最近在研究cc物理方面底层代码,一直想弄明白为什么Ray这么消耗性能,都在说减少检测次数,分帧检测,降低检测三角面数等等优化方案,从中我们能猜测应该是Ray检测for三角面次数过多导致,但是是哪一个fun导致的或者说哪个fun中的哪块代码块导致的呢,你知道吗?我想大多数人都是不知道,我也不是太清除,所以我想开这个帖子把我的见解和疑问都说出来,还望大佬不吝赐教
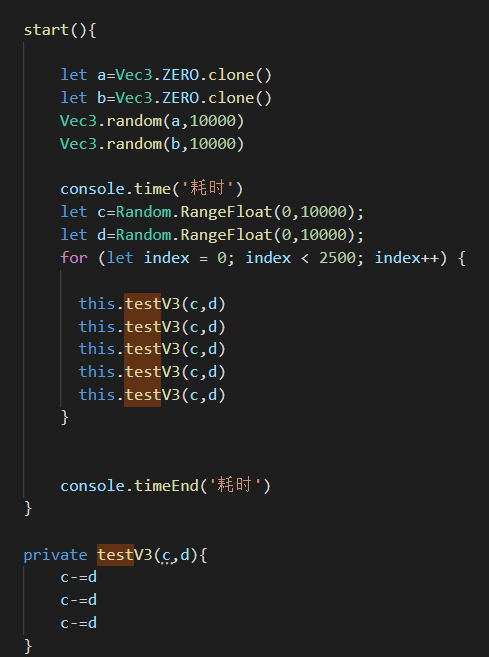
首先我使用了Performance测试出了Ray中消耗性能的关键处,这是Call Tree
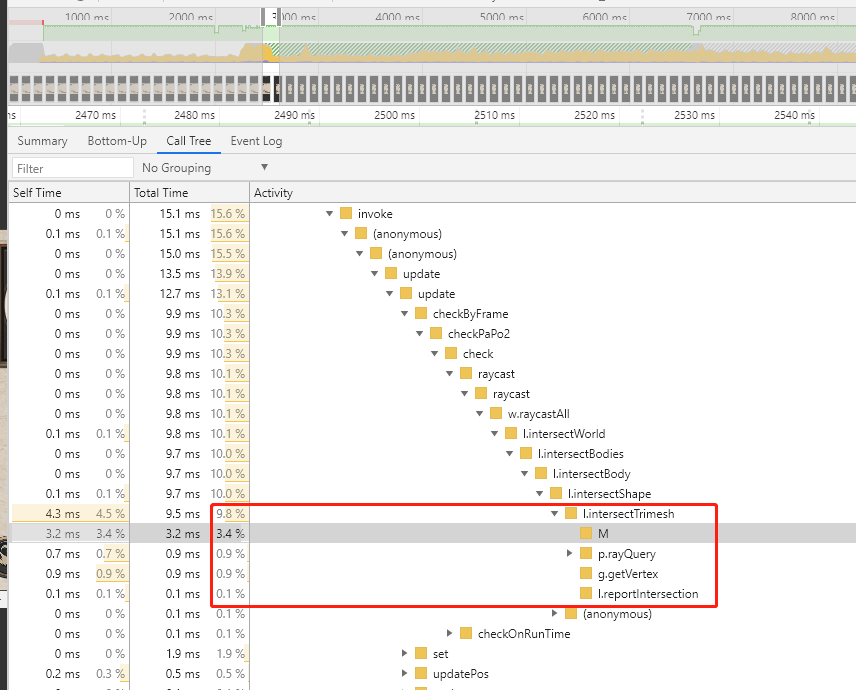
可以看到M函数占3.4,intersetTrimesh函数占10-5.3=4.7
