
UI渲染合批实践-根据社区文章-上篇(下篇会支持原生)
前言
- 社区对UI渲染合批已经有一些方案,笔者最近参考某些方案进行了实践。
- 本实践的优点是无需定制引擎,支持嵌套mask,并且同时支持H5和原生。
方案一
1. 原理
- 渲染开始前,按层次重新组织子节点。渲染完成后,还原子节点的结构。如图,该列表包含两个item,渲染开始前,临时将列表节点构造成右边临时结构,渲染完成后,再将列表节点还原成左边的原始结构。
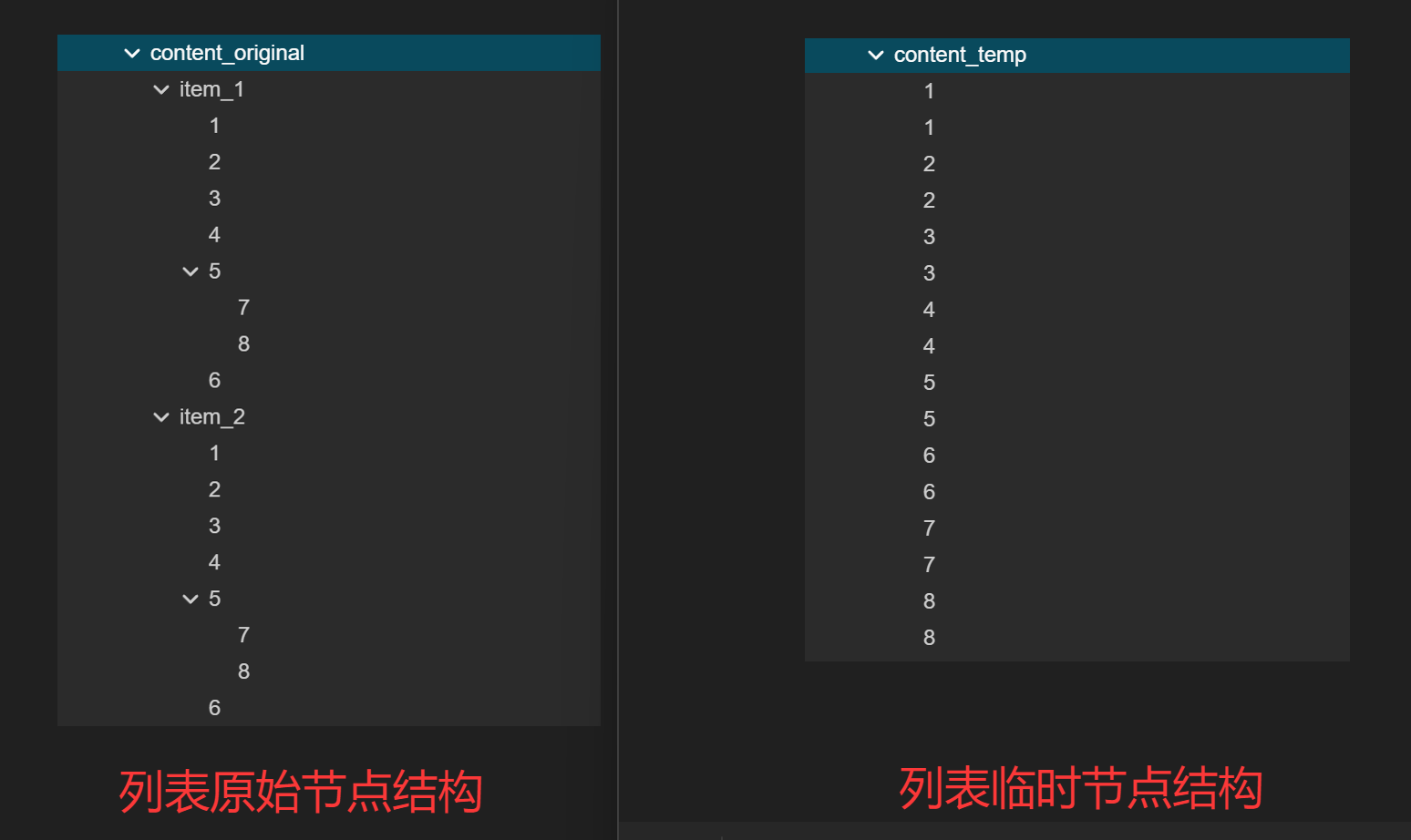
图1.1 列表节点结构对比
- 渲染遍历的函数在3.8上面是Batch2d的walk函数,节点的遍历是按照深度优先的规则进行的。渲染遍历的时候,通过将children重新组织成新的结构,可以优化渲染顺序。如图,在渲染的时候,如能通过重新组织children节点结构,使得左边的渲染顺序。变成右边的渲染顺序,那drawcall将会大大减少。
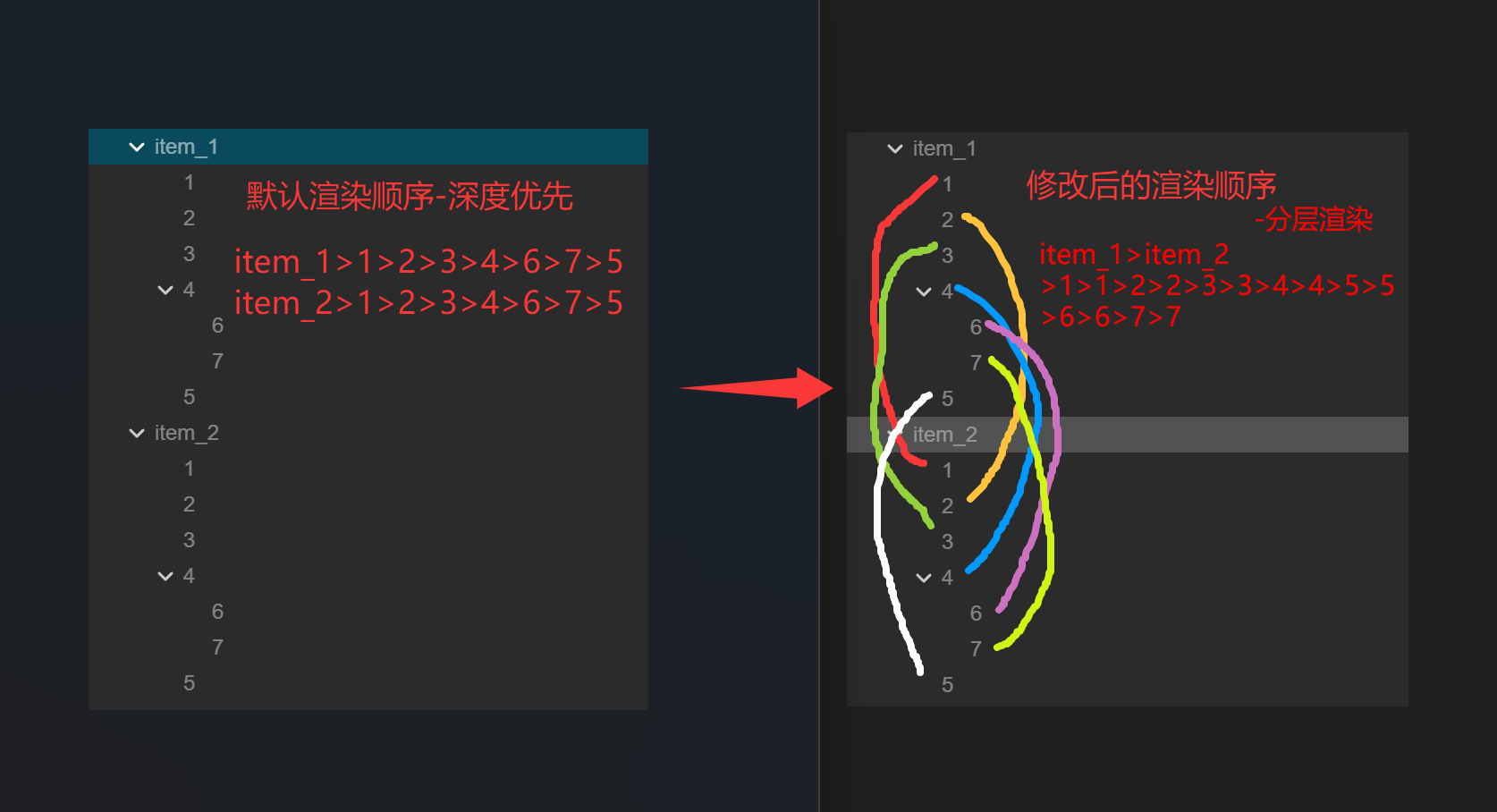
图1.2 item-渲染顺序对比
- 由上图可以看出,渲染顺序并非只是简单的从深度遍历改为广度遍历。但如果item每一层的渲染组件都来自同一个图集,那确实可以简单的改为广度遍历。或者人为增加一些空节点,按是否同一图集来分层组织,这样也可以使得广度遍历可行。
2. 参考方案
-
