
作者介绍:“忙着赚钱”,游戏行业10年后端开发经验,目前在研究使用前端引擎开发游戏。期间已用 Cocos 引擎实现了一款三消类小游戏,并上架微信、抖音平台。
二十年前,Mat Buckland 先生创作了《游戏人工智能编程案例精粹》这本经典。二十多年来,它依然是全球开发者学习游戏 AI 的必读之作。
它不是空洞的理论,而是能让你亲手打造一个会“自己思考”的智能体的实战指南。
原书呈现了大量 AI 技术方案,包括状态机、操控行为、空间划分、图的各种算法、触发器、路径规划、目标驱动、模糊逻辑等等。

笔者就是在学习本书的过程中,通过 Cocos Creator 实现了书中的案例,可以查看视频。
下面会通过几个例子,来为大家呈现原书的魅力。
操控行为
原书第3章,作者通过对操控行为的运用,来实现可以自治的智能体。
所谓操控行为,就是操控智能体,让它来完成指定的行为,这些行为有很多种。

例如:靠近指定的目标、远离逃避目标、追逐目标、漫无目的的徘徊、避开墙壁和障碍物、利用障碍物来躲避目标、跟随指定的路径运动等。
当然还有看起来就让人兴奋的集群行为。

多种行为之间可以进行组合,从而实现多种自治的效果。
按照笔者的理解,操控行为本质上是利用了初中物理的几个基础公式:
- 加速度计算公式:a = F / M
- 速度与加速度之间的公式:v = v0 + a * t
每种类型的操控行为,都会为智能体身上施加一个作用力 F。
靠近目标的话,就需要一个指向目标的作用力,来拉着智能体朝目标的方向移动,远离目标的话,则正好相反。
而所谓的作用力 F,在二维、三维坐标系里,就是带方向和大小的向量,Cocos Creator 里面的 Vec2、Vec3 正是为此而设计的。
施加在智能体身上多个操控行为,就会产生多个作用力。通过向量加法,我们就可以计算出最终的合力 F。

带入上面提到的两个公式后,我们可以计算出a。
通过 a,结合当前经过的时间 deltaTime,我们可以计算出当前帧最新的速度 v。
有了当前速度,之后就好办了,利用公式“X = X0 + v * t”就可以计算出智能体最新的位置。瞧,操控行为就是这样。
当然操控行为真正实现起来,远比上面说的要复杂,书中的核心就是如何计算这些“力”。

原作者用 C++ 实现,而本项目则用 TS 语言,结合 Cocos 引擎,移植了这些操控行为的核心逻辑。
这里定义了操控行为的枚举类型,定义一个操控行为类,包含开启、关闭各行为的接口:
// 控制行为种类
enum RavenBehaviorType {
none = 0,
seek = 1 << 1, //靠近
flee = 1 << 2, //离开
arrive = 1 << 3, //抵达
wander = 1 << 4, //徘徊
cohesion = 1 << 5, //聚集
separation = 1 << 6, //分离
...
};
@ccclass('RavenSteering')
export class RavenSteering {
// 是否开启指定类型的控制行为
private on(bType: RavenBehaviorType): boolean {
return (this._flags & bType) == bType;
}
// 开启指定类型的控制行为
private onType(bType: RavenBehaviorType) {
this._flags |= bType;
}
// 关闭指定类型的控制行为
private offType(bType: RavenBehaviorType) {
if (this.on(bType)) {
this._flags ^= bType;
}
}
// 开启靠近行为
seekOn() {
this.onType(RavenBehaviorType.seek);
}
// 开启徘徊行为
wanderOn() {
this.onType(RavenBehaviorType.wander);
}
...
// 关闭靠近行为
seekOff() {
this.offType(RavenBehaviorType.seek);
}
// 关闭徘徊行为
wanderOff() {
this.offType(RavenBehaviorType.wander);
}
...
// 靠近行为是否开启
seekIsOn(): boolean {
return this.on(RavenBehaviorType.seek);
}
// 徘徊行为是否开启
wanderIsOn(): boolean {
return this.on(RavenBehaviorType.wander);
}
...
}
下面实现了靠近、徘徊操控行为作用力的计算:
/**
* 实现seek(前往)行为
*/
private seekBH(target: Vec3): Vec3 {
let desireVelocity = new Vec3();
Vec3.subtract(desireVelocity, target, this._ravenBot.pos);
desireVelocity.normalize();
desireVelocity.multiplyScalar(this._ravenBot.maxSpeed);
desireVelocity.subtract(this._ravenBot.velocity);
return desireVelocity;
}
// 实现wander(徘徊)行为
private wanderBH(): Vec3 {
// 更新目标位置
this._wanderTarget.add3f(Util.getRandomFloat(-1, 1) * RavenCons.Steering_Wander_Jitter,
Util.getRandomFloat(-1, 1) * RavenCons.Steering_Wander_Jitter, 0);
this._wanderTarget.normalize();
this._wanderTarget.multiplyScalar(RavenCons.Steering_Wander_Rad);
let realTarget = new Vec3(this._wanderTarget);
realTarget.add3f(RavenCons.Steering_Wander_Dist, 0, 0);
// 转化为目标对象bot所处的空间
realTarget = GeometryHandyFuncs.pointToWorldSpace(realTarget, this._ravenBot.heading,
this._ravenBot.side, this._ravenBot.pos);
realTarget.subtract(this._ravenBot.pos);
return realTarget;
}
...