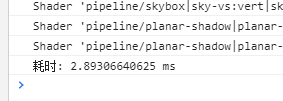
找到M函数,这里有3次sub和5次dot ,看来3.4的性能消耗是sub和dot,我把sub和dot单独拎出来用console.time测试了一下消耗,结果发现了一个惊人的问题,先来看下测试:

我就假设与射线相交的subMesh三角面有2500个,代码如下:
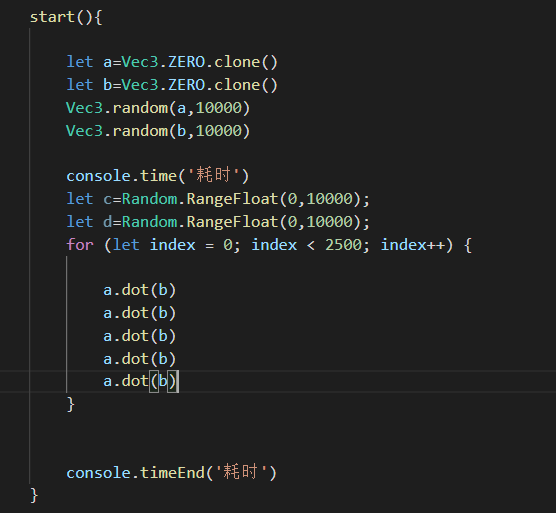
5次dot2500,一共运行这么多次,时间消耗为
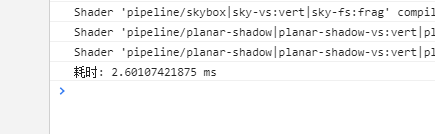
我们知道dot是三个分量相乘再相加,就是一共三次两次+,我把这个换成相对应的*+运算
