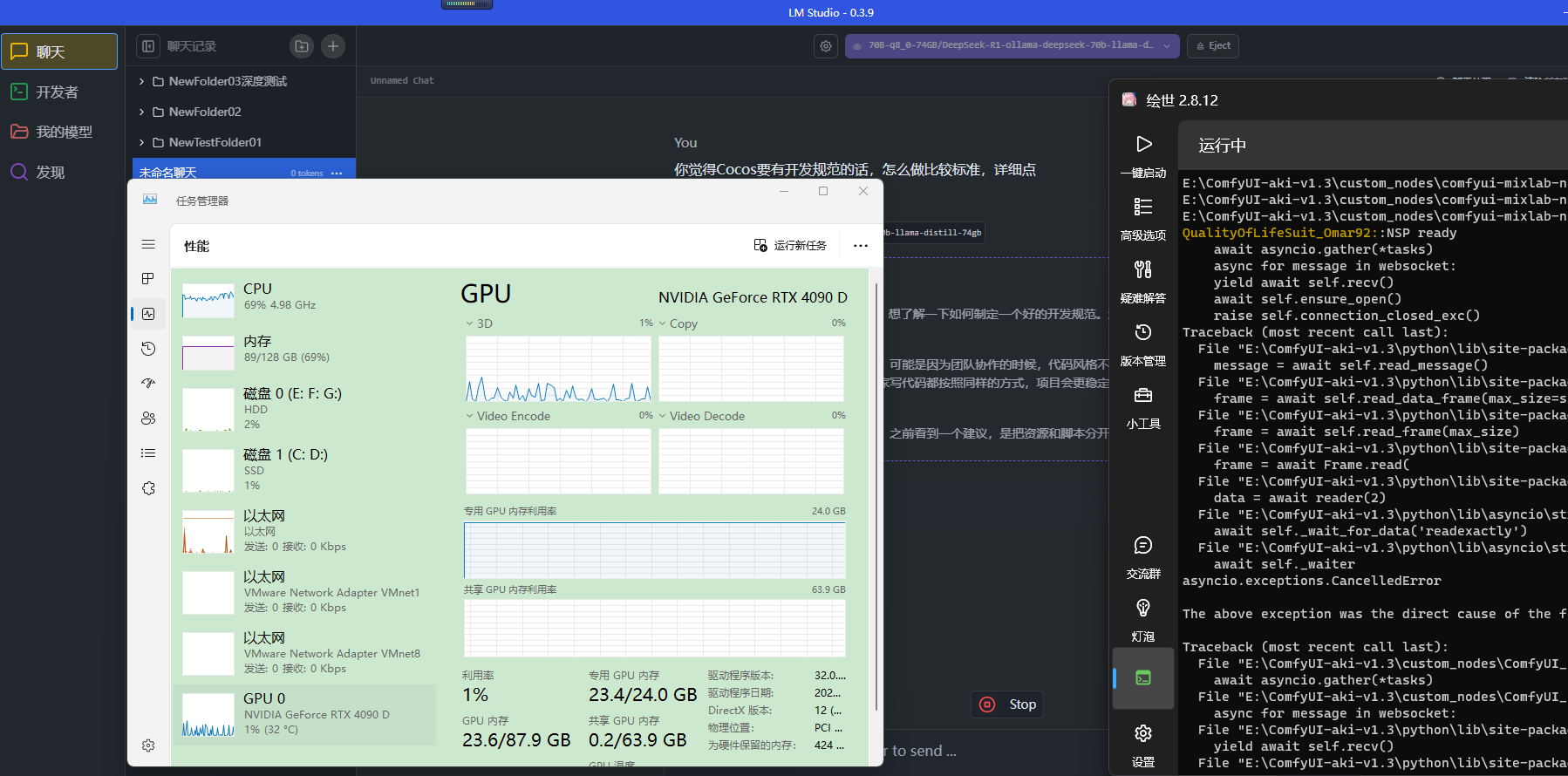
感兴趣的兄弟也可以测下,选用 LM Studio 的原因是方便部署点,
可以自定义 API 本地处理响应,对一些工程或者文档进行本地化处理和训练,
采用 RAG 进行本地文档传入和辅助分析比较方便:
推荐这个插件可以结合 ollama 进行分析和对话,也可以传入 RAG 内容,
不过感觉没 LM Studio 好用:
Page Assist - 本地 AI 模型的 Web UI

感兴趣的兄弟也可以测下,选用 LM Studio 的原因是方便部署点,
可以自定义 API 本地处理响应,对一些工程或者文档进行本地化处理和训练,
采用 RAG 进行本地文档传入和辅助分析比较方便:
推荐这个插件可以结合 ollama 进行分析和对话,也可以传入 RAG 内容,
不过感觉没 LM Studio 好用:
Page Assist - 本地 AI 模型的 Web UI
结论:整体来说对显卡的运算的要求不怎么高
甚至我后台挂了个 comfyUI 在运行,基本上也还行
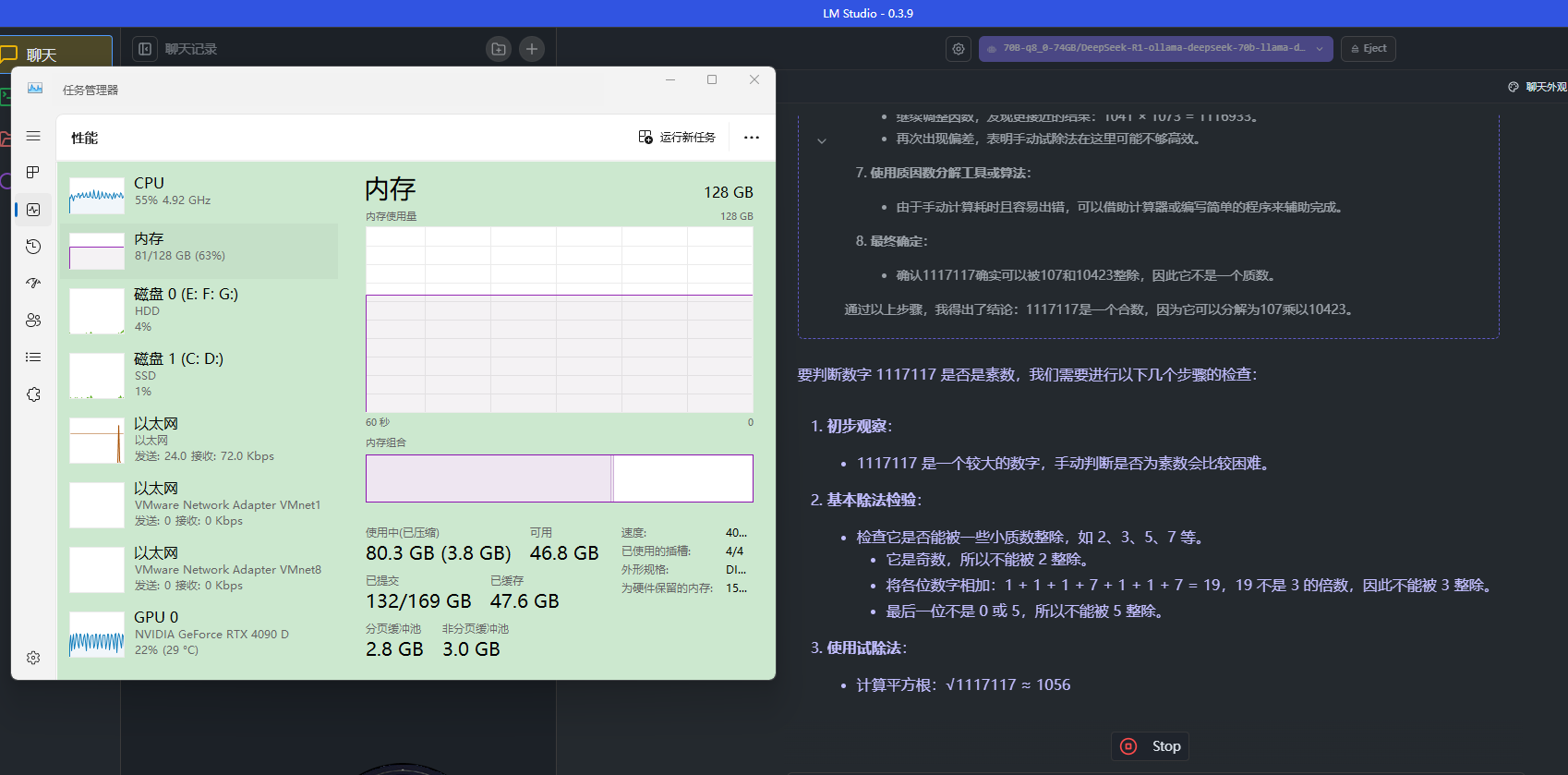
这个 69.83 GB 的本地 Deepseek 的模型,虽然我的 128 GB 的内存条还算OK,但是压力很大,运行起来感觉很吃力,有时候会运算到占用 115GB 内存的情况,对显卡倒是没太大要求,然后这个运行起来,很慢,出的回答,基本上就是每秒 5~15 个字左右。
综上所述:
如果运行的是 20 GB 左右的模型,基本上回复就比较快,感觉比较流畅,30GB 的也可以,所以如果对思考的算力和逻辑要求不高的兄弟,可以考虑部署一个 1/4 左右内存条的模型:
比如说 16 GB 的内存条,可以部署默认的 Deepseek R1 1.5b 模型(1.1 GB ),运行起来还是很流畅的。
变量名:OLLAMA_HOST
变量值:0.0.0.0:11434
变量名:OLLAMA_MODELS
变量值:G:\OLLAMA_MODELS
后续补充下关于 Unity 新出的 UnityMCP 的内容,听说可以直接联合 AI 生成场景和代码了
刚开始看到你说搞8B,我就想逼叨两句。
后面果然上了一点强度 70B。
在做成服务器,分个网页版给自己或公司可以远程、手机用?
