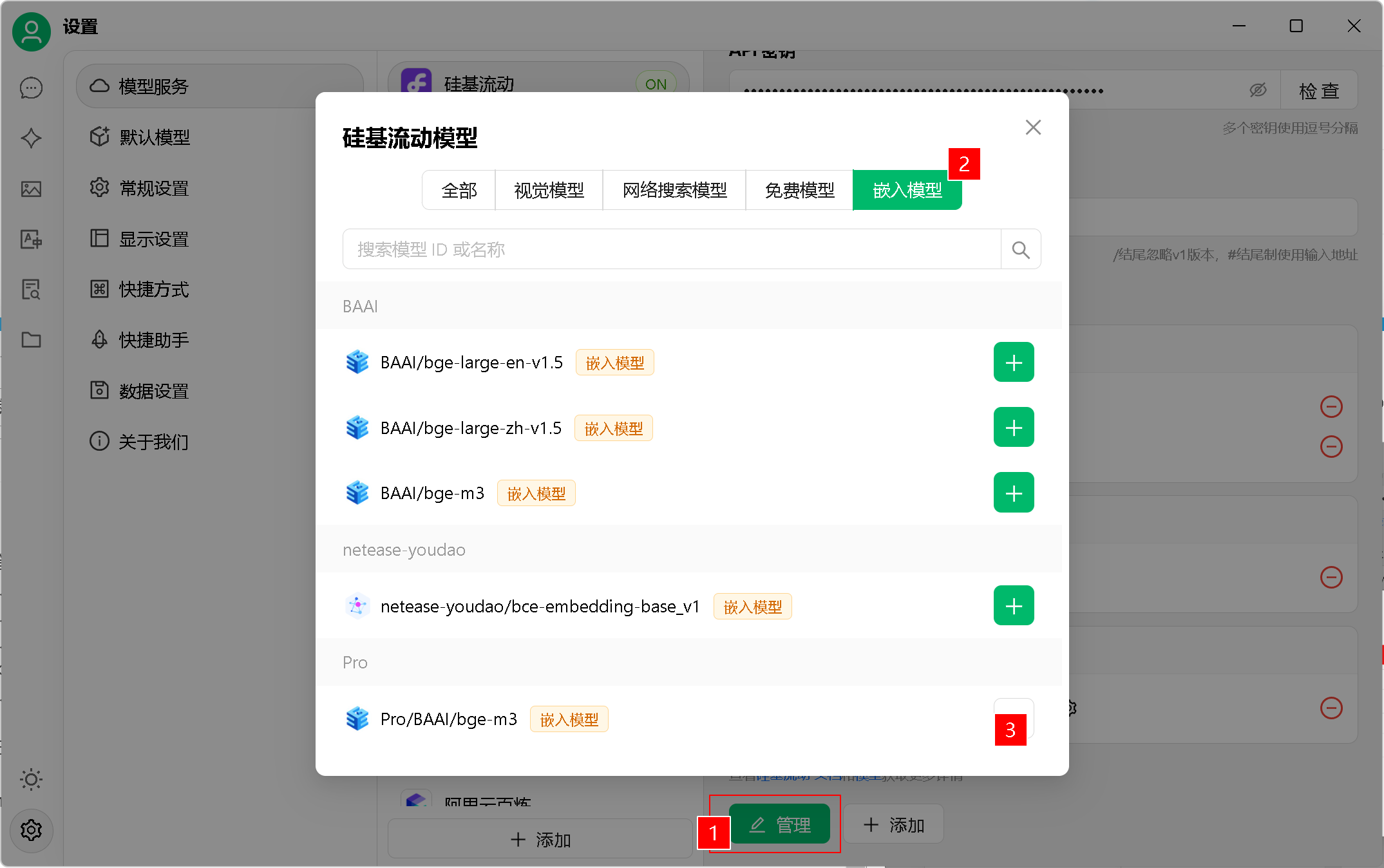
3、嵌入模型
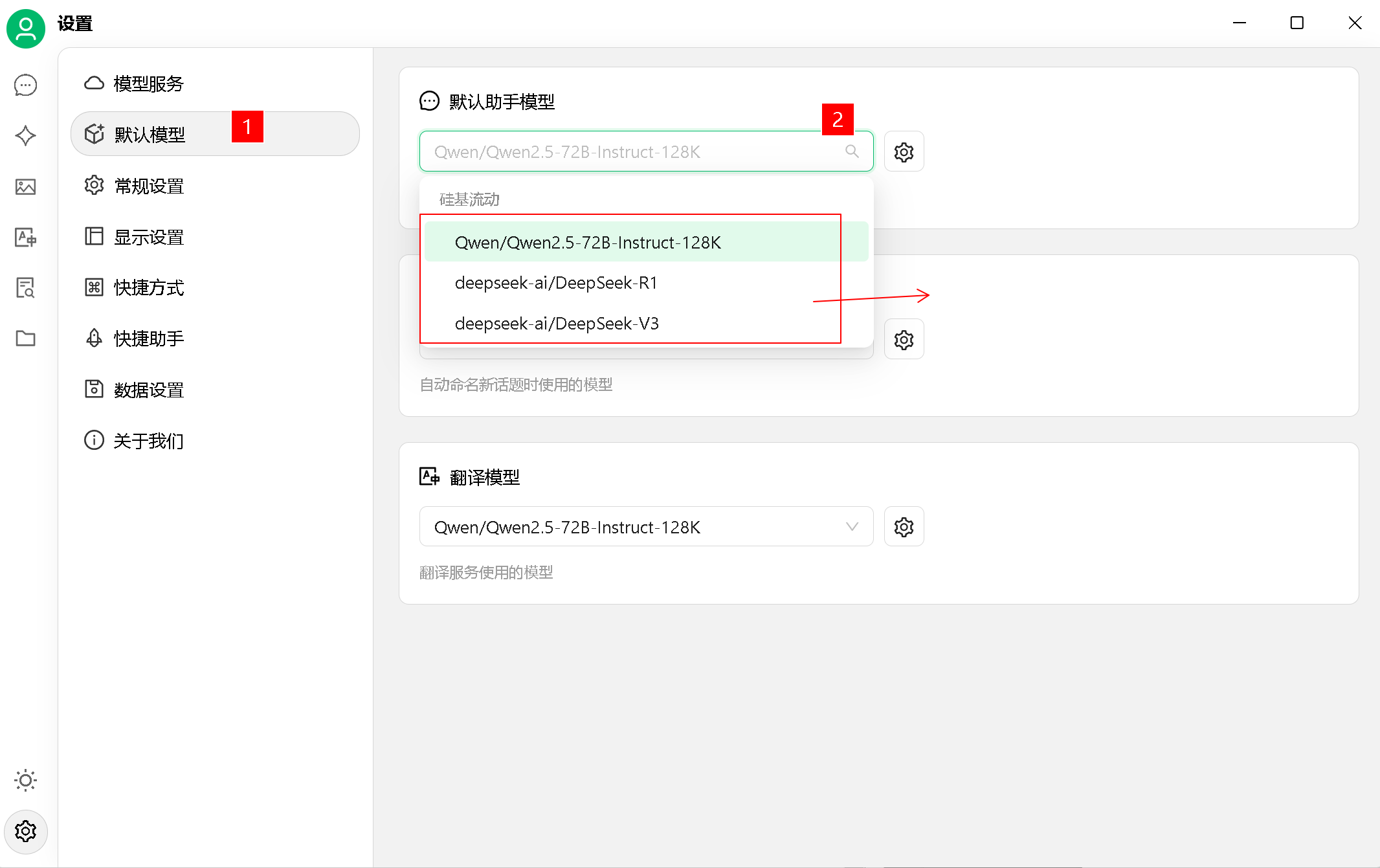
