
给大佬顶一个
我理解是包体吧, 通常情况下 PNG8(TinyPNG) 压缩后是比 ASTC小; 如果目标是减少包体 对于 UI、图标、带大量透明区域的素材,优先用 PNG/PNG8的 atlas;对场景贴图、法线贴图、位图照片类用 ASTC。
niuBi
大佬六百六十六
真的是应用AI去落地解决游戏问题了,而不是虚有其表的去讲AI
老板看到了会怎么想
鸿蒙的DevEco 可以直接ai测试ccc吗还是说要生成指定包来测试
用AI也是需要技术的
666
只是测试下发热和耗电
插眼 66666
niubi
666
666666 
邪修之为什么大量node.active 性能差, 比如数千个node 再update里 active = true/false
我们先看下node内部发生了什么
大量调用 node.active 会触发节点及其子孙的生命周期回调(preload/onEnable/onDisable)、组件启用、变换和渲染数据重建,导致大量 CPU 开销和可能的内存分配/GC。一次性激活或频繁切换很多节点还会打乱渲染批次
public activateNode (node: Node, active: boolean): void {
if (active) {
const task = activateTasksPool.get();
if (task) {
this._activatingStack.push(task);
this._activateNodeRecursively(node, task.preload, task.onLoad, task.onEnable);
task.preload.invoke();
task.onLoad.invoke();
task.onEnable.invoke();
this._activatingStack.pop();
activateTasksPool.put(task);
}
} else {
this._deactivateNodeRecursively(node);
// remove children of this node from previous activating tasks to debounce
// (this is an inefficient operation but it ensures general case could be implemented in a efficient way)
const stack = this._activatingStack;
for (const lastTask of stack) {
lastTask.preload.cancelInactive(IsPreloadStarted);
lastTask.onLoad.cancelInactive(IsOnLoadStarted);
lastTask.onEnable.cancelInactive(IsOnEnableCalled);
}
}
node.emit(NodeEventType.ACTIVE_IN_HIERARCHY_CHANGED, node);
}
怎么优化?
这里有2个思路
普通版
- 手动管理Node的Visible, 不渲染或者超出屏幕边界时候 我们设置成null, 同时使用init 作为激活函数名, 不实用默认的onEnable, 这个方案对于3D是比较友好了
function enqueueRenderObject (model: Model): void {
// filter model by view visibility
if (model.enabled) {
if (scene.isCulledByLod(camera, model)) {
return;
}
if (model.castShadow) {
castShadowObjects.push(getRenderObject(model, camera));
csmLayerObjects.push(getRenderObject(model, camera));
}
if (model.node && ((visibility & model.node.layer) === model.node.layer)
|| (visibility & model.visFlags)) {
// frustum culling
if (model.worldBounds && !geometry.intersect.aabbFrustum(model.worldBounds, camera.frustum)) {
return;
}
renderObjects.push(getRenderObject(model, camera));
}
}
}
for (let i = 0; i < models.length; i++) {
enqueueRenderObject(models[i]);
}
邪修版
但对于2D 3D 大量伤害文字和特效, 设置成null, 会影响batcher2D 的排序;
2D文字/3D特效/拖尾混排
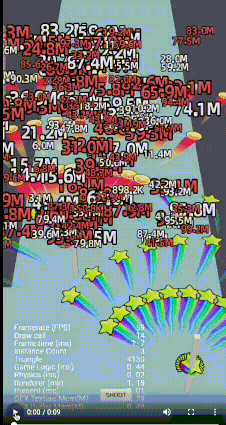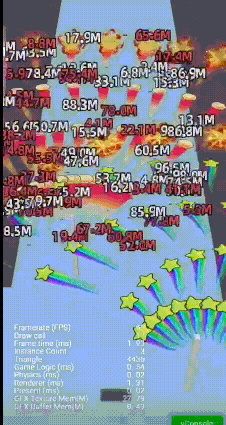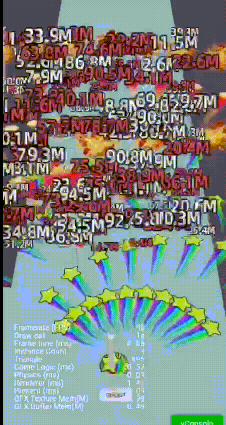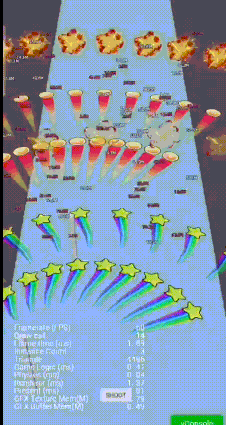
优化重构assembler, 上万文字,脱尾,特效, 2个assembler 搞定, 同时保证三角面的有序culling
我们在assembler里面也做了3个优化
- 预创建 预先创建好极限大小的buffer, 如果超过, 会把有限时间的移除
- 位置分配 针对光污染特效, 单独一个assembler不去做特定排序(不过先来后到 数量大的时候, 不会很明显) 通过slot 预先分配, 先不用删除, 把能用的slot 给后续节点, 比如有1000个再跑的特效, 有500个要删除, 先添加了300个, 这时候我们通过 vbF32.fill/iBuffer.fill 更新到指定长度就可以了, 前面的数据
private _createBuffers(maxVertCount: number, maxIndexCount: number): EffectBuffer {
const device = director.root!.device;
const vbByteLength = maxVertCount * MultiEffect.VERTEX_SIZE;
const ibByteLength = maxIndexCount * 2;
const vbF32 = new Float32Array(maxVertCount * MultiEffect.FLOATS_PER_VERT);
const iBuffer = new Uint16Array(maxIndexCount);
const vertexBuffer = device.createBuffer(new gfx.BufferInfo(
gfx.BufferUsageBit.VERTEX | gfx.BufferUsageBit.TRANSFER_DST,
gfx.MemoryUsageBit.HOST | gfx.MemoryUsageBit.DEVICE,
vbByteLength,
MultiEffect.VERTEX_SIZE
));
const indexBuffer = device.createBuffer(new gfx.BufferInfo(
gfx.BufferUsageBit.INDEX | gfx.BufferUsageBit.TRANSFER_DST,
gfx.MemoryUsageBit.HOST | gfx.MemoryUsageBit.DEVICE,
ibByteLength,
2
));
return { vertexBuffer, indexBuffer, vbF32, iBuffer };
}
private _processRemovals(config: MatConfig) {
if (!config.hasRemovals) return;
const effs = config.effList!;
let i = 0;
while (i < effs.length) {
const eff = effs[i];
if (eff.remove) {
config.freeSlots!.push(eff.slotIndex);
this._clearEffectBuffer(eff);
// 使用 splice 保持数组连续性
effs.splice(i, 1);
} else {
i++;
}
}
config.hasRemovals = false;
}
private _clearEffectBuffer(eff: EffectConfig) {
const buffers = eff.matConfig!.buffers!;
const mat = eff.matConfig!;
const length = mat.maxLength!;
const shapeCount = 2;
const vertexCount = length * shapeCount * MultiEffect.FLOATS_PER_VERT;
const vbStart = eff.offset;
const indexCount = (length - 1) * (eff.shapeCount - 1) * 2 * 3;
const ibStart = eff.indexOffset;
buffers.vbF32.fill(0, vbStart, vbStart + vertexCount);
buffers.iBuffer.fill(0, ibStart, ibStart + indexCount);
EffectPool.put(eff);
}
3赞
牛逼呀大佬
鬼才啊 二喵酱
有这种小型优化的demo就好了,开箱即用,放store里卖也好
特定领域ai大显神通