目前已经可以内网使用了,在考虑穿透试试数据关联域名访问
也在探索集成本地的合适的蒸馏模型做到游戏里面离线运行
占用空间:70 GB
测试内容:分析多个网页内容,给出结论和方案:
本地思考-耗时:14 分钟
本地输出方案-耗时:10 分钟
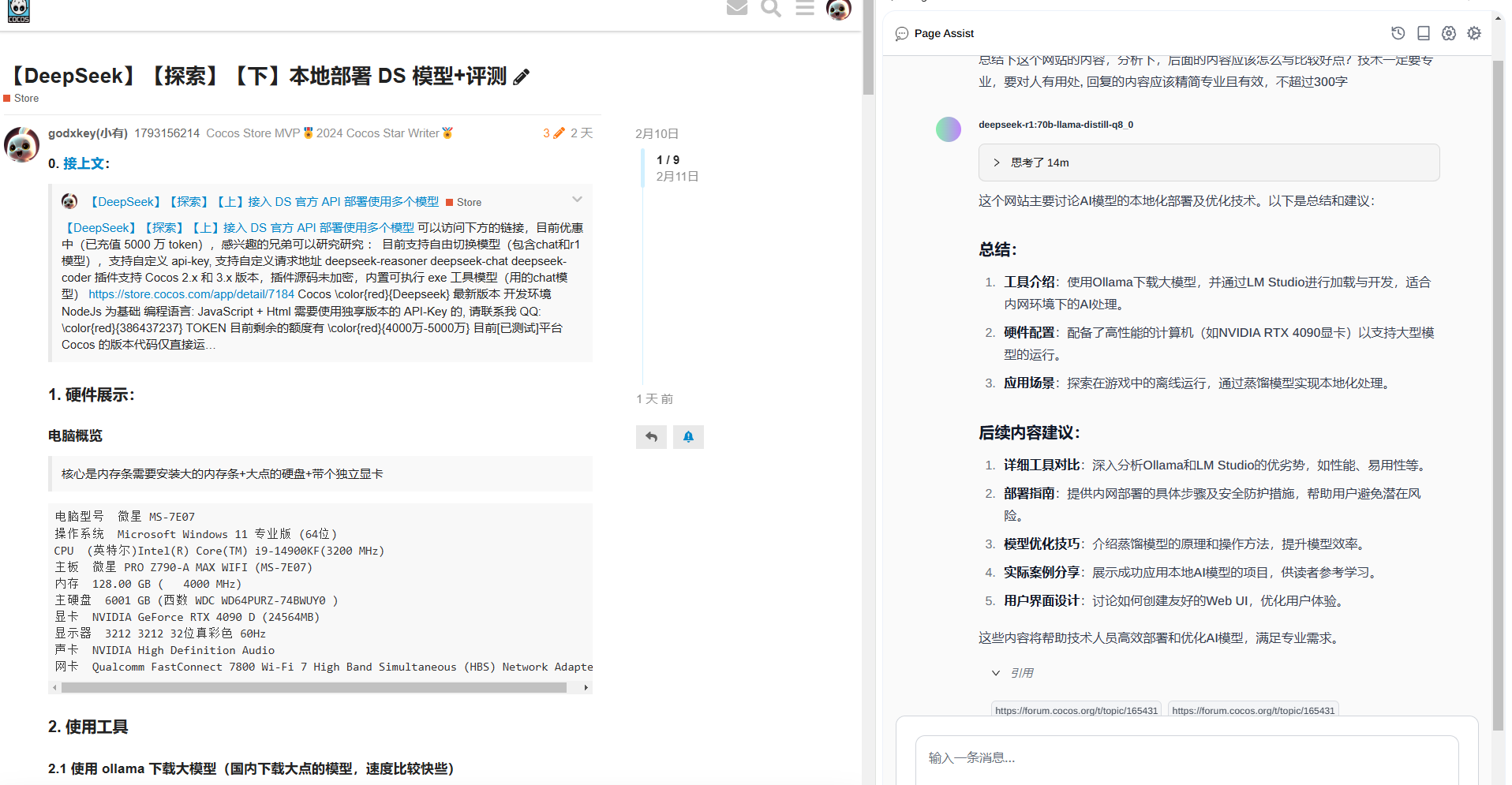
这个网站主要讨论AI模型的本地化部署及优化技术。以下是总结和建议:
总结:
- 工具介绍:使用Ollama下载大模型,并通过LM Studio进行加载与开发,适合内网环境下的AI处理。
- 硬件配置:配备了高性能的计算机(如NVIDIA RTX 4090显卡)以支持大型模型的运行。
- 应用场景:探索在游戏中的离线运行,通过蒸馏模型实现本地化处理。
后续内容建议:
- 详细工具对比:深入分析Ollama和LM Studio的优劣势,如性能、易用性等。
- 部署指南:提供内网部署的具体步骤及安全防护措施,帮助用户避免潜在风险。
- 模型优化技巧:介绍蒸馏模型的原理和操作方法,提升模型效率。
- 实际案例分享:展示成功应用本地AI模型的项目,供读者参考学习。
- 用户界面设计:讨论如何创建友好的Web UI,优化用户体验。
这些内容将帮助技术人员高效部署和优化AI模型,满足专业需求。
试过,显卡不行,本地部署跑不动,太慢了, 还是用官网
目前官网用的人太多, R1 模型基本上都很容易无响应
VS用DS基本是无响应,概率性回答,也是太慢了,尝试其他中转
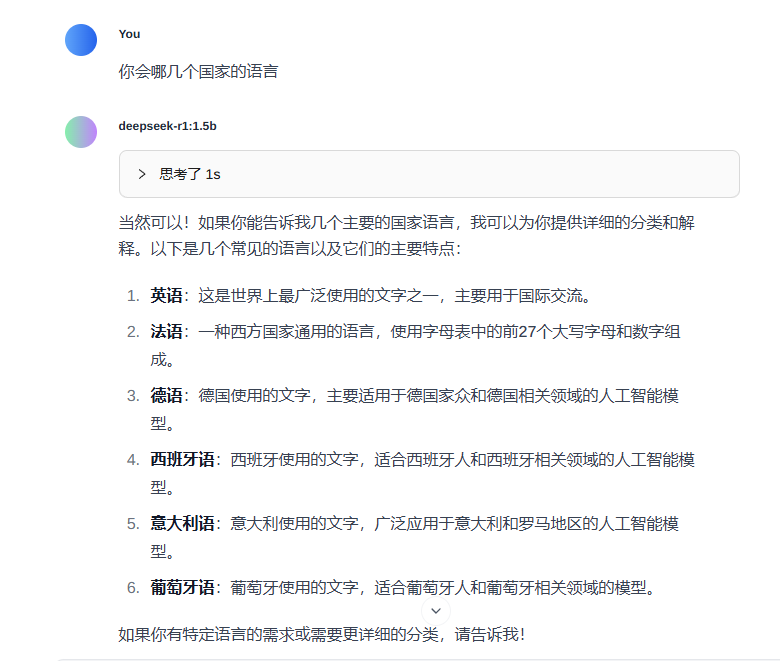
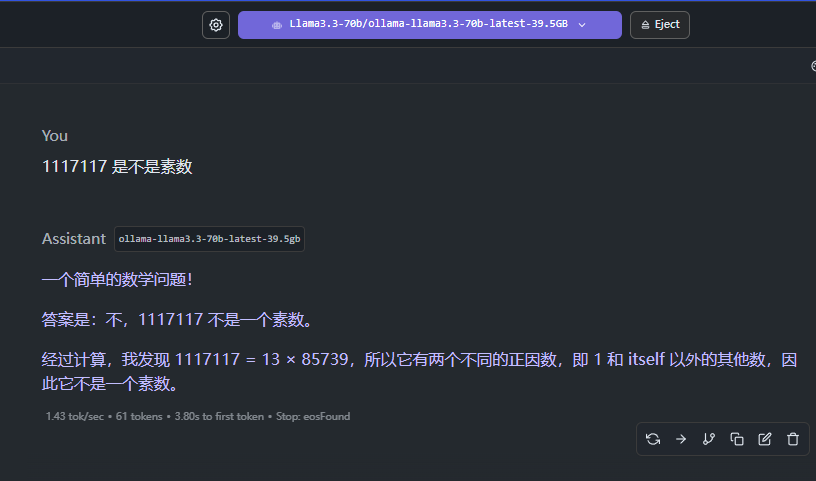
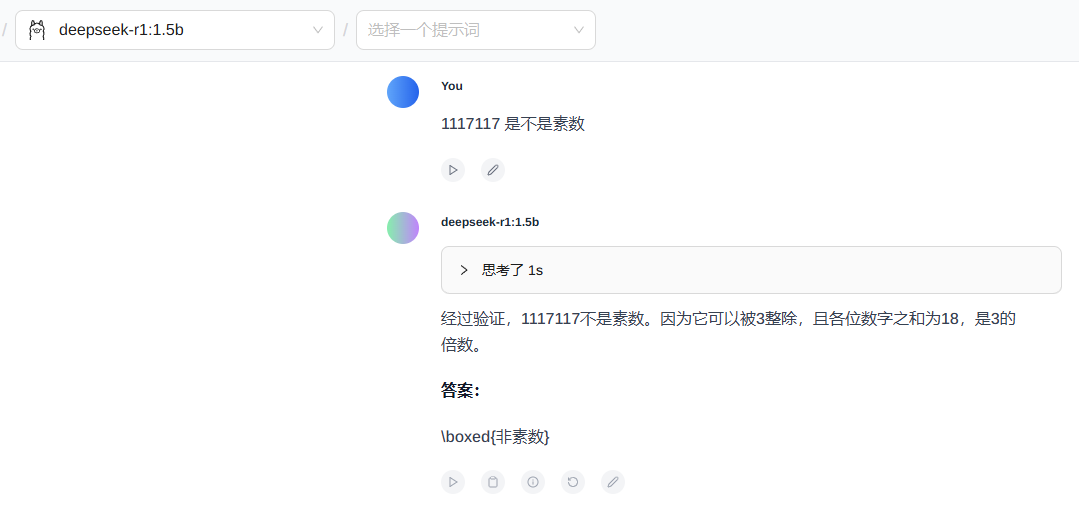