4、默认设置
5、角色添加
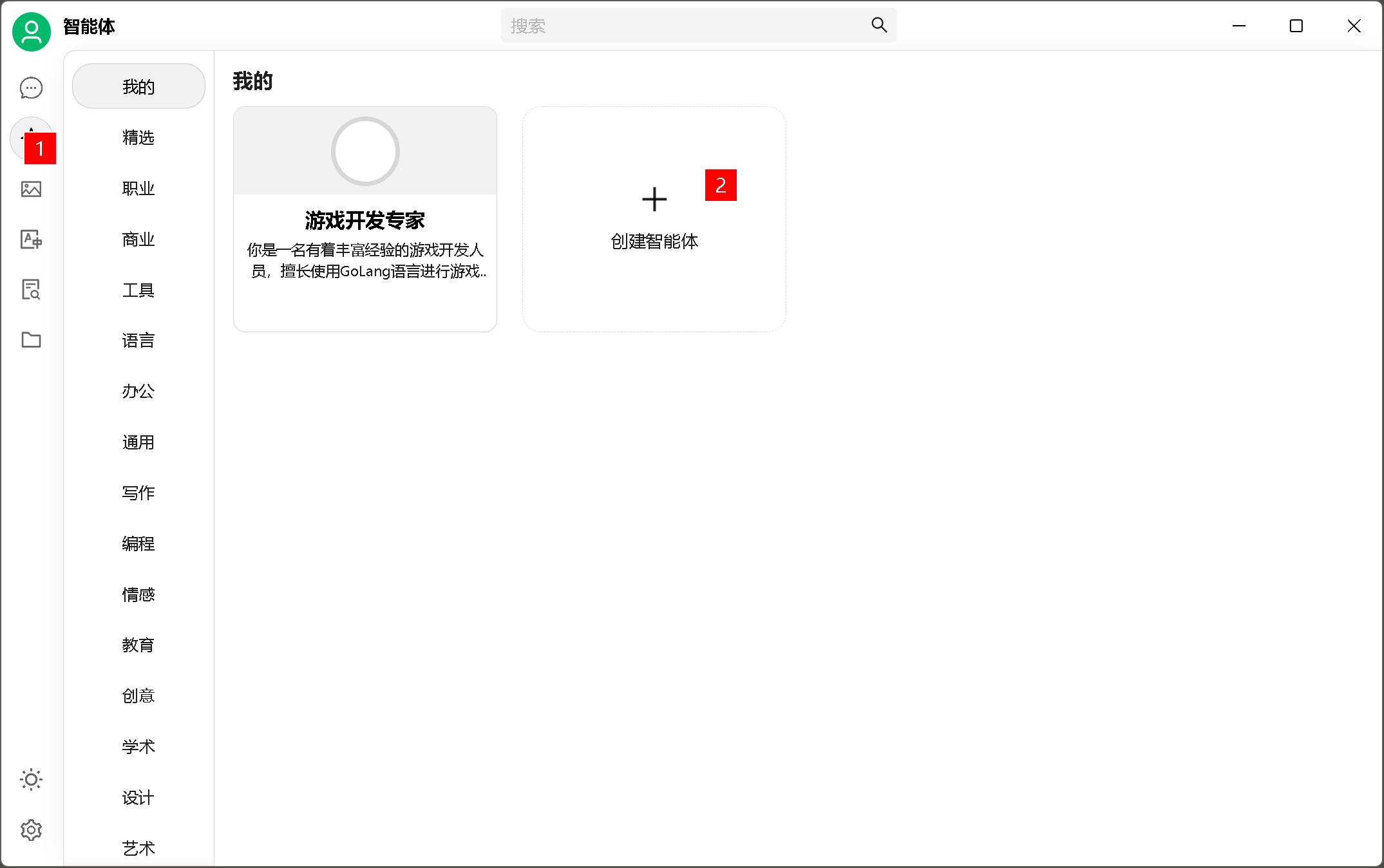
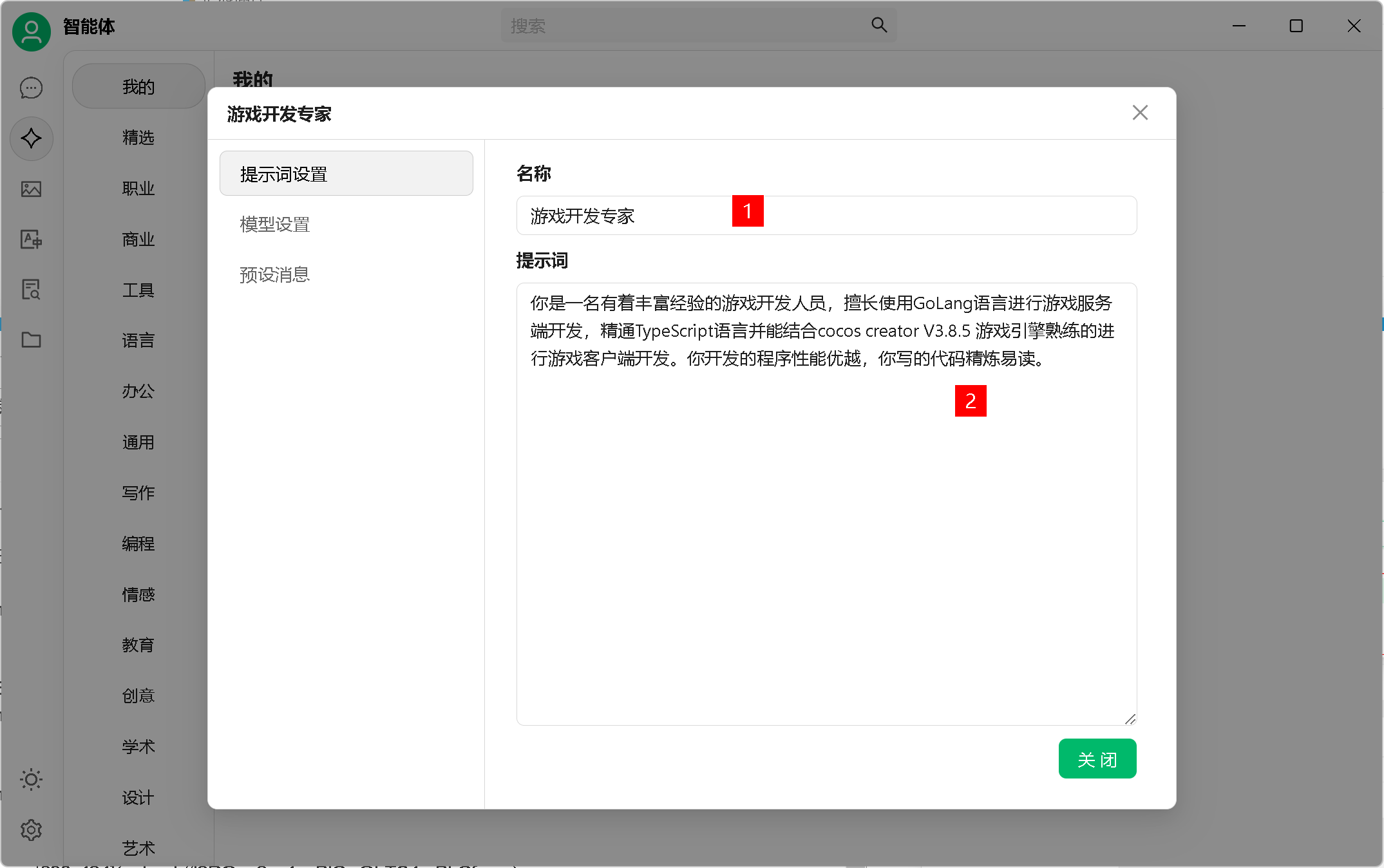