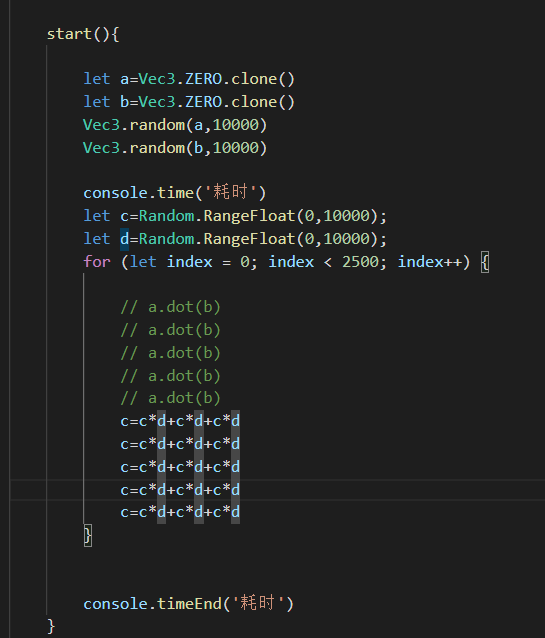

居然相差3倍!我同事说是这两个运算虽然是一样的但是一个是vec3引用类型一个是值类型运算,但是相差的这么多还是觉得有问题啊!然后我又测试了一下sub和add函数
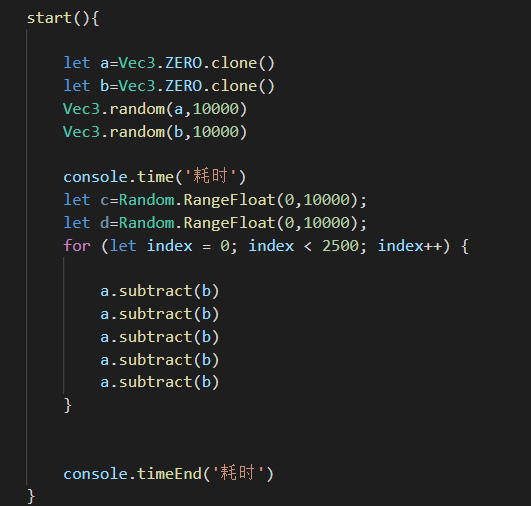

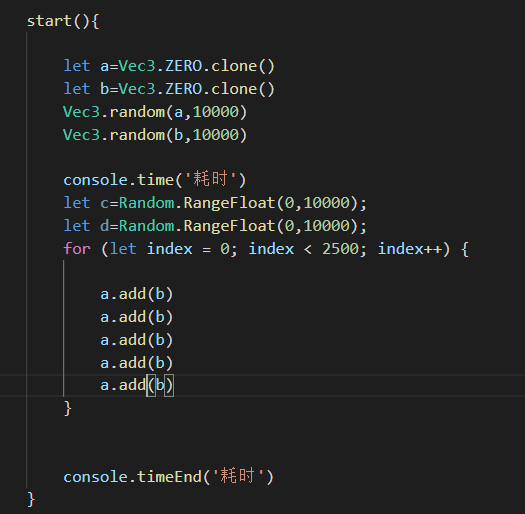
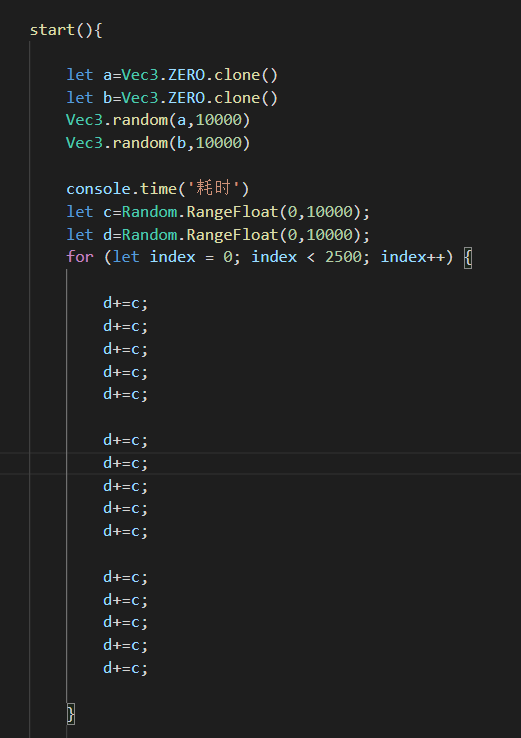
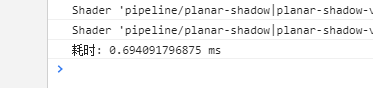
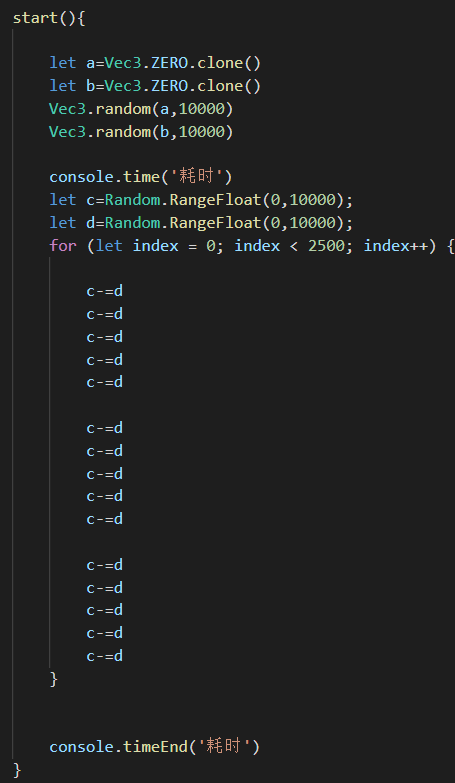