下面是计算作用力合力的接口:
// 尝试将力加到总转向力上,最大不超过maxforce,返回加成功与否
private accumulateForce(totalForceVec: Vec3, forceAddVec: Vec3): boolean {
let remainForce = this._ravenBot.maxForce - totalForceVec.length();
if (remainForce < math.EPSILON) return false;
let wantAddForce = forceAddVec.length();
if (wantAddForce < remainForce) {
totalForceVec.add(forceAddVec);
} else {
let canAddVec = new Vec3();
Vec3.normalize(canAddVec, forceAddVec);
canAddVec.multiplyScalar(remainForce);
totalForceVec.add(canAddVec);
}
return true;
}
/**
* 计算各操控力合并到一起的效果,受到maxforce限制
*/
private sumForces(): Vec3 {
// 分操控类型计算合力
let totalForce = new Vec3();
let force:Vec3 = null;
if (this.on(RavenBehaviorType.seek)) {
force = this.seekBH(this._target);
force.multiplyScalar(RavenCons.Steering_Seek_Weight);
if (!this.accumulateForce(totalForce, force)) {
return totalForce;
}
}
if (this.on(RavenBehaviorType.wander)) {
force = this.wanderBH();
force.multiplyScalar(RavenCons.Steering_Wander_Weight);
if (!this.accumulateForce(totalForce, force)) {
return totalForce;
}
}
...
return totalForce;
}
顺带一提,项目内大量使用了 Vec3 对象。
由于该对象每次使用都需要 new 出来,会出现频繁创建和销毁该对象内存的情况,影响运行效率。
本着使用简单的考量,项目内对接口内部要用到的临时 Vec3 变量,采用以下方式定义静态变量,接口内部只需要调用相应静态变量使用即可。
private static _???Temp: Vec3 = new Vec3();
或者
private static _???Vec: Vec3 = new Vec3()
这样避免了多次创建销毁,也免去使用对象池等技术,简化代码书写。
需要注意的是,这种用法尽量用于接口内部的临时变量,对于需要作为返回值使用的 Vec3,还是需要 new 出来才安全。
/**
* 调整bot转向来转到指定位置方向,如果转向成功则返回真。该方法受到bot的转向速率限制
*/
private static _rotateFacingTemp: Vec3 = new Vec3();
rotateFacingTowardPos(target: Vec3): boolean {
// 计算目标位置,与bot当前朝向的夹角
Vec3.subtract(RavenBot._rotateFacingTemp, target, this.pos);
RavenBot._rotateFacingTemp.normalize();
let dot = this._facing.dot(RavenBot._rotateFacingTemp);
if (dot < -1) dot = -1;
if (dot > 1) dot = 1;
let angle = Math.acos(dot);
// 角度很小时,直接设置转向
if (angle <= 0.01) {
this._facing.set(RavenBot._rotateFacingTemp);
return true;
}
...