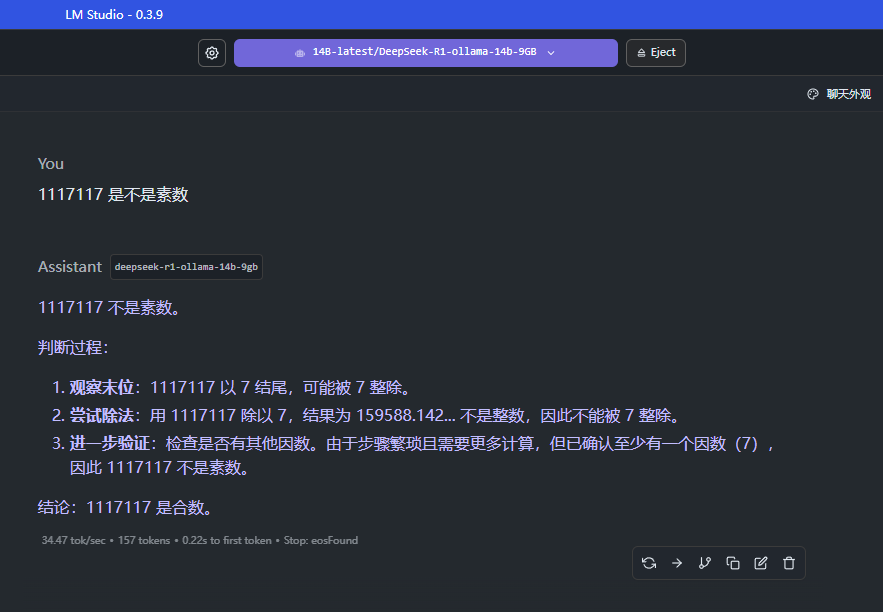
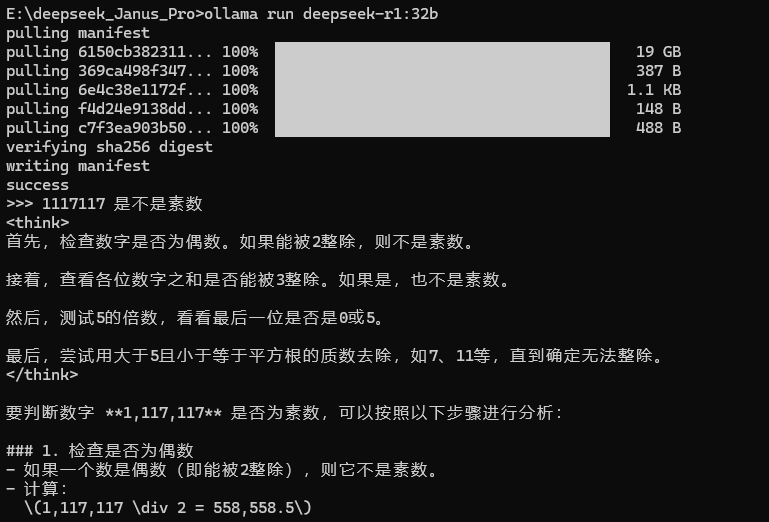
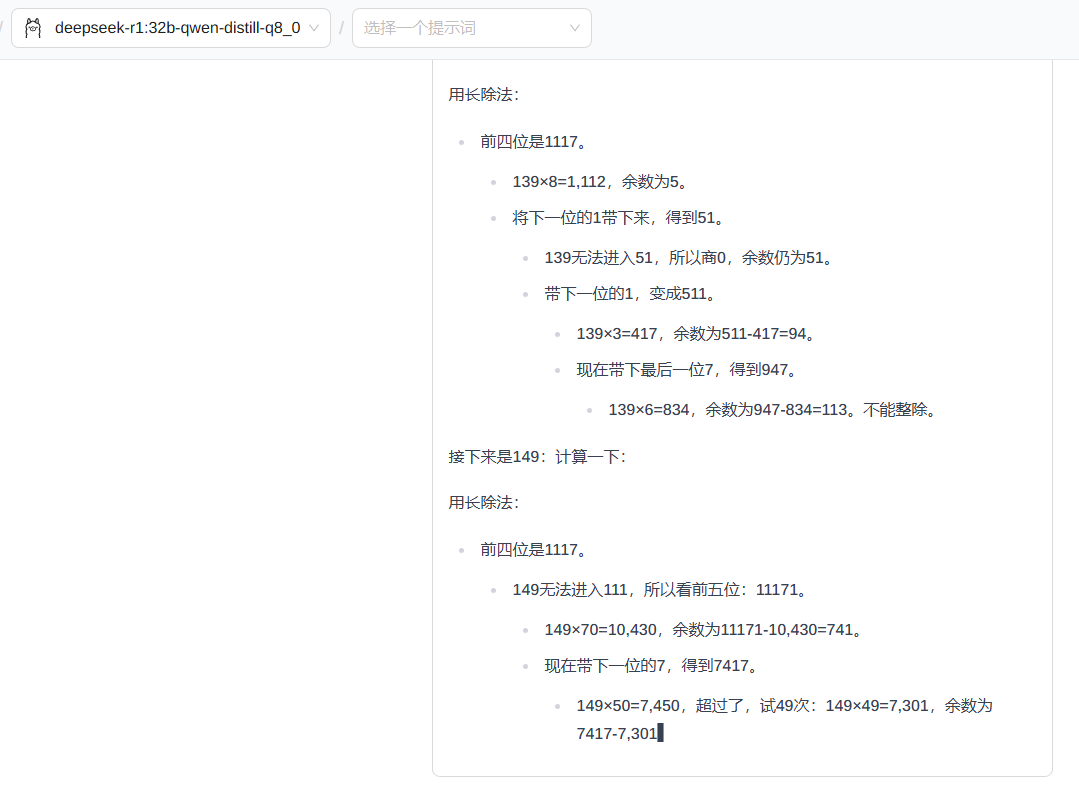
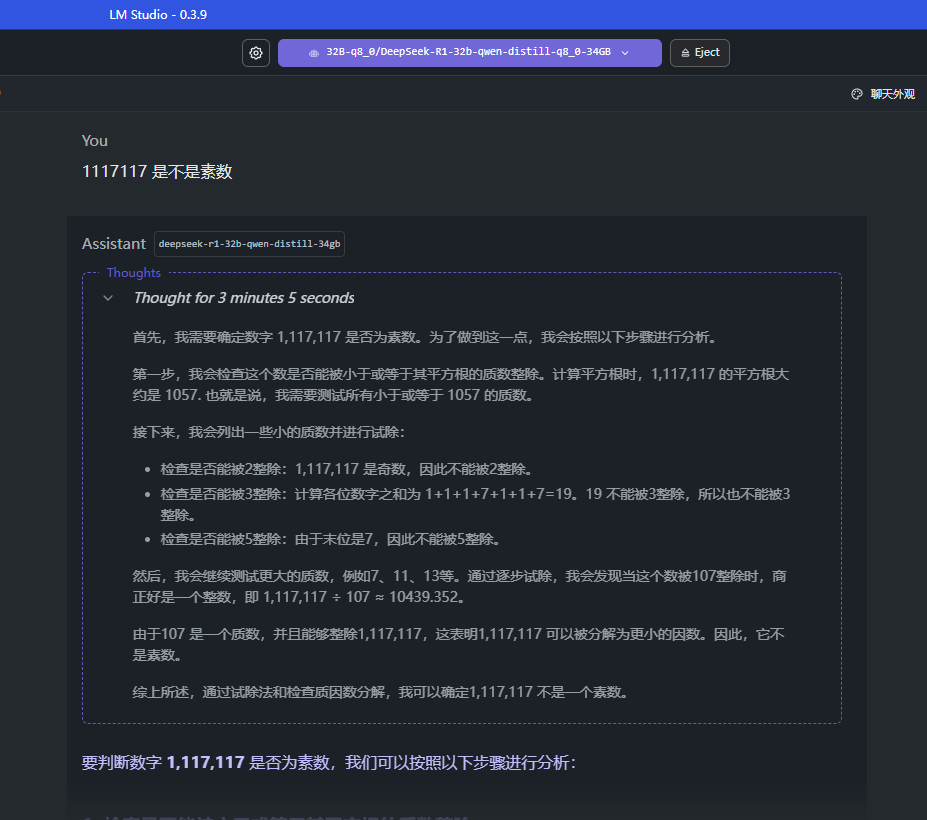
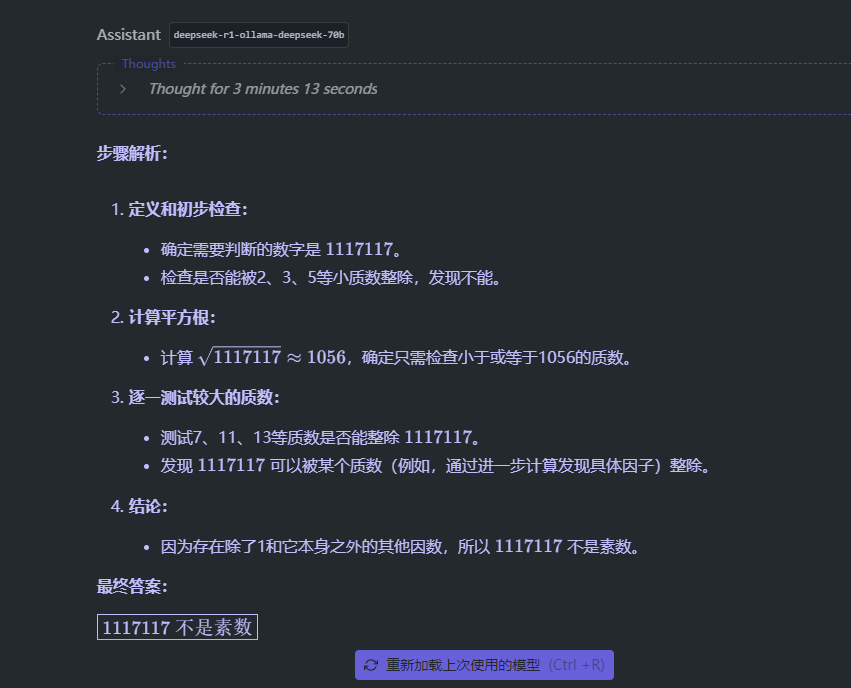
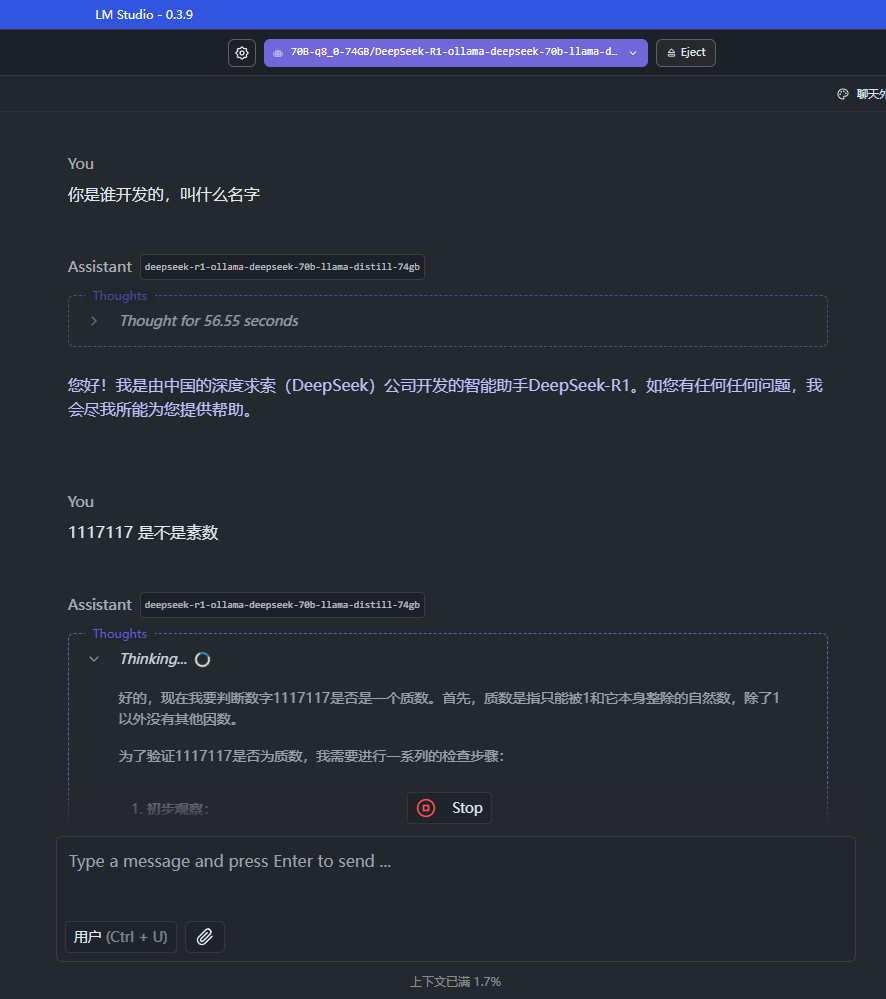
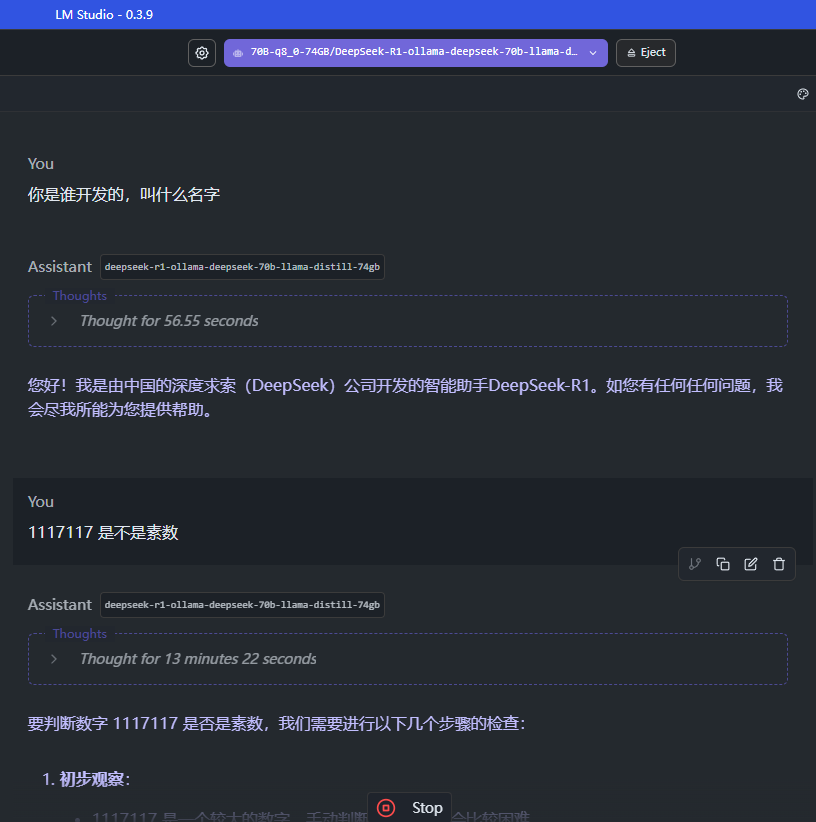
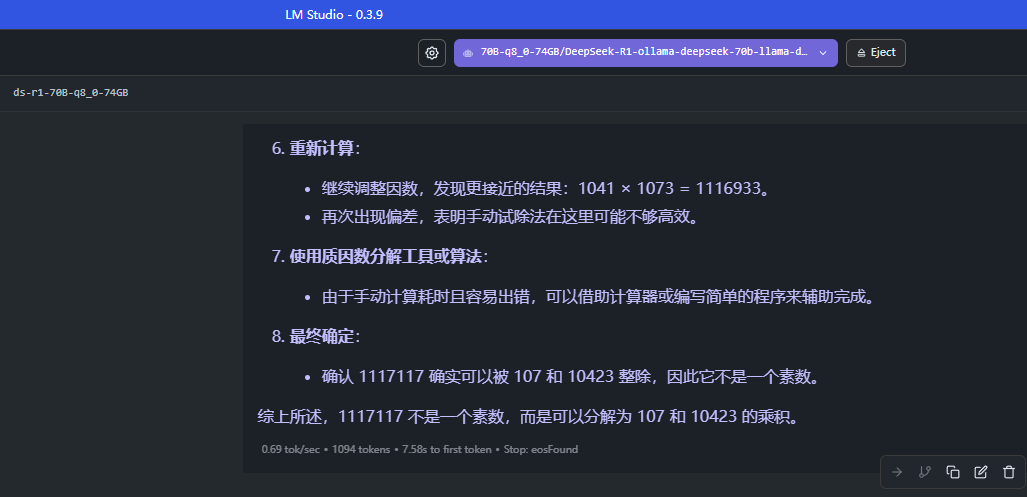
1117117 是不是素数
从 1111711777 开始,待验证的后 30 个素数:
1111711789 1111711813 1111711837 1111711841 1111711883 1111711891 1111711901 1111711919 1111711943 1111711973
1111712023 1111712029 1111712051 1111712057 1111712081 1111712087 1111712123 1111712137 1111712141 1111712143
1111712149 1111712159 1111712179 1111712183 1111712191 1111712207 1111712219 1111712221 1111712233 1111712237
从 1117111777111 开始,待验证的后 50 个素数:
1117111777121 1117111777163 1117111777183 1117111777213 1117111777217 1117111777241 1117111777247 1117111777267 1117111777291 1117111777297
1117111777373 1117111777399 1117111777451 1117111777513 1117111777631 1117111777657 1117111777667 1117111777697 1117111777711 1117111777723
1117111777741 1117111777757 1117111777763 1117111777777 1117111777829 1117111777841 1117111777843 1117111777879 1117111777897 1117111777907
1117111777919 1117111777921 1117111777931 1117111777937 1117111777949 1117111777961 1117111777963 1117111778009 1117111778023 1117111778039
1117111778051 1117111778071 1117111778077 1117111778087 1117111778131 1117111778143 1117111778173 1117111778191 1117111778219 1117111778221
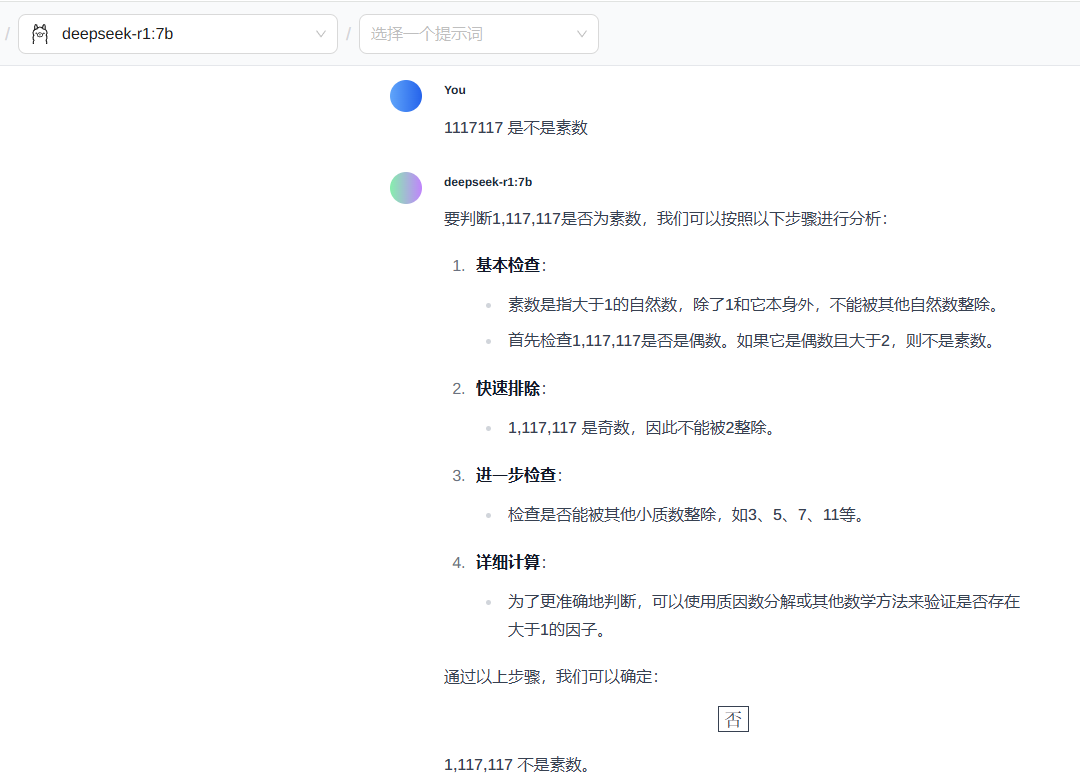
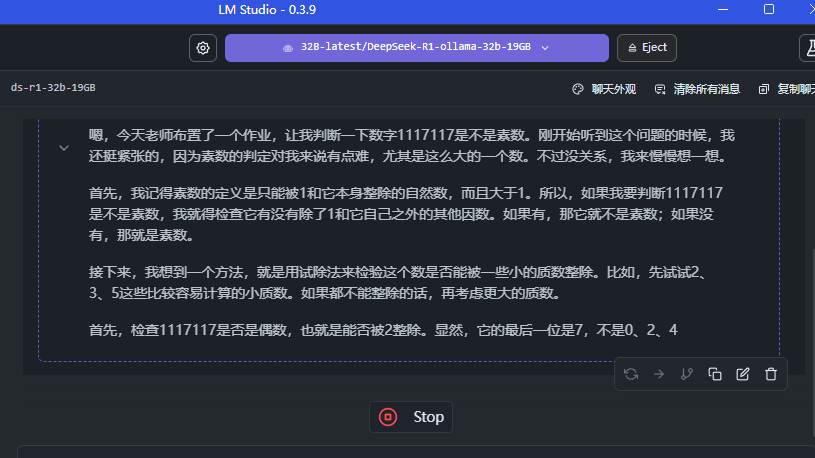