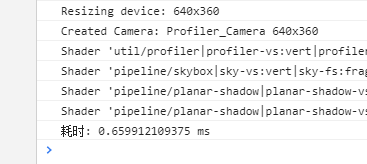
Vec3的加减乘除代码我就不贴了,就是基本值类型运算的组合,这倍数相差这么大,还望大佬能告知一下原因。是我的凭空捏造还是确实这样呢!?
然后intersetTrimesh代码在这里,代码比较多,我暂时还没能定位到具体的哪个fun,有大佬知道的还望告知,不胜感激!
这是处理过的代码

这是源代码:
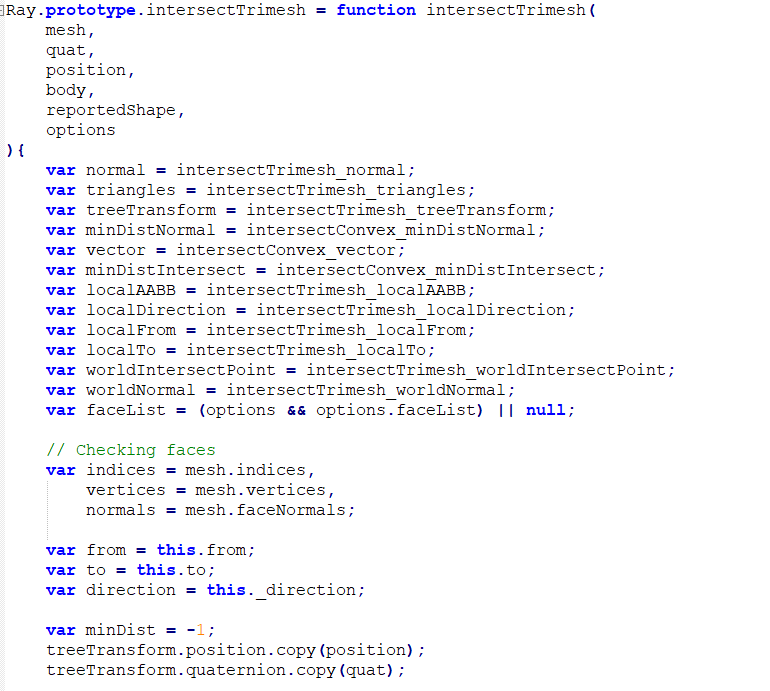
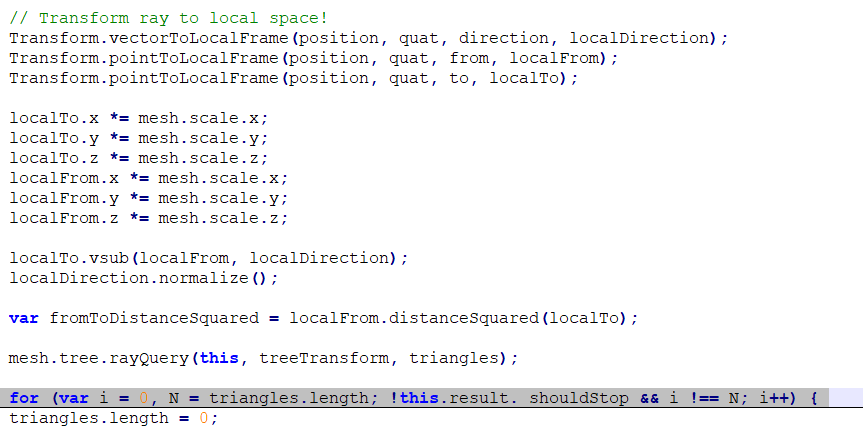
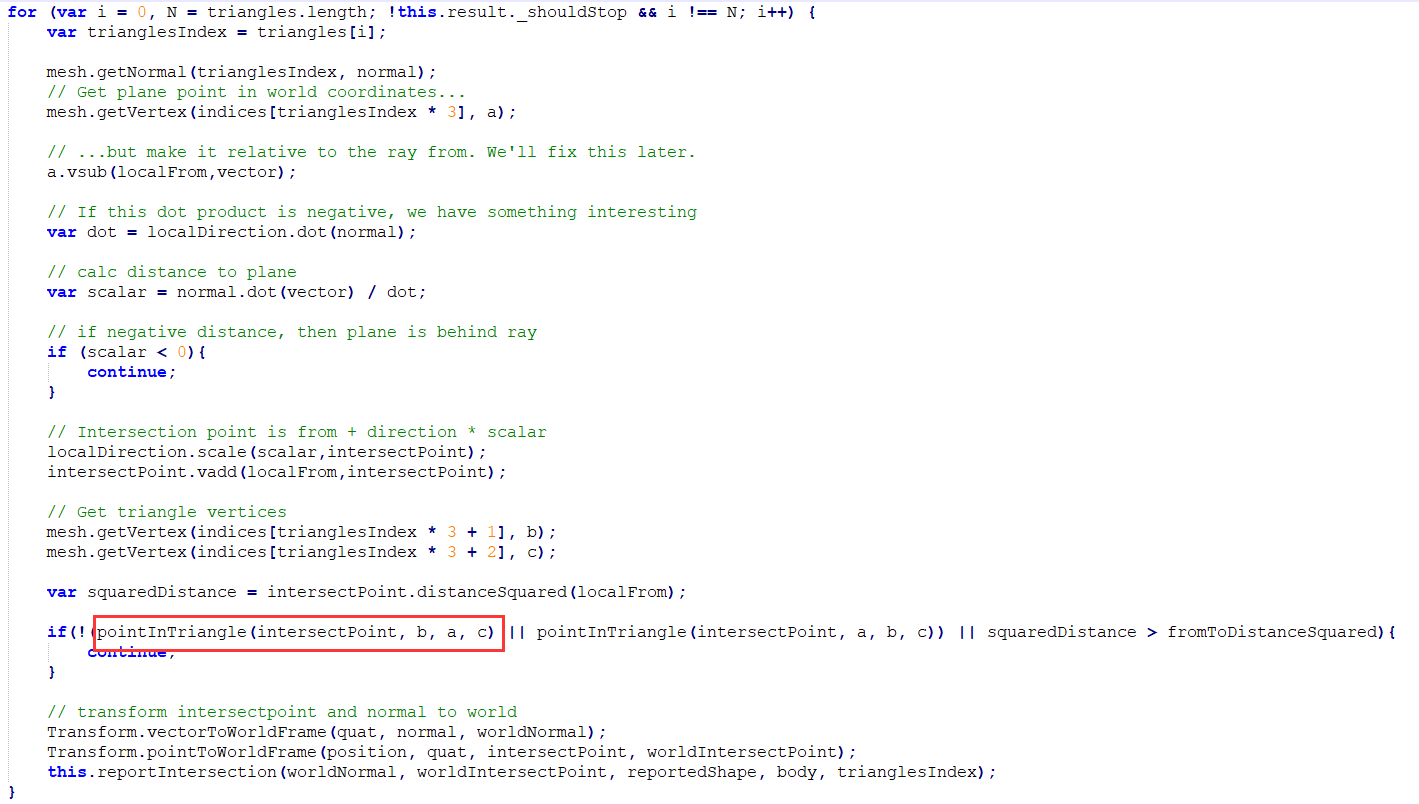
红色圈出来的就是M函数