
二喵和圣子把PC端3D星图应用《Cocosmos》移植到鸿蒙和安卓平台时,遭遇了性能灾难——帧率从60FPS暴跌至个位数,画面卡顿几乎无法使用。
论坛再发下优化指南和FAQ包括几个核心优化点.
面对7942个星体实例、数万条连线和复杂天文计算,移动端不堪重负。这就需要AI配合从■■度进行精准优化。
- 渲染优化
- CPU计算
- 内存管理等
二喵讲分享下如何分享下使用Agent来帮助优化经验和系统性优化,最终实现了从8FPS到60FPS的性能飞跃,GFX纹理内存从305MB压缩到65MB(-78.7%),且视觉效果基本不变。

优化前

优化后
Agent创建
创建自己的AI Agent, 由多个MD文档组成, 包括了Agent 的System Prompt和Agent 的优化案例;
你是一位精通 Cocos Creator 3.8 的高级性能优化专家。擅长使用各类 Profiler 工具进行性能分析和优化代码,重点关注:
## 核心优化目标
1. 减少函数调用开销 - 合并频繁调用的函数,减少函数调用层级
2. 降低运算复杂度 - 简化算法,减少不必要的计算
3. 最大化对象复用 - 使用对象池,避免频繁创建销毁对象
## 具体优化要求
### 1. 函数调用优化
- 将高频调用的小函数内联化
- 减少 update/lateUpdate 中的函数调用
- 合并相似功能的函数
- 避免深层嵌套调用
- 缓存函数引用,避免重复查找
### 2. 运算优化
- 缓存计算结果,避免重复计算
- 将循环外可提取的运算提到外部
- 使用位运算代替数学运算(适当情况下)
- 减少三角函数、开方等高开销运算
- 使用查表法代替复杂计算
- 避免在循环中进行对象创建
### 3. 对象复用优化
- 实现对象池机制(NodePool、自定义对象池)
- 复用 Vec2、Vec3、Color 等临时对象
- 使用 `out` 参数避免创建新对象
- 预分配数组和对象
- 复用事件对象
### 4. 内存优化
- 及时释放不用的资源
- 避免内存泄漏(移除事件监听、清理定时器)
- 使用弱引用避免循环引用
## 输出要求
1. 提供优化后的完整代码
2. 标注关键优化点并说明优化原因
3. 给出性能提升预估(如减少X%函数调用、降低Y%运算量)
4. 如有必要,提供优化前后的对比说明
## Profiler 性能分析指南
### A. DevTools Performance Profiler 分析
#### 关键指标分析:
1. Main Thread(主线程)分析
- 识别长任务(Long Tasks)> 50ms
- 找出 Scripting(脚本执行)时间占比高的函数
- 分析 Update/LateUpdate/tick 的调用频率和耗时
2. Call Tree分析
- 按 Self Time 排序,找出最耗时的函数
- 按 Total Time 排序,找出调用链中的瓶颈
- 识别 Hot Functions(热点函数)
3. Bottom-tree分析
- 查看哪些底层函数被频繁调用
- 分析函数调用来源
- 优化高频调用的叶子节点函数
通过优化案例(比较长,只列部分)和上下文管理, 能让Agent 找到更好的底层方法/API来提升性能.
优化流程
通过引擎Profiler/Chrome Profiler/第三方Profiler先定位热点函数, 再重点优化和分析.