}
路径规划
原书第8章讲述了路径规划技术,路径规划的核心是图搜索算法。
游戏中常用的图搜索算法有2种:Dijkstra 搜索算法和A星寻路算法。
根据不同的情况,这两种算法在项目内都有被用到:
1. A星寻路算法
当智能体需要攻击敌人时,起点和目标点都很明确,可以使用A星寻路算法。
该算法通过选择合适的启发函数,能够快速找到一条相对最优的路径。

2. Dijkstra 搜索算法
当智能体需要找到最近的道具时,由于地图上可能有很多道具,目标点不确定,此时更适合使用 Dijkstra 算法。
该算法会从起点开始遍历,直到找到离智能体最近的道具,从而规划出一条可行的路径。

以上两张图中,蓝色粗线是最终找到的路径,红色细线是算法搜索过的所有节点。
可以看出,A星算法在寻路时的效率更高。
但即使获得了路径节点,智能体也可能沿着曲折的路径前进,看起来不够智能。
为了解决这个问题,原书提供了路径平滑处理方案。
平滑处理的方案有两种实现:一种快速但效果粗糙,另一种精确但效率较低。
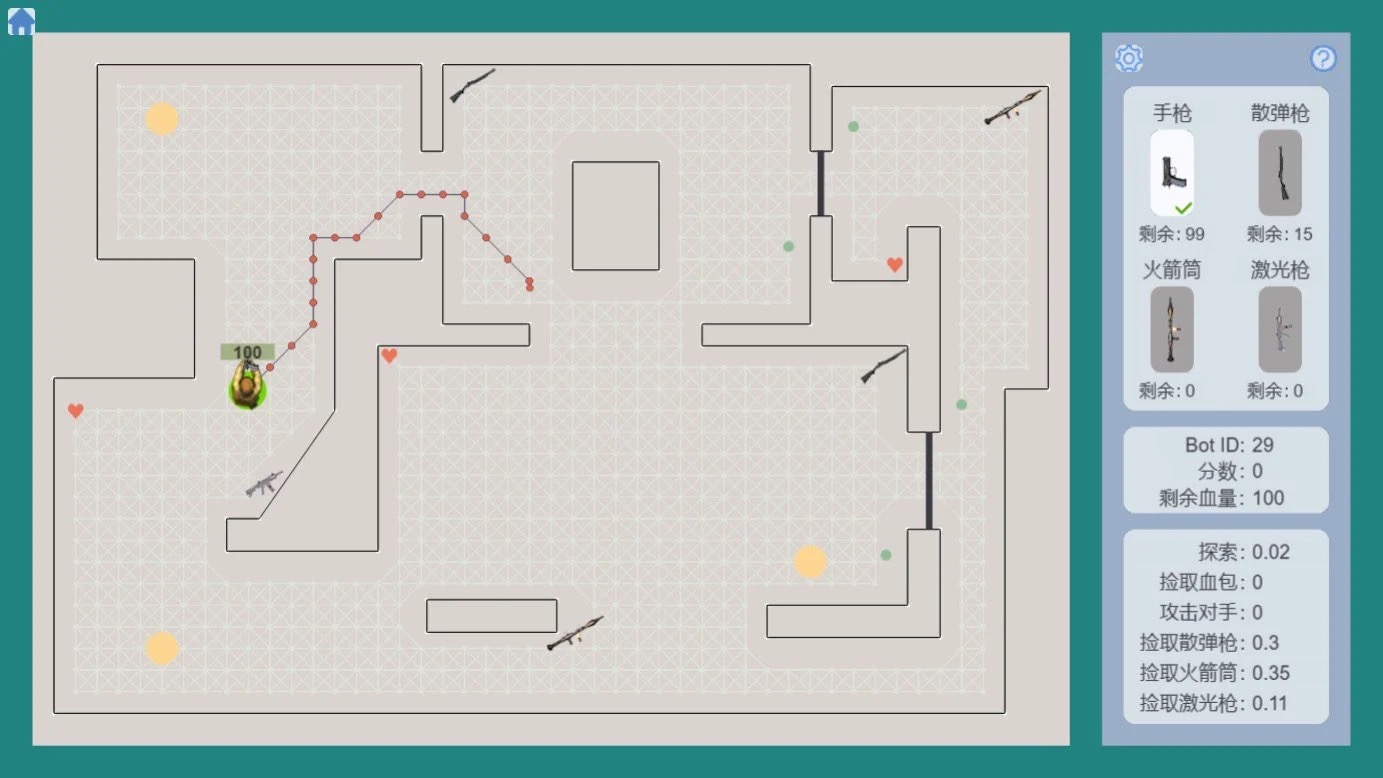
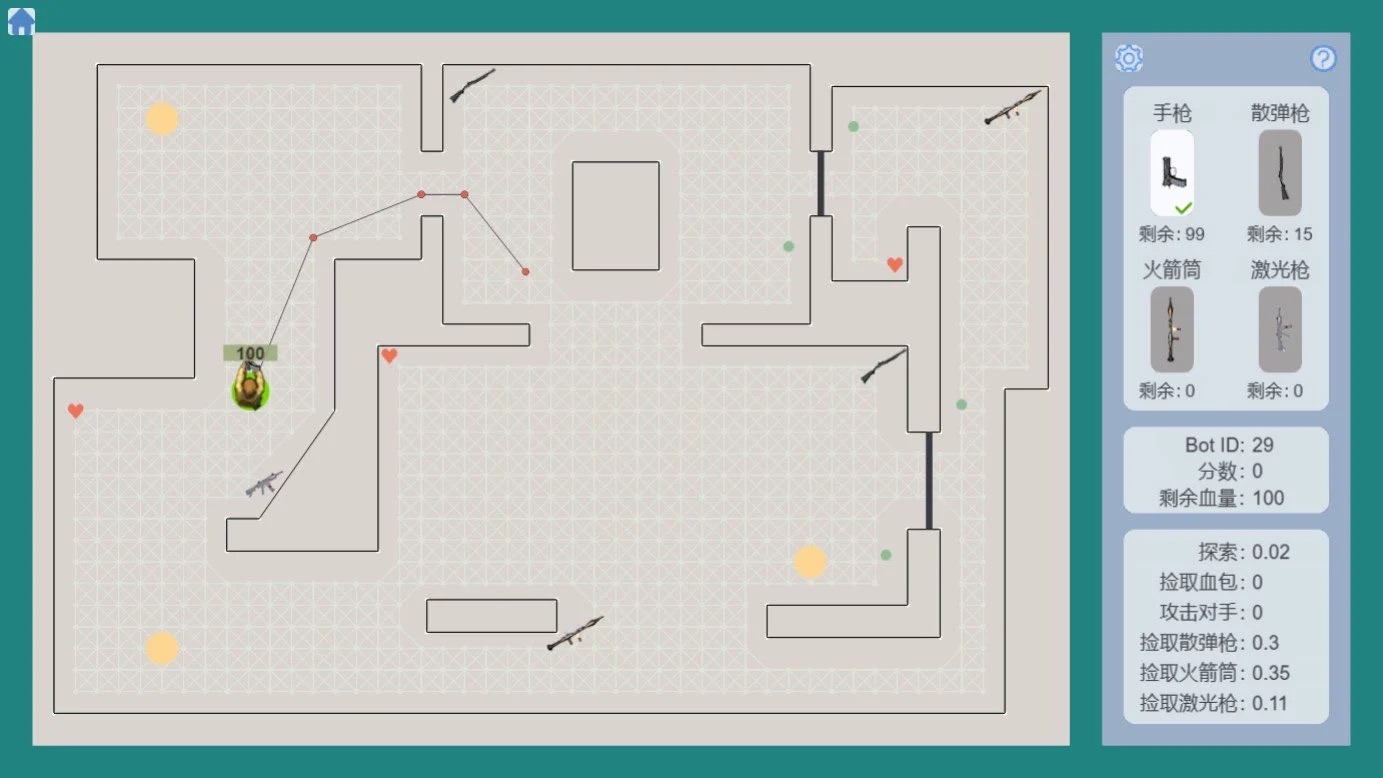
大家可以根据项目需求,选择最合适的方案,让寻路路径更加自然流畅。
/**
* Bot使用的路径规划类
*/
@ccclass('RavenPathPlanner')
export class RavenPathPlanner {
/**
* 快速去除多余边来优化路径
*/
private smoothPathEdgesQuick(path: Array<PathEdge>) {
let e1 = 0;
let e2 = 1;
while (e2 < path.length) {
if (path[e2].behavior == NavGraphEdgeFlagType.normal &&
this._owner.canWalkBetween(path[e1].source, path[e2].destination))