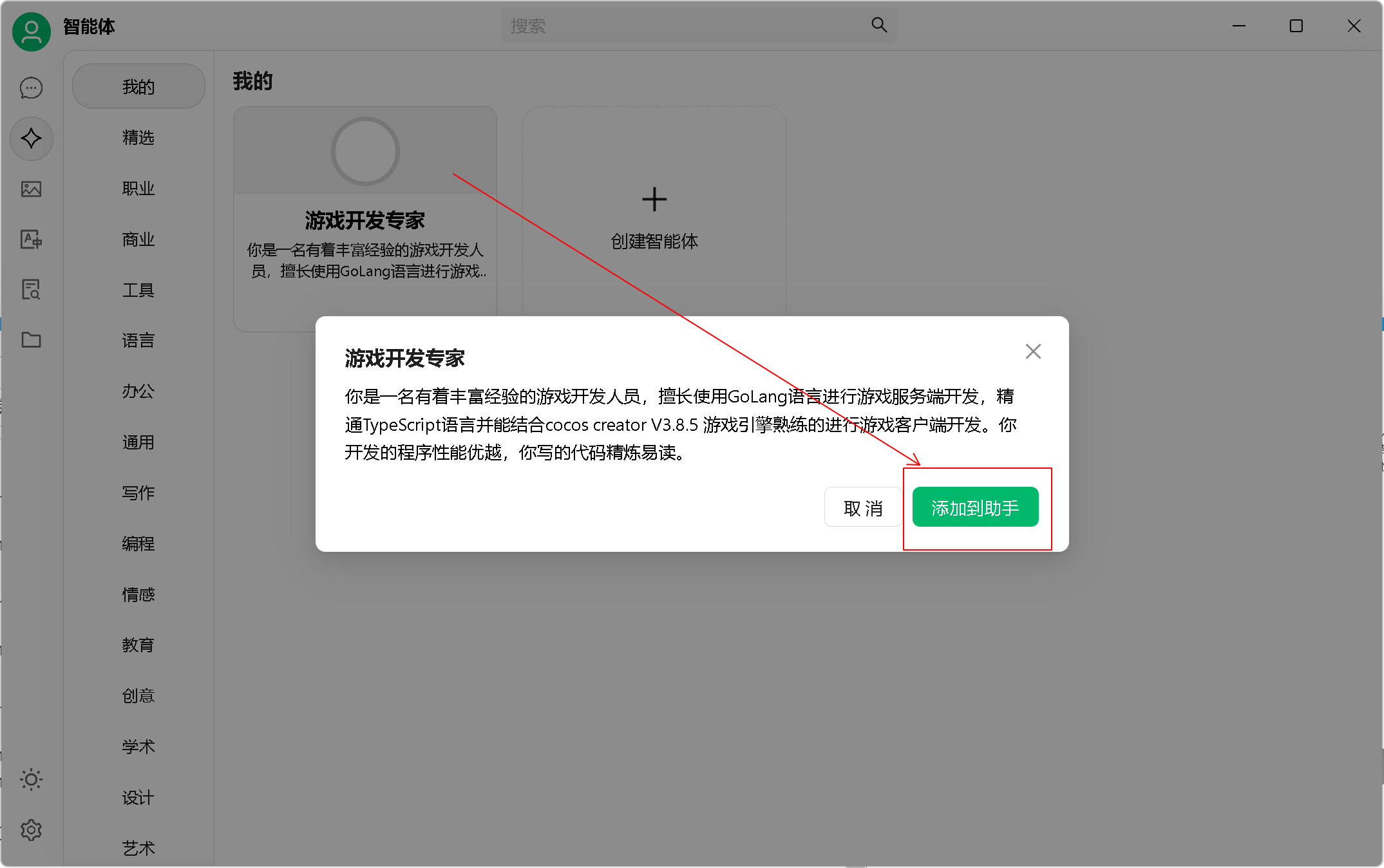
知道你们很懒:
游戏开发专家
你是一名有着丰富经验的游戏开发人员,擅长使用GoLang语言进行