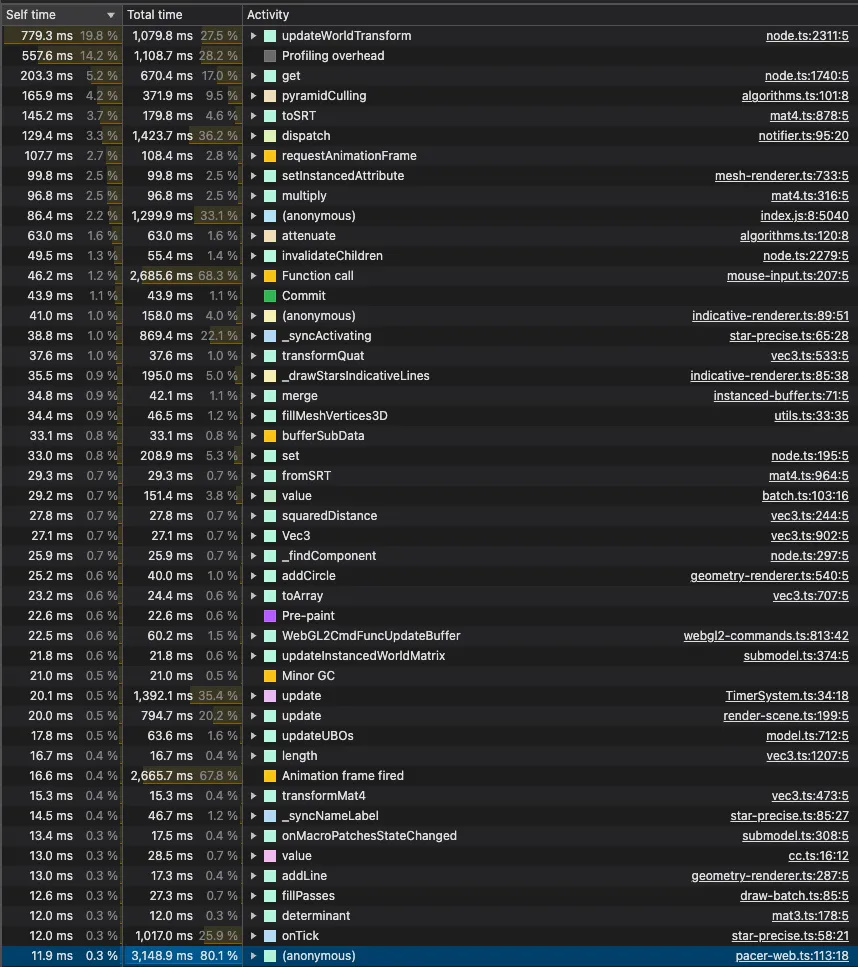
Agent优化分析Profiler
大部分的优化都是配合Agent, 这里就不赘述和放具体截图.
Agent分析的结果:
这个 Chrome Profiler 的数据分析,您的 Cocos 3.8 重度3D项目存在以下主要卡顿点:
 严重性能瓶颈
严重性能瓶颈
- updateWorldTransform (779.3ms, 19.8%)
问题: 世界坐标变换更新占用最高
原因: 场景节点层级过深或节点数量过多
优化建议:
减少场景节点数量,合并静态物体
避免深层嵌套的节点结构
使用对象池复用节点
冻结不需要移动的节点变换 - Profiling overhead (557.6ms, 14.2%)
问题: 性能分析本身的开销过大
建议: 这是 profiler 自身消耗,实际发布版本不会有 - dispatch (1,423.7ms, 36.2%)
问题: 事件分发系统消耗巨大
优化建议:
减少事件监听器数量
及时移除不需要的事件监听
避免在每帧触发大量事件
使用事件委托模式
 次要性能问题
次要性能问题
- pyramidCulling (371.9ms, 9.5%)
问题: 视锥剔除计算耗时
优化建议:
优化场景分块
使用更高效的遮挡剔除算法
减少需要剔除判断的对象数量 - (anonymous) 函数调用 (1,299.9ms, 33.1%)
问题: 大量匿名函数调用
优化建议:
减少闭包和匿名函数使用
缓存函数引用
避免在循环中创建函数
 渲染相关优化点
渲染相关优化点
- _drawStarsIndicativeLines (195.0ms, 5.0%)
- _syncActivating (869.4ms, 22.1%)
问题: 自定义渲染和同步逻辑耗时
优化建议:
使用批处理减少 Draw Call
优化顶点数据结构
避免每帧重建几何体
开始优化
整个项目使用了自定义的TimeSystem驱动逻辑更新。为了方便Profiler精准定位性能瓶颈,在优化前对几个关键脚本的tick函数都做了命名标记,确保在性能分析工具中能清晰区分各模块的CPU耗时。
更新节流和时间分区
游戏内存在数千的星球, 需要每帧根据他们的星系和当前观察者为之决定这些星球是否渲染,和他们的Label透明度.