{
// 如果e1的起点到e2的终点,之间可以穿行,将e1的终点设置为e2的终点,则并移除e2这条边
path[e1].destination = path[e2].destination;
path.splice(e2, 1);
} else {
// e1到当前e2之间已不可穿行,则切换e1到e2的位置,e2定位到下一条边,继续路径优化
e1 = e2;
++e2;
}
}
}
/**
* 精确去除多余边来优化路径
*/
private smoothPathEdgesPrecise(path: Array<PathEdge>) {
let e1 = 0;
let e2 = 0;
while (e1 < path.length) {
e2 = e1 + 1; // 循环开始,e2指向e1的下一条边
while (e2 < path.length) {
if (path[e2].behavior == NavGraphEdgeFlagType.normal &&
this._owner.canWalkBetween(path[e1].source, path[e2].destination))
{
// 终于找到一个可以通行的e2终点,此时将e1的终点设置为e2的终点。
// 并且将,e1的下一条边到e2这条边之间的,所有边的移除,他们都用不到了
path[e1].destination = path[e2].destination;
let removeStart = e1 + 1;
let removeCount = e2 - removeStart + 1;
path.splice(removeStart, removeCount);
// 重新设置e2的位置,e1保持不变,接续前进
e2 = e1 + 1;
} else {
// e1到当前e2之间已不可穿行, 则仍不罢休,继续向着最后的边前进,直到所有的边都校验完毕
++e2;
}
}
// 以当前e1为起点的边已校验完毕,开启下一条边的校验
++e1;
}
}
...
