以下式DeepSeek自己回答的:
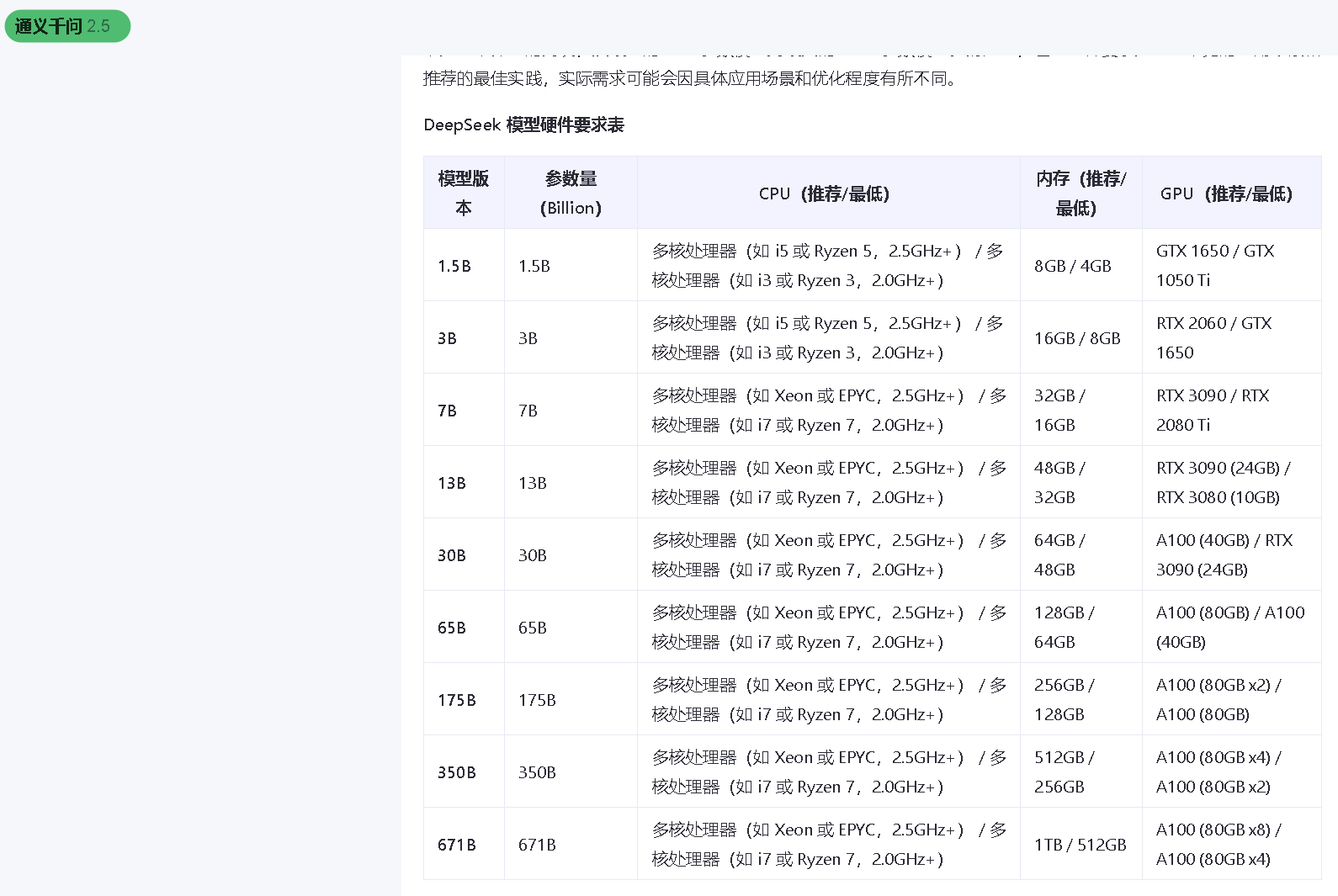
DeepSeek-R1 模型的不同版本在硬件配置上有显著差异,具体需求如下(按参数规模从小到大排列,结合多个来源整理)153:
1. DeepSeek-R1-1.5B
-
CPU : 最低 4 核(推荐 Intel/AMD 多核处理器)
-
内存 : 8GB+
-
硬盘 : 3GB+ 存储空间(模型文件约 1.5-2GB)
-
显卡 : 非必需(纯 CPU 推理);若 GPU 加速可选 4GB+ 显存(如 GTX 1650)
-
适用场景 : 低资源设备部署(树莓派、旧款笔记本)、实时文本生成(聊天机器人、简单问答)
-
显存优化 : 若使用 INT4 量化,显存占用可降至 0.75GB 7。
2. DeepSeek-R1-7B
-
CPU : 8 核以上(推荐现代多核 CPU)
-
内存 : 16GB+
-
硬盘 : 8GB+(模型文件约 4-5GB)
-
显卡 : 推荐 8GB+ 显存(如 RTX 3070/4060)
-
适用场景 : 中小型企业本地开发测试、中等复杂度 NLP 任务(文本摘要、翻译)、轻量级多轮对话系统
-
显存优化 : INT4 量化后显存占用 3.5GB 7。
3. DeepSeek-R1-8B
-
CPU : 8 核以上(推荐现代多核 CPU)
-
内存 : 16GB+
-
硬盘 : 8GB+(模型文件约 4-5GB)
-
显卡 : 推荐 8GB+ 显存(如 RTX 3070/4060)
-
适用场景 : 需更高精度的轻量级任务(代码生成、逻辑推理)
-
备注 : 硬件需求与 7B 相近,但性能提升约 10-20%1。
4. DeepSeek-R1-14B
-
CPU : 12 核以上
-
内存 : 32GB+
-
硬盘 : 15GB+
-
显卡 : 16GB+ 显存(如 RTX 4090 或 A5000)
-
适用场景 : 企业级复杂任务(合同分析、报告生成)、长文本理解与生成
-
显存优化 : FP16 精度需 28GB 显存 ,INT4 量化后降至 7GB 73。
5. DeepSeek-R1-32B
-