2.1 《性能优化1-列表渲染优化|社区征文》,作者Bool Chen,使用版本是2.x。这个方案需要增加一个新的组件,缓存新的子节点结构,另外还需要修改引擎的源码。
-
2.2 如何一行代码减少合批,作者小不溜,使用版本是3.x。同样需要修改引擎源码或对引擎函数进行覆盖重写。
-
2.3 之前似乎看到过98k写过一篇文章,分享过原理,但现在好像找不到那篇文章了。记得原理是,分别捕捉渲染开始和渲染结束事件,渲染开始前,将节点children的结构重排,渲染完成后,再将children的结构还原。这种捕捉渲染事件的方式,使得这个方法不需要修改引擎源码,这是这个方法的优点。
3. 问题与讨论
-
上述的2.3文章暂时找不到,暂讨不论。
-
上述2.1和2.2不知道是否支持内嵌mask,或内嵌scrollview,笔者没有验证,只是看了一下思路。
-
根据笔者的实践,上述2.1和2.2,应该是不支持原生Android和Ios。根据商店售卖的商品,2.3应该是支持原生的。
4. 实践
- 4.1 每个item添加一个组件MergeItem,在onEnable的时候,缓存一份分层的节点数组。如图:

图2 MergeItem分层节点数组
-
4.2 列表父节点添加一个组件MergeRoot,捕捉渲染开始和结束事件。