}
在只有几个智能体的游戏里,无论采用 A 星还是 Dijkstra 的路径规划请求,所产生的运算消耗都是在可承受范围内。
但对于像拥有成百上千个智能体的 RTS 游戏,当需要频繁寻路时,性能会成为灾难。
为了解决这个问题,原书提供了时间片路径规划的解决方案。
它的核心思想是:
不一次性完成所有计算,而是将每个寻路请求拆分成多个小任务,按顺序分批处理。每次只执行一小部分计算,直到所有请求完成。
这能有效控制每帧的计算开销,避免游戏卡顿。
通过代码说明如下:
/**
* 统一调配所有路径规划实例
*/
@ccclass('PathManager')
export class PathManager {
private _searchRequests: Array<RavenPathPlanner> = []; // 所有请求搜索计划的列表
private _searchTimePerUpdate: number = 0; // 每次更新搜索时,最多占用的时间 ms
constructor(timeRatio: number) {
// 路径规划耗时占当前帧率时间的比例
if (timeRatio < 0.1) timeRatio = 0.1;
if (timeRatio > 0.5) timeRatio = 0.5;
let costTime = 1000 / (game.frameRate as number) * timeRatio; // 毫秒
this._searchTimePerUpdate = Math.max(1, costTime); // 至少1毫秒
console.log(`PathManager searchTimePerUpdate ${costTime} ms`);
}
/**
* 更新当前搜索路径列表
*/
updateSearchs() {
let startTime = Date.now();
let searchIndex = 0;
let checkCount = 0; //累计检测的数量,不需要每次循环都检测时间,这允许一定的时间误差
while (this._searchRequests.length > 0) {
// 对于每个搜索请求,通过cycleOnce接口,可以保证搜索循环只执行1次
let result = this._searchRequests[searchIndex].cycleOnce();
// 清理已经搜索结束的规划
if (result == TimeSlicedSearchState.targetFound ||
result == TimeSlicedSearchState.targetNotFound)
{
this._searchRequests.splice(searchIndex, 1);
} else {
++searchIndex;
}
// 循环搜索
if (searchIndex >= this._searchRequests.length) {
searchIndex = 0;
}
// 判断是否到最大搜索时间
++checkCount;
if (checkCount == 10) { // 循环每执行10次,进行一次超时判定
checkCount = 0;
if (Date.now() - startTime >= this._searchTimePerUpdate) {
break;
}
}
}
}
...
}
/**
* 时间片路径搜索的状态枚举
*/
export enum TimeSlicedSearchState {
searIncomplete, // 搜索尚未完成
targetFound, // 已经发现目标
targetNotFound, // 未发现目标
}
/**
* Bot使用的路径规划类
*/
@ccclass('RavenPathPlanner')
export class RavenPathPlanner {
private _owner: RavenBot = null; // 实例所属Bot
private _graph: RavenSparseGraph = null; // 导航图
private _curSearch: GraphSearchTimeSliced<RavenGraphEdge> = null; // 对应搜索算法实例
private _destPos: Vec3 = new Vec3(); // 目标点位置
/**
* 走一遍查找,根据查找结果,触发不同的消息
*/
cycleOnce(): TimeSlicedSearchState {
assert(!!this._curSearch, '<RavenPathPlanner.cycleOnce> No search object instantiated');
let result = this._curSearch.cycleOnce();
if (result == TimeSlicedSearchState.targetNotFound) {
// 通知查找失败
MessageDispatcher.instance().dispatchMsg(0, -1, this._owner.id,
RavenMsgType.msgNoPathAvailable);
} else if (result == TimeSlicedSearchState.targetFound) {