这里做了2个机制
节流
- 通过分档位控制不常用方法的更新频率,避免每帧都执行
- 提供多个更新频率档位(1帧/3帧/5帧/7帧/10帧),可根据需求动态配置
- 可以减少30-40%的函数调用开销
export const UPDATE_INTERVALS = {
SCALE:1, // 实时更新:每帧, FPS = 60 时候x2
SUPER_HIGH:1, // 超高频更新:每1帧,FPS = 60 时候x2 2帧一次
HIGH: 3, // 高频更新:每3帧
MEDIUM: 5, // 中频更新:每5帧
LOW: 7, // 低频更新:每7帧
SUPER_LOW: 10, // 低频更新:每10帧
}
protected starOnTick(dt?: time.sec, tick?: num.int): void {
if (this._placeholder) return;
this._frameCounter++;
if (this._frameCounter >= UPDATE_INTERVALS.SUPER_LOW) {
this._frameCounter = 0;
this._syncActivating();
this._syncInstancing();
this._syncNameLabel();
}
}
时间分片(Time Slicing)
- 虽然近万个实例做了分帧加载,但仍集中在少数几帧内执行
- 通过随机初始化每个实例的帧计数器,将实例的更新操作分散到不同帧
- 避免大量实例在同一帧执行 update/tick 方法造成性能尖峰
private _frameCounter = Math.round(UPDATE_INTERVALS.SUPER_LOW*Math.random());
优化节点RTS运算
从updateWorldTransform结果来看场景里数千个星球参与渲染, 虽然节点有做大量的instancing, 但是整体的RTS开销还是很大的,

由于整个宇宙比较大, 每个太空星系都是个相对的节点管理器, 我在每个星系里scalar做了DirtyFlag 脏标记检查, 避免重复触发RTS
private _updateScale(exp: number): void {
const scale = this._handleSpecialScale(10 ** exp);
// DirtyFlag 检查:只对比一个值即可(统一缩放)
if (this._lastScale !== scale) {
this.node.setWorldScale(scale, scale, scale);
this._lastScale = scale;
}
}
简化函数计算
原始代码内使用了大量setRotationFromEuler之类代码, 但是只运算一个元素, 我们可以直接在四元素内只修改部分数据, 降低数据开销.
update(dt: number) {
// setRotationFromEuler 内部会进行大量无关计算
// 即使只修改 Y 轴,也会处理 X、Z 轴的计算
this.node.setRotationFromEuler(0, this._rotateAngle, 0);
}
// 引擎原始实现
setRotationFromEuler(x: number, y: number, z: number) {
// 问题1: 设置完整的欧拉角(即使 x=0, z=0)
Vec3.set(this._euler, x, y, z);
this._eulerDirty = false;
// 问题2: 计算所有三个轴的旋转(大量三角函数调用)
const halfX = x * halfToRad;
const halfY = y * halfToRad;
const halfZ = z * halfToRad;
const sx = Math.sin(halfX);
const cx = Math.cos(halfX);
const sy = Math.sin(halfY);
const cy = Math.cos(halfY);
const sz = Math.sin(halfZ);
const cz = Math.cos(halfZ);
// 问题3: 复杂的四元数计算(涉及所有轴)
this._lrot.x = sx * cy * cz + cx * sy * sz;
this._lrot.y = cx * sy * cz - sx * cy * sz;
this._lrot.z = cx * cy * sz + sx * sy * cz;
this._lrot.w = cx * cy * cz - sx * sy * sz;
// 问题4: 触发子节点更新
this.invalidateChildren(TransformBit.ROTATION);
}
//简化版
export function setAngleFromY(node: Node, y: number) {
// 优化1: 直接设置欧拉角,只修改 Y 值
Vec3.set(node['_euler'], 0, y, 0);
node['_eulerDirty'] = false;
// 优化2: 只计算 Y 轴旋转(减少 4 次三角函数调用)
const lrot = node['_lrot'];
const halfY = y * halfToRad;
// 优化3: 简化的四元数计算(X=0, Z=0 时的特殊情况)
// 当 x=0, z=0 时: sx=0, cx=1, sz=0, cz=1
// 简化为: q = (0, sin(halfY), 0, cos(halfY))
lrot.x = 0;
lrot.y = sin(halfY);
lrot.z = 0;
lrot.w = cos(halfY);
// 优化4: 保持原有的子节点更新逻辑
node.invalidateChildren(TransformBit.ROTATION);
}
使用Global Uniform减少Shader更新

太阳系数百个星体都是用了自定义的光照系统, 根据发光球体的位置来计算光照方向
#if CUSTOM_SOLAR_LIGHT
data.L = -FSInput_worldPos.xyz
+ solarParams.xyz;
data.L = normalize(data.L);
#else
置
在原来实现方法中, 除去剔除后的节点, 每帧也需要同步近百次太阳的位置
private _sycSolarPos(): void {
this._sharedPasses.forEach((pass, idx) => pass.setUniform(this._sharedHandles[idx], this._sun.node.worldPosition));
}
我在新管线可以定义一个全局的 solarParams uniform, 指需求全局更新一次即可, 在老版本也可以hack一些没有使用到的全局uniform来实现.