director.on(DirectorEvent.BEFORE_DRAW, this.onBeforeDraw, this); director.on(DirectorEvent.AFTER_DRAW, this.onAfterDraw, this); -
4.3 渲染开始的时候,重新组织children的结构,渲染结束之后,再还原children的结构。这样做的好处是无需修改引擎代码。
-
4.4 根据笔者方案,重新组织children结构的时候,如果没有把node的children设置为空数组,会导致有些控件会重复绘制。原因是并未修改任何引擎源码,Batch2d的walk函数仍按深度遍历进行。如图,Button下的Label会绘制两次。

图3 需要把node的children先重置为空数组
-
4.5 笔者的实践支持item内嵌scrollview或mask。
-
4.6 创建1000个item,发现Batch2d的walk函数,花费的时间还不少,有5-6ms。如果在渲染之前,也先剔除一些列表外的item,是不是能减少walk函数的运行时间?实践证明,确实可以。在没剔除之前,滚动的过程中,卡顿明显,而在做了剔除之后,滚动依然可以满帧运行。
5. todo
- 不支持原生Android或Ios,下篇文章已经支持了
6. 商城链接
-
具体性能比较图表可参考商城链接。
其他方案
- 有待实践。
下篇地址
ps,笔者正在寻找base广州的机会,如果合适的话,可以私信我,谢谢。
 又一个轮子
又一个轮子