// 通知查找成功
let trigger: Trigger<RavenBot> = null;
if (this._curSearch.targetIdx() != invalidNodeIndex) {
trigger = this._graph.getNode(this._curSearch.targetIdx())?.extraInfo;
}
MessageDispatcher.instance().dispatchMsg(0, -1, this._owner.id,
RavenMsgType.msgPathReady, trigger);
}
return result;
}
...
}
该项目的地图创建方法也值得一提。
由于原书没有提供地图生成工具,笔者自制了一个简易的地图生成结构,可以快速构建地图数据。
原书作者提到可以通过洪水填充算法,来动态创建导航图数据。
笔者根据自己的理解,在本项目中实现了一版,其核心思路是广度优先遍历,让地图生成更加灵活。
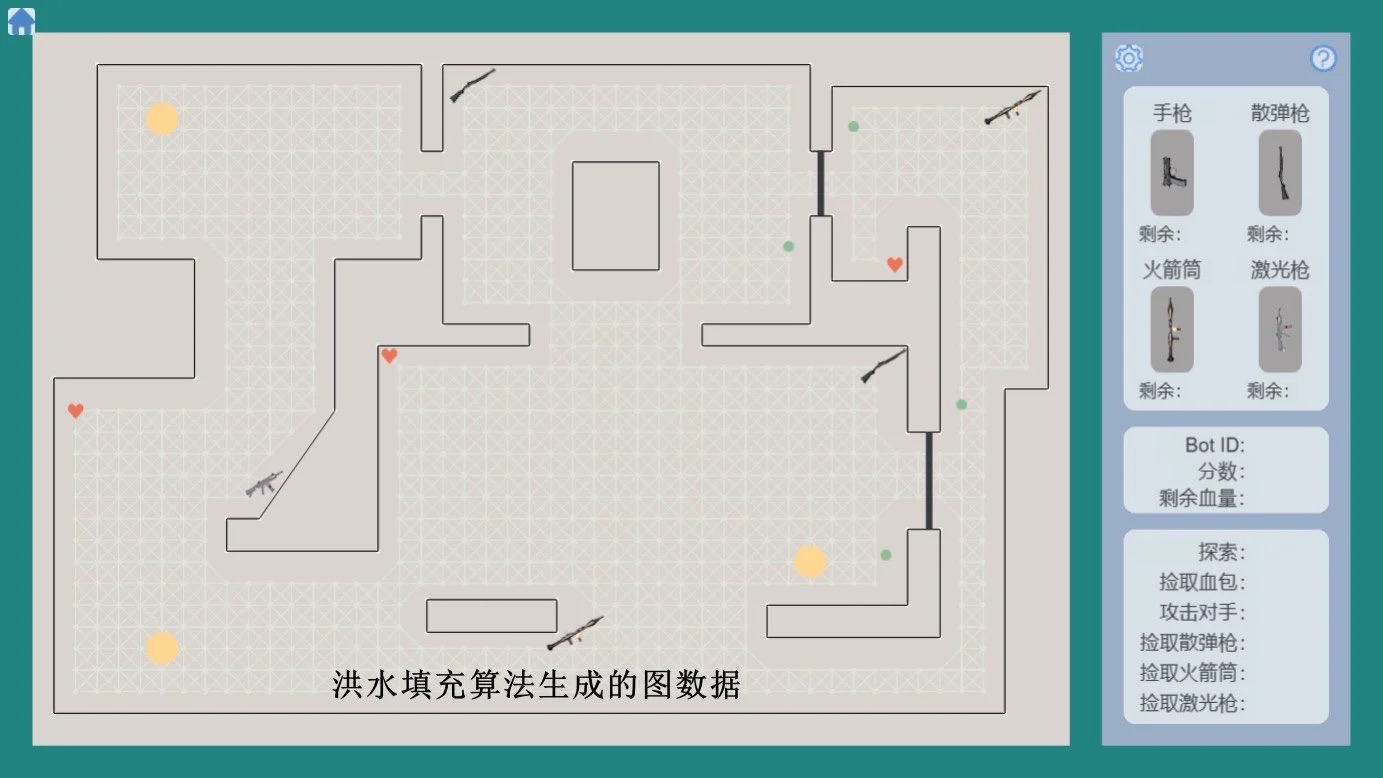
代码如下:
/**
* 洪水填充算法,构建导航图数据
*/
public static createGridByFloodFill<T, NodeType extends NavGraphNode<T>, EdgeType extends GraphEdge>
(graph: SparseGraph<NodeType, EdgeType>, firstNodePos: Vec3, edgeLen: number,
extraLen: number, wallPrefArr: Array<WallPref>)
{
let catchPos2NodeMap = new Map<string, NodeType>(); //已创建的图节点key缓存
let waitHandlePosQueue = new StackQueue<Vec3>(); // 待处理图节点队列
// 第一个节点先入队列
[firstNodePos.x, firstNodePos.y] = [Math.floor(firstNodePos.x), Math.floor(firstNodePos.y)];
let newNode = graph.nodeFactory(graph.nextFreeNodeIndex, {pos: firstNodePos});
graph.addNode(newNode as NodeType); // 图对象新增一个节点
let cposKey = `${firstNodePos.x}_${firstNodePos.y}`;
catchPos2NodeMap.set(cposKey, newNode as NodeType);
waitHandlePosQueue.push(firstNodePos.clone());
// 依次处理队列中的节点信息
while (!waitHandlePosQueue.empty()) {
// 将队首节点可连接的节点,添加进图
let handlePos = waitHandlePosQueue.pop();
// 取得跟指定节点相连接的8个边节点的坐标数据
let connectPosList = this.getConnectEdgeNodePosList(handlePos, edgeLen);
for (let cpos of connectPosList) {
// 排除跟墙壁相交的边
if (this.checkEdgeCrossWall(handlePos, cpos, extraLen, wallPrefArr)) continue;
// 添加节点
cposKey = `${cpos.x}_${cpos.y}`;
let isNewPos = !catchPos2NodeMap.has(cposKey);
if (isNewPos) {
newNode = graph.nodeFactory(graph.nextFreeNodeIndex, {pos: cpos});
graph.addNode(newNode as NodeType); // 图对象新增一个节点
catchPos2NodeMap.set(cposKey, newNode as NodeType);
waitHandlePosQueue.push(cpos.clone());
}
// 添加边
let handleKey = `${handlePos.x}_${handlePos.y}`;
let handleNode = catchPos2NodeMap.get(handleKey);
let cposNode = catchPos2NodeMap.get(cposKey);
if (!graph.isEdgePresent(handleNode.index, cposNode.index)) {
let dist = Vec3.distance(handlePos, cpos);
let newEdge = graph.edgeFactory(handleNode.index, cposNode.index, dist);
graph.addEdge(newEdge as EdgeType); // 图对象新增一个边
}
}
}
}
...