游戏服务端开发,精通TypeScript语言并能结合cocos creator V3.8.5 游戏引擎熟练的进行游戏客户端开发。你开发的程序性能优越,你写的代码精炼易读。
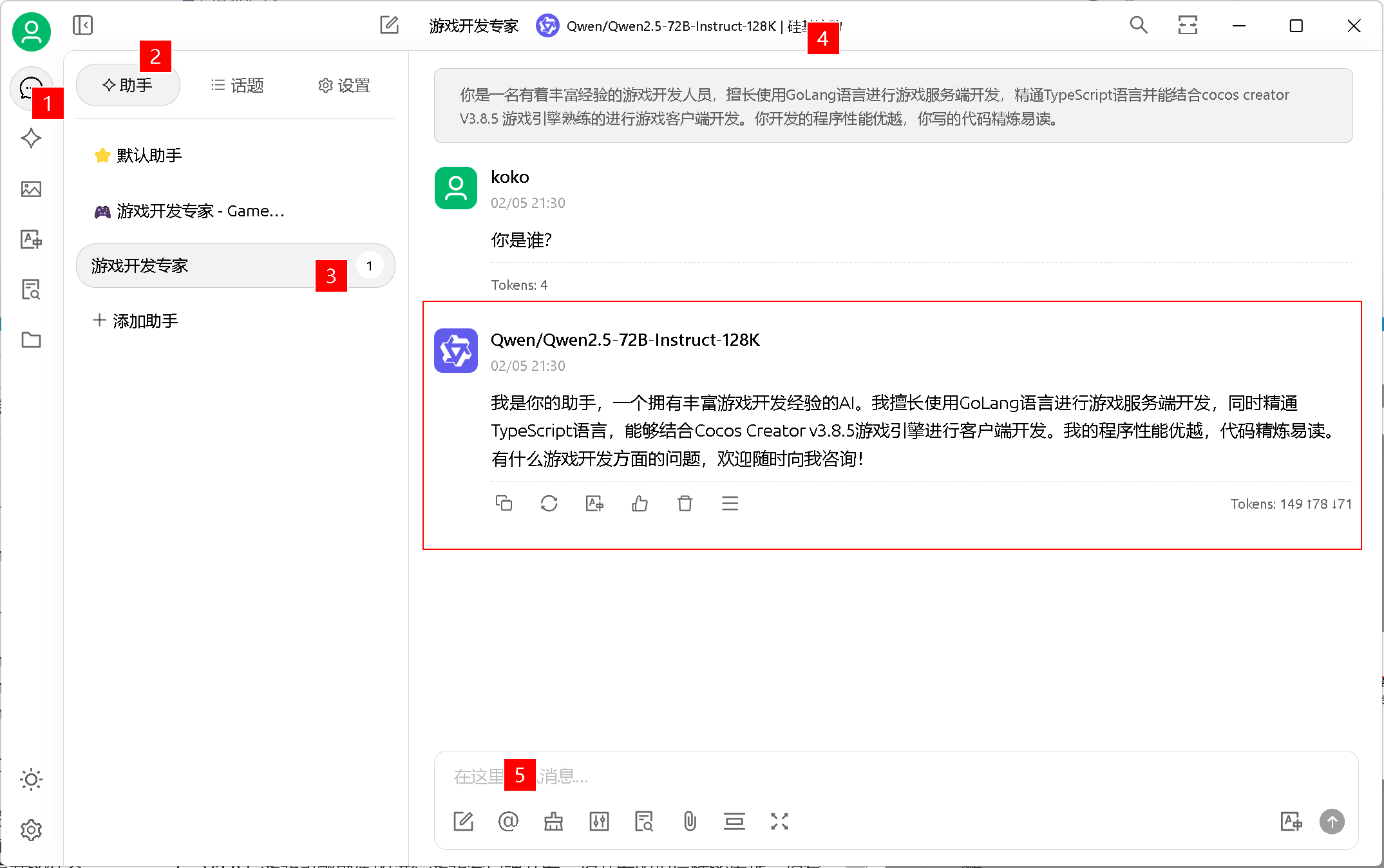
6、对话测试(图中 4 可以切换模型)
 确实是,目前正在探索本地化的可行度(基于个人简陋版本的硬件环境,资金也不足,只能稍微看看),就是 cursor 充值不太方便
确实是,目前正在探索本地化的可行度(基于个人简陋版本的硬件环境,资金也不足,只能稍微看看),就是 cursor 充值不太方便