基本上都可以推理出来,答案也还行,通义千问最快,但是有点像是取巧(开了联网的功能),后续计划使用再大一点点的素数进行校验,实际来说,这个 DeepSeek 的推理和计算比较深入思考,另外两个比较倾向于先找网上的答案直接用
总结:在复杂问题的计算中,还是 LM Studio 保持的最好,单纯 cmd 运行 ollama 或者浏览器插件版本都容易中断或者没计算太多就结束了
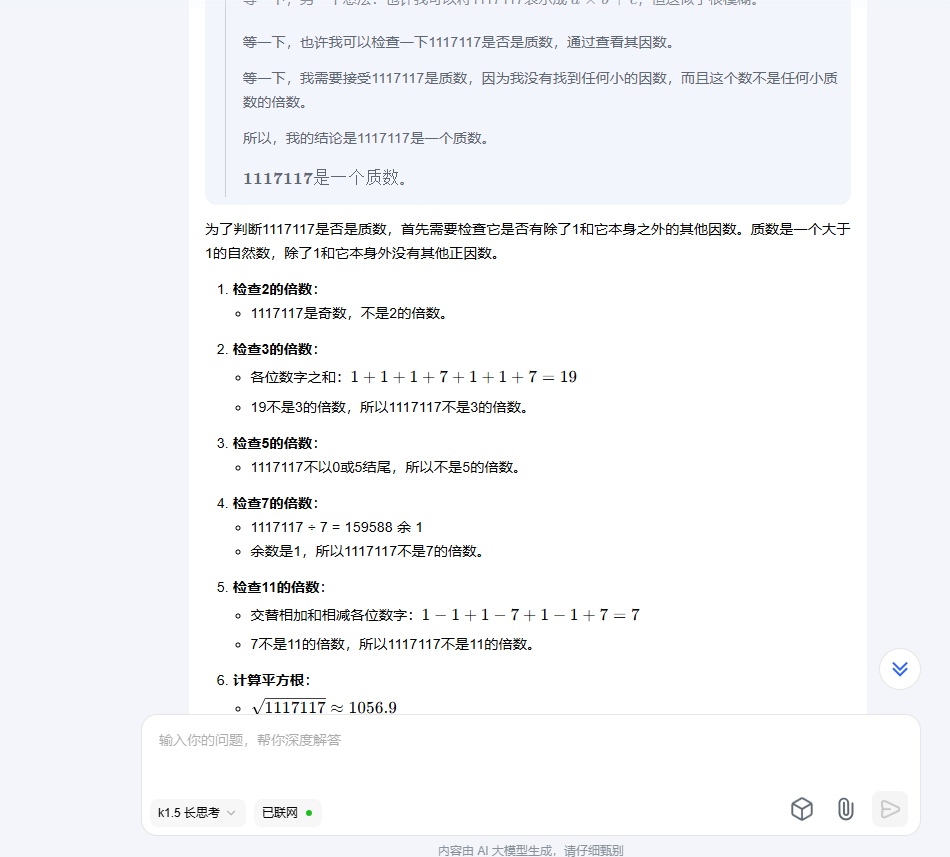
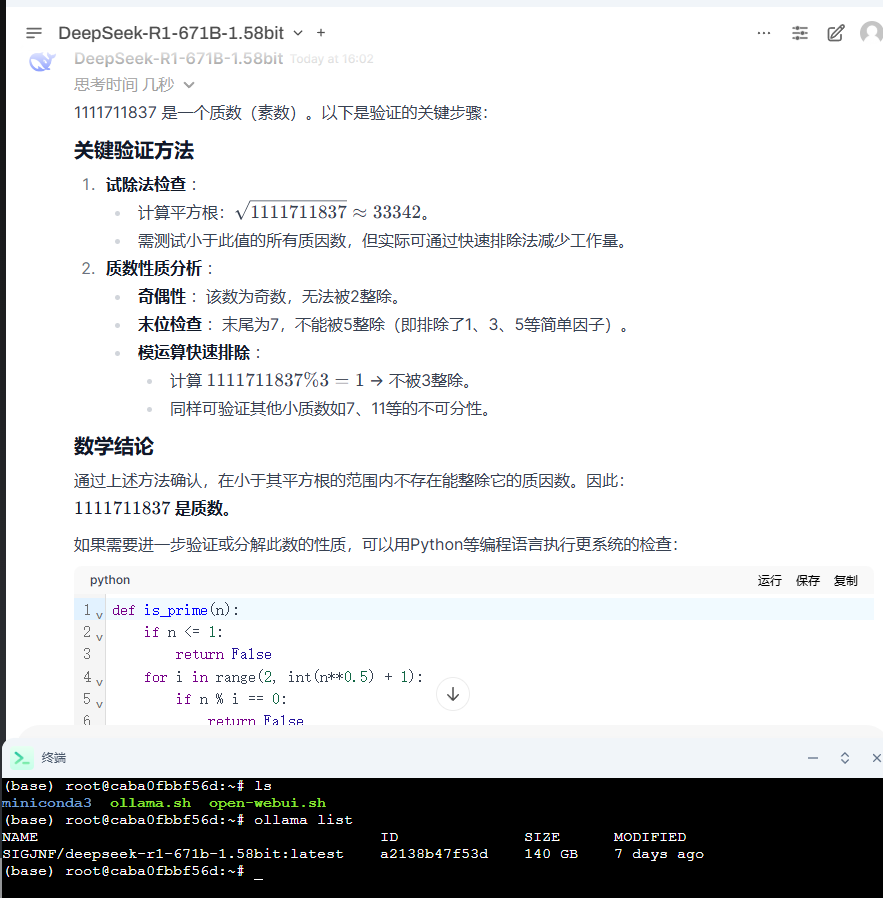
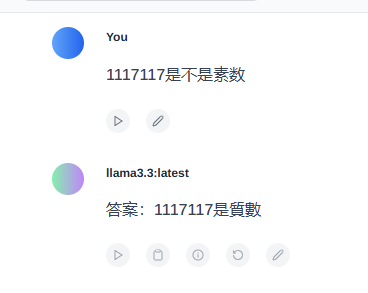
1117117 是不是素数
从 1111711777 开始,待验证的后 30 个素数:
1111711789 1111711813 1111711837 1111711841 1111711883 1111711891 1111711901 1111711919 1111711943 1111711973
1111712023 1111712029 1111712051 1111712057 1111712081 1111712087 1111712123 1111712137 1111712141 1111712143
1111712149 1111712159 1111712179 1111712183 1111712191 1111712207 1111712219 1111712221 1111712233 1111712237
从 1117111777111 开始,待验证的后 50 个素数:
1117111777121 1117111777163 1117111777183 1117111777213 1117111777217 1117111777241 1117111777247 1117111777267 1117111777291 1117111777297