目标驱动
如果说寻路是AI的“脚”,那么目标驱动就是AI的“大脑”,它负责思考和决策。
对于目标驱动的技术,笔者拿上面的路径规划来举例。
大目标(如“前往指定位置”)可以分解为一系列可执行的子目标(如“跟随路径”)。
每个子目标再分解为更小的、可直接执行的动作(如“移动到下一个点”)。
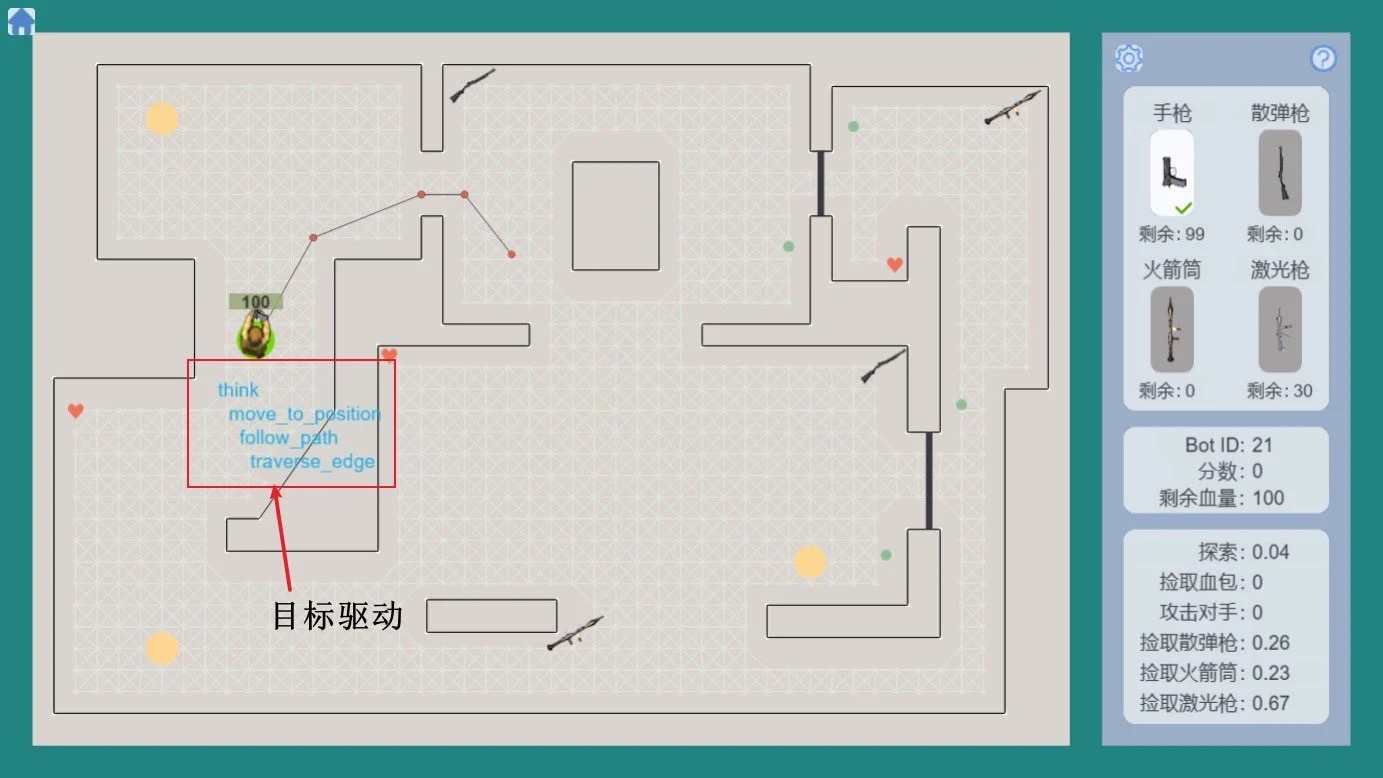
通过这种层级分解,智能体能将复杂的任务转化为简单的步骤,最终利用像“靠近”这样的操控行为来完成每个小任务。
这正是目标驱动的精髓所在。
原书详细讲解了每种类型目标驱动的实现解析与实现逻辑,下面简单列出2类目标类型的实现代码。
/**
* 前往指定的位置
*/
@ccclass('GoalMoveToPosition')
export class GoalMoveToPosition extends GoalComposite<RavenBot> {
private _targetPos: Vec3 = new Vec3();
constructor(bot: RavenBot, targetPos: Vec3) {
super(bot, RavenGoalType.goal_move_to_position);
this._targetPos.set(targetPos);
}
/**
* 激活目标处理
*/
activate() {
this._state = Goal_State.active;
this.removeAllSubgoals();
// 请求前往目标点的路径,在路径消息返回前,采用seek到目标位置的目标
if (this._owner.pathPlanner.requestPathToPos(this._targetPos)) {
this.addSubgoal(new GoalSeekToPosition(this._owner, this._targetPos));
}
}
/**
* 更新目标处理
*/
process(): Goal_State {
this.activateIfInactive();
this._state = this.processSubgoals();
// 如果未能成功到达目标点,则重新规划
this.reactivateIfFailed();
return this._state;
}
/**
* 终止目标处理
*/
terminate() {
super.terminate();
}
/**
* 处理消息
*/
handleMessage(msg: Telegram): boolean {
let isHandled = this.forwardMsgToSubgoal(msg);
if (isHandled) {
return true;
}
switch (msg.msg) {
case RavenMsgType.msgPathReady:
{
this.removeAllSubgoals();
this.addSubgoal(new GoalFollowPath(this._owner, this._owner.pathPlanner.getPath()));
return true;
}
break;
case RavenMsgType.msgNoPathAvailable:
{
this._state = Goal_State.failed;
return true;
}
break;
default:
return false;
}
return false;
}
}
/**
* 沿指定路径边移动
*/
@ccclass('GoalTraverseEdge')
export class GoalTraverseEdge extends Goal<RavenBot> {
private _edge: PathEdge = null; // 当前边
constructor(bot: RavenBot, edge: PathEdge, lastEdge: boolean) {
super(bot, RavenGoalType.goal_traverse_edge);
this._edge = edge;
}
/**
* 激活目标处理
*/
activate() {
this._state = Goal_State.active;