CPU : 16 核以上(如 AMD Ryzen 9 或 Intel i9)
-
内存 : 64GB+
-
硬盘 : 30GB+
-
显卡 : 24GB+ 显存(如 A100 40GB 或双卡 RTX 3090)
-
适用场景 : 高精度专业领域任务(医疗/法律咨询)、多模态任务预处理
-
显存需求 : FP16 精度需 64GB 显存 ,使用 4-bit 量化可降至 16GB 71。
6. DeepSeek-R1-70B
-
CPU : 32 核以上(服务器级 CPU)
-
内存 : 128GB+
-
硬盘 : 70GB+
-
显卡 : 多卡并行(如 2×A100 80GB 或 4×RTX 4090)
-
适用场景 : 科研机构/大型企业(金融预测、大规模数据分析)、高复杂度生成任务
-
显存需求 : FP16 精度需 140GB 显存 ,需多卡分布式推理或量化至单卡运行35。
7. DeepSeek-R1-671B
-
CPU : 64 核以上(服务器集群)
-
内存 : 512GB+
-
硬盘 : 300GB+
-
显卡 : 多节点分布式训练(如 8×A100/H100)
-
适用场景 : 国家级/超大规模 AI 研究(气候建模、基因组分析)、通用人工智能(AGI)探索
-
显存需求 : FP16 精度需 1342GB 显存 ,需多节点并行或极端量化优化17。
通用建议与优化策略
-
量化技术 :使用 4-bit/8-bit 量化可降低显存占用 30-50%17。
- 例如,32B 模型通过 4-bit 量化后,显存需求从 64GB 降至 16GB。
-
推理框架 :搭配 vLLM、TensorRT 等加速库提升效率13。
-
云部署 :70B 及以上模型建议优先考虑云服务(如华为云昇腾服务),以弹性扩展资源58。
-
能耗与散热 :32B+ 模型需高功率电源(1000W+)和散热系统1。
适用场景与性价比推荐
-
个人/中小企业 :1.5B-14B 版本性价比高,适合本地部署5。
-
专业领域/企业级 :32B 及以上版本需高性能硬件,适合复杂任务26。
-
超大规模研究 :671B 需分布式集群,建议结合云端资源15。
如需更详细的量化显存计算或训练需求,可参考官方文档或工具(如 model_memory_usage )