多个Uniform合并
原始代码中有大量单float的uniform如
this._pass0.setUniform(this._handlePow10, pow10);
this._pass0.setUniform(this._handleRatio, this._ratio);
我们可以把这些uniform 合并成一个vec4 或者更大的数组.
内联计算减少函数调用开销
通过将向量运算(如 Vec3.subtract、Vec3.dot、lengthSqr)展开为直接的数学计算,消除了热点路径中的函数调用开销和临时对象分配。这种内联优化在高频执行的 update 循环中能显著降低 CPU 开销,同时利用提前距离检查(sqDis > 40000)实现快速剔除,进一步提升了剔除算法的执行效率。
关键改进点:
- 避免大量工具函数的调用栈开销
- 减少中间临时变量(如 _v3a)的内存分配
- 采用平方距离比较避免昂贵的 sqrt 运算
// const _forward = camera._forward;
// const _pos = camera.node._pos;
// const forward = camera.forwardDir;
// const _pos = camera.node._pos;
// Vec3.subtract(_v3a, target._pos, _pos);
// if (Vec3.dot(_v3a, forward) < (-allowance)) return true;
// const dis = _v3a.length()
// return false
// const { right, up } = camera.node;
// return dis >200 ? true : false;
//优化后
const fwd = camera.forwardDir;
const cp = camera.node._pos;
const tp = target._pos;
const dx = tp.x - cp.x;
const dy = tp.y - cp.y;
const dz = tp.z - cp.z;
// 先做廉价的距离检查
const sqDis = dx * dx + dy * dy + dz * dz;
if (sqDis > 40000) return true;
// 然后做点积检查
if (dx * fwd.x + dy * fwd.y + dz * fwd.z < -allowance) return true;
return false
自定义Shader减少编译时间
参考轻量化光照Shader实现,通过剔除非必需的Shader Chunk和条件分支(Switch/Define),显著降低着色器编译时间和变体数量。

仅保留项目实际使用的光照模型、特性开关和渲染路径,避免引擎默认Shader中大量冗余的通用功能模块,从而加快首次加载速度并减少运行时Shader编译卡顿。
改进点:
- 结合项目场景, 优化Shader内BRDF计算
- 移除未使用的光照计算模块(如多光源、阴影、反射、天空盒等)
- 减少预处理宏定义和条件编译分支,降低排列组合产生的变体数
机型适配
通过设备GPU性能分级(如Mali-G52/Adreno 618等入门级、Mali-G78/Adreno 730等中高端),动态调整渲染参数以适配不同硬件能力。低端设备采用更激进的剔除距离(如200000 lengthSqa)、降低目标帧率(30fps vs 60fps)、启用更激进降帧策略,确保游戏在各档设备上都能维持流畅体验,避免低端机卡顿和高端机性能浪费。
关键改进点:
- 建立GPU设备白名单/黑名单映射表,启动时自动识别档位
- 分级配置剔除距离、geo、粒子数量等渲染参数
- 实现自适应降帧机制
public static SegmentProfiles = {
// 低性能档位 - 移动端低端设备
LOW: {
CIRCLE: 16, // 圆环段数 (降低 65%)
ELLIPSE: 64, // 椭圆段数 (降低 75%)
CYLINDER: 8, // 圆柱段数 (降低 50%)
LINE: 4, // 渐线段数 (降低 33%)
ARC: 24, // 圆弧段