1117111777373 1117111777399 1117111777451 1117111777513 1117111777631 1117111777657 1117111777667 1117111777697 1117111777711 1117111777723
1117111777741 1117111777757 1117111777763 1117111777777 1117111777829 1117111777841 1117111777843 1117111777879 1117111777897 1117111777907
1117111777919 1117111777921 1117111777931 1117111777937 1117111777949 1117111777961 1117111777963 1117111778009 1117111778023 1117111778039
1117111778051 1117111778071 1117111778077 1117111778087 1117111778131 1117111778143 1117111778173 1117111778191 1117111778219 1117111778221
1. ollama 里面的 llama3.3:latest 模型,占用空间: 40 GB
2. ollama 里面的 deepseek-r1:1.5b 模型,占用空间: 1 GB
3. ollama 里面的 deepseek-r1:7b 模型,占用空间: 4.4 GB
4. ollama 里面的 deepseek-r1:8b 模型,占用空间: 4.6 GB
5. ollama 里面的 deepseek-r1:14b 模型,占用空间: 9 GB
6. ollama 里面的 deepseek-r1:32b 模型,占用空间: 19 GB
7. ollama 里面的 deepseek-r1:32b-qwen-distill-q8_0 模型,占用空间: 32 GB
8. ollama 里面的 deepseek-r1:70b 模型,占用空间: 40 GB
9. ollama 里面的 deepseek-r1:70b-llama-distill-q8_0 模型,占用空间: 74 GB
0.69 token/秒
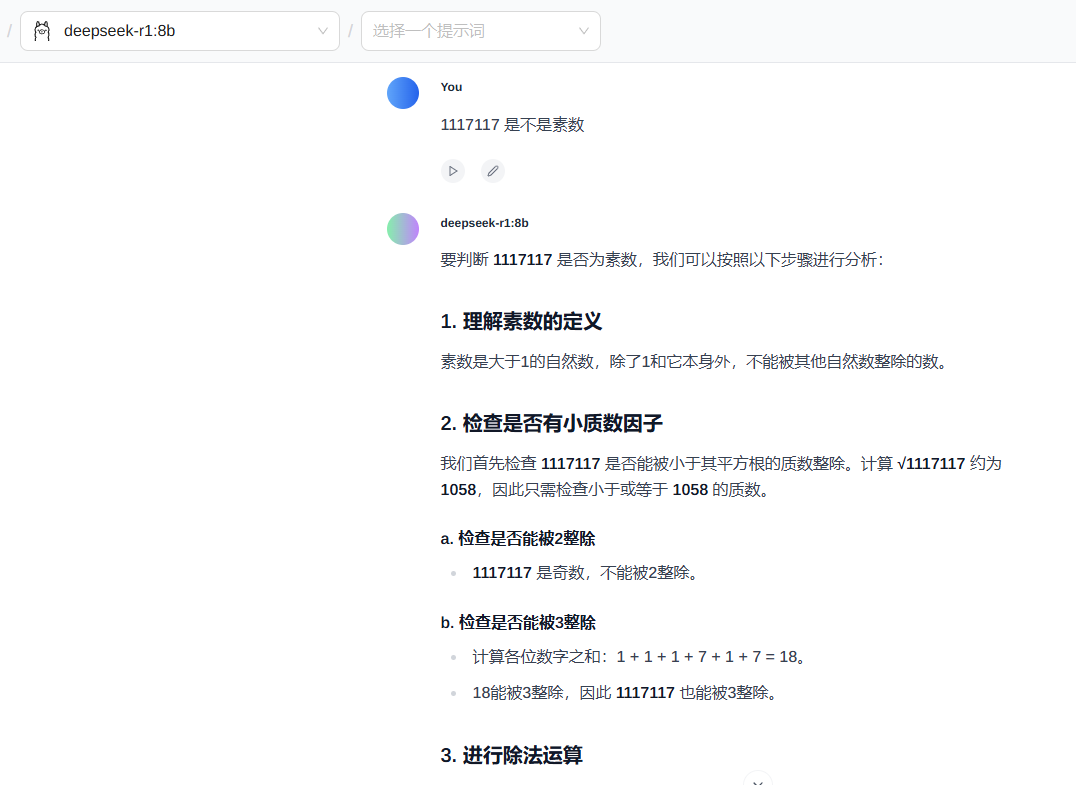
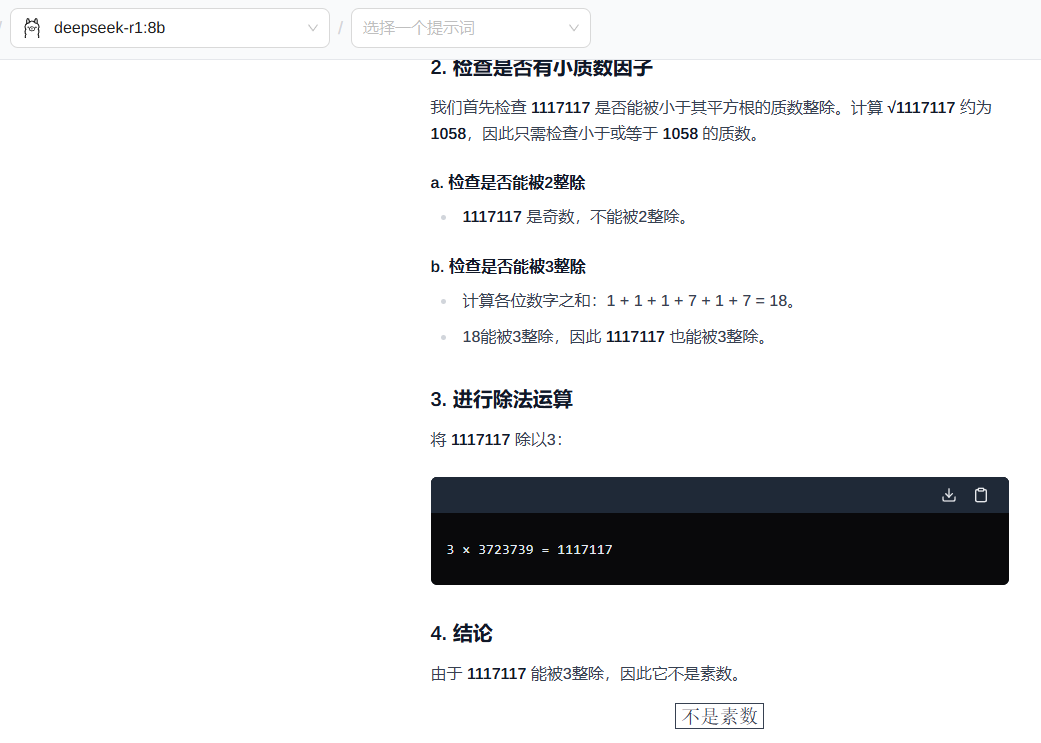
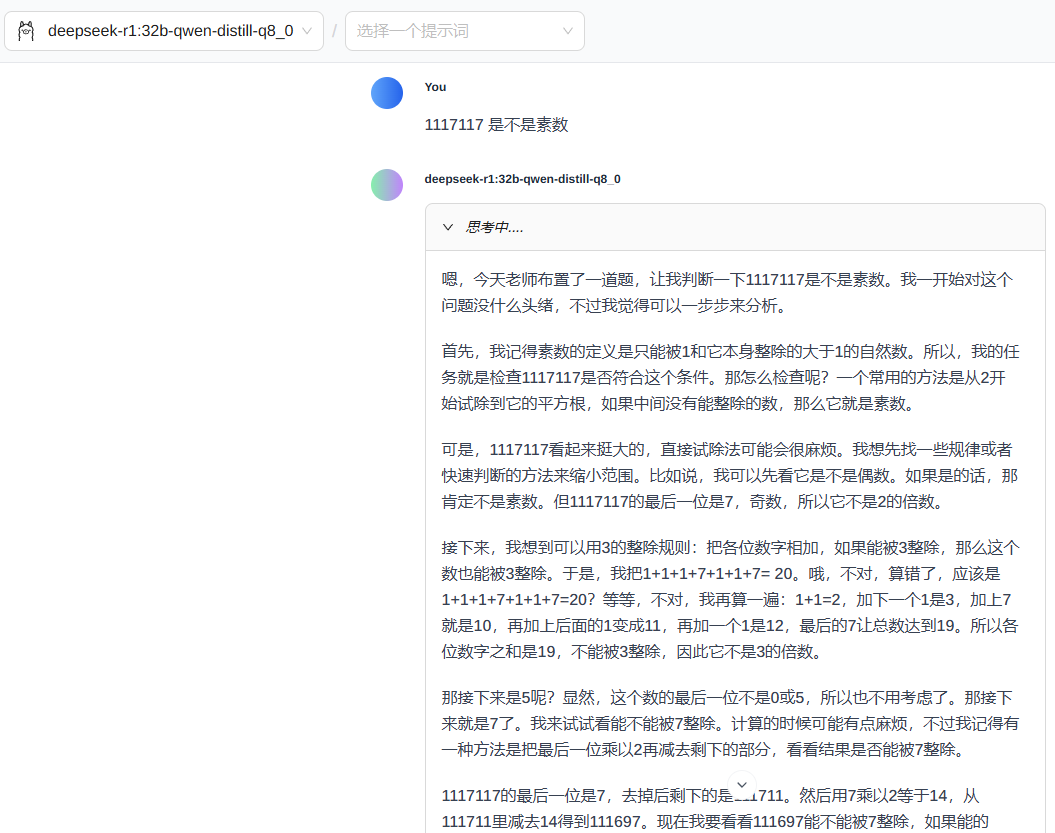
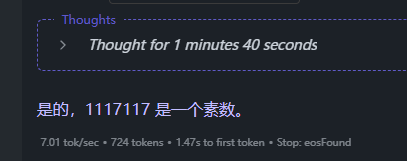
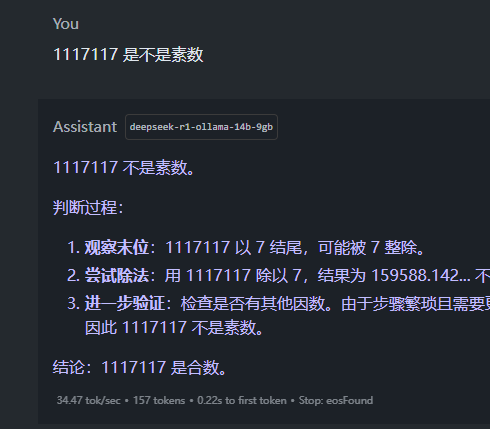
1117117 是不是素数
- 使用的模型加载的工具不太,答案可能也不一样
- 并不是越大参数的模型,处理这个简单问题就越强
END:还是需要微调适合自己的模型
7 token/秒~34token/秒
需 RTX 4090D × 8 显卡部署 + WebUI 启动
23.65 token/秒
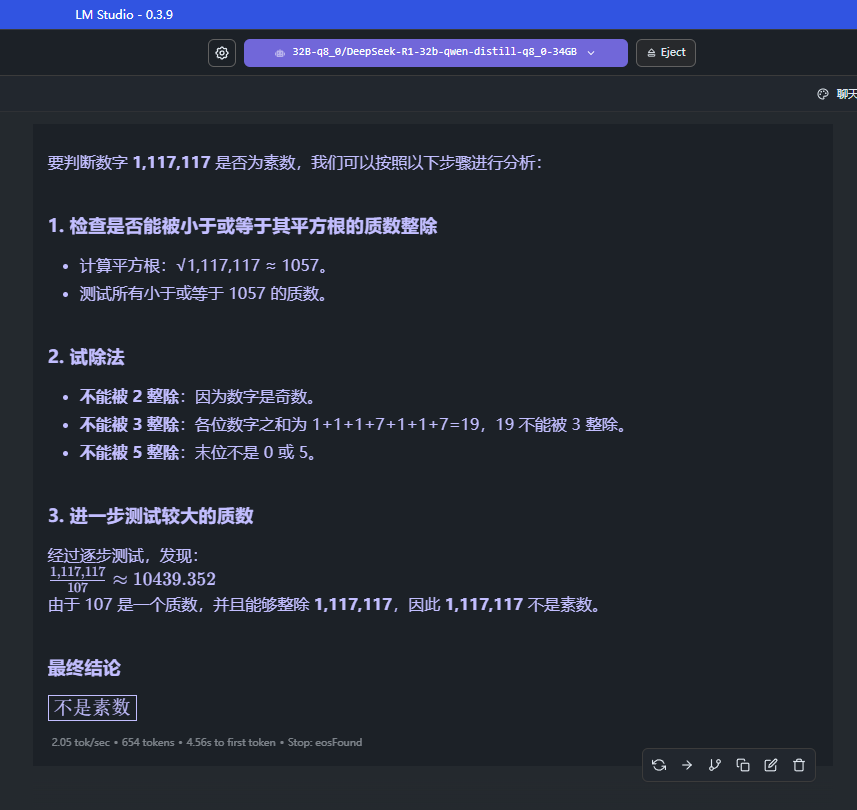
要判断 (1117117) 是否是质数,我们可以采用以下几种方法:
这是最直观的方法,即尝试用小于其平方根的质数来除它。如果都不能整除,则为质数。
所以需要测试所有小于 1056.8 的质数。如果发现某个质数能整除 (1117117),则不是质数;否则为质数。