// 设置操控行为
this._owner.steering.target = this._edge.destination;
this._owner.steering.seekOn();
}
/**
* 更新目标处理
*/
process(): Goal_State {
this.activateIfInactive();
if (this._owner.isAtPosition(this._edge.destination)) {
this._state = Goal_State.completed;
}
return this._state;
}
/**
* 终止目标处理
*/
terminate() {
this._owner.steering.seekOff();
}
}
上面提到,智能体可以采用的大方向目标,有捡取回血道具、捡取武器、攻击其他智能体、前往地图中的指定位置等多种。
那么他又是怎么确定当前最适合自己的大目标是什么呢?
目标仲裁实现了这一选择方案。
通过获取智能体的信息(当前的健康度、距离最近的回血道具或者武器的距离、当前装备的强弱等),目标仲裁系统会给上述每个大方向目标进行打分。
得分最高的目标,就是当下采取的最优目标。
/**
* 顶层目标
*/
@ccclass('GoalThink')
export class GoalThink extends GoalComposite<RavenBot> {
private _evaluators: Array<GoalEvaluator<RavenBot>> = []; // 所有评估目标的列表
/**
* 评估后确定当前的目标
*/
arbitrate() {
let bestDesirability = 0; // 得分最高的目标分值
let bestEvaluator: GoalEvaluator<RavenBot> = null; // 得分最高的目标对象
for (let evaluator of this._evaluators) {
let desirability = evaluator.calcDesirability(this._owner);
if (desirability > bestDesirability) {
bestDesirability = desirability;
bestEvaluator = evaluator;
}
}
bestEvaluator.setGoal(this._owner);
}
...
}
目标驱动的应用远不止于此。你可以通过添加个性因子,让智能体变得胆小或勇敢,赋予其独特的行为倾向。
它还可以用来存储状态,按顺序执行多层子目标,实现命令排队,甚至用于编写脚本来控制 NPC、相机和动画。
总之,目标驱动技术能为你处理游戏逻辑带来全新的思路。一旦掌握,你可能也会像笔者一样,爱不释手。
写在最后
项目中还包括原书中讲解的其他技术,像状态机、触发器、图搜索算法、模糊逻辑等等。
对于上文未提到的技术,还请大家到原书中阅读。
希望通过该项目的辅助,大家可以更快更好的在 Cocos Creator 中,实现自己需要的技术。

即拿即用
原书中所有的 C++ 案例,本项目都用 TS 语言在 Cocos Creator 3.8.6 中完整实现。
希望能通过这种方式,让大家理解起来可以轻松一些。
性能考虑
原书的示例没有考虑帧率对物理计算的影响,这在真实项目中是行不通的。
本项目的所有物理计算都考虑了 deltaTime 参数,确保游戏在不同设备上运行时的表现一致。
游戏 AI 的本质
好的技术就像养料,它会变成巨人的肩膀,新技术的基石。学习这些经典技术,能为你打开处理游戏逻辑的新思路。

最后,引用原作者 Mat Buckland 先生的一句话作为结束:
“一个极其聪明,几乎无可匹敌的对手,对游戏人工智能程序员来说,这是罕见的目标。一个好的人工智能应具有一个目的:
就是让玩游戏变得比较有趣。
经常提醒自己这一点是明智的,请相信我,这一点很容易错过并能使你陷入困境。
因为你试图制造人类已知的最聪明的游戏智能体,而不是试图制造哪种能使玩家大笑,并且开心雀跃的游戏智能体。”
项目源码可以点击这里获取。
感谢阅读,希望这篇文章能给大家带来帮助!
 ,见文章开头的介绍
,见文章开头的介绍