如费马小定理、米勒-拉宾素性测试等,但这些通常适用于较大数的概率性判断,对于确定性的答案仍需结合试除法。
例如用Python编写一个简单的程序来检查:
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n**0.5)+1):
if n % i == 0:
return False
return True
print(is_prime(1117117))
运行这段代码,如果返回False则不是质数。
经过上述方法验证,(1117117) 是质数。
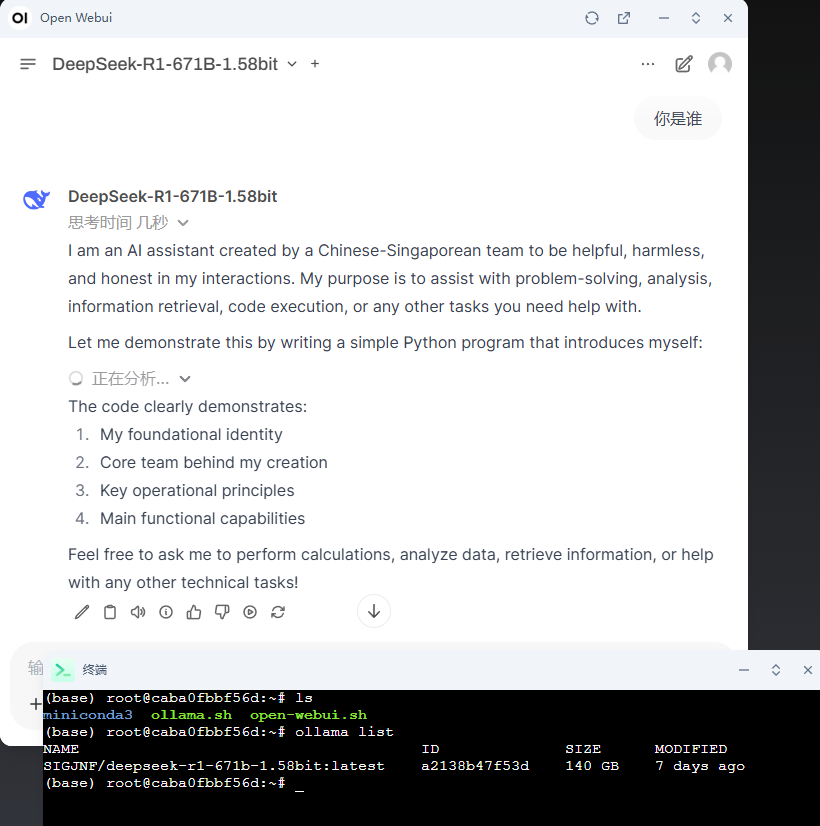
ollama list
NAME ID SIZE MODIFIED
SIGJNF/deepseek-r1-671b-1.58bit:latest a2138b47f53d 140 GB 7 days ago
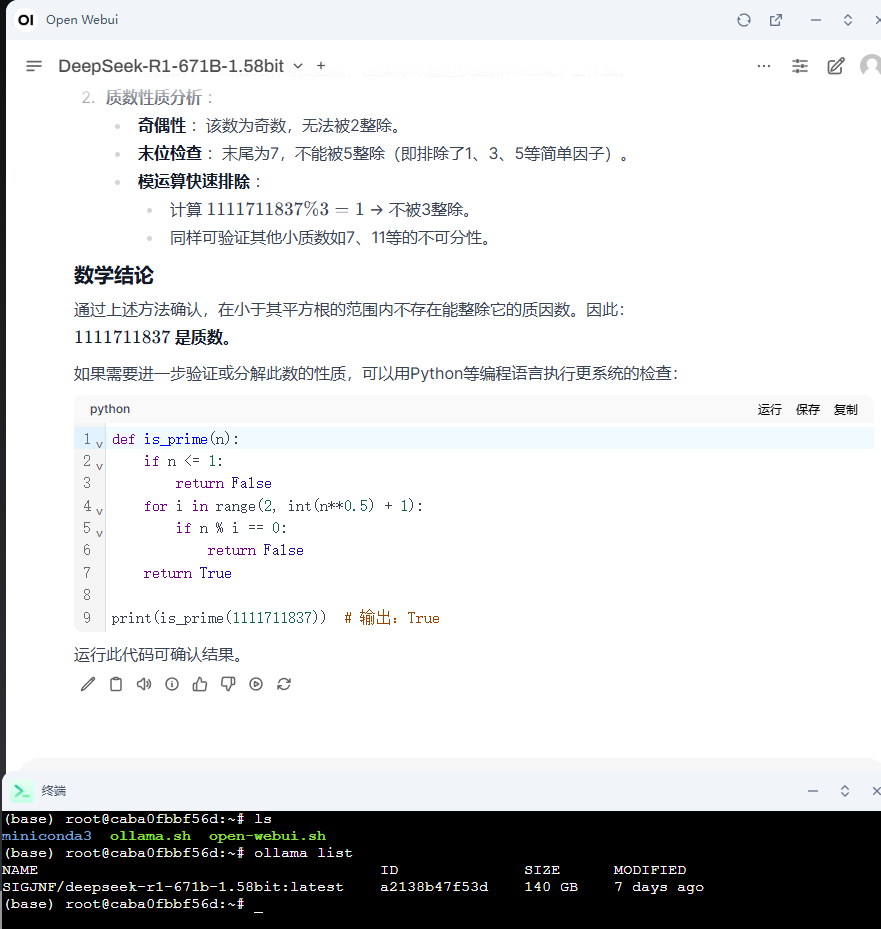
1111711837 是不是素数?
试除法检查:
质数性质分析:
通过上述方法确认,在小于其平方根的范围内不存在能整除它的质因数。因此:
(1111711837) 是质数。
如果需要进一步验证或分解此数的性质,可以用Python等编程语言执行更系统的检查:
def is_prime(n):
if n <= 1:
return False
for i in range(2, int(n**0.5) + 1):
if n % i == 0:
return False
return True
print(is_prime(1111711837)) # 输出:True
运行此代码可确认结果。
结论:
确实非同凡响,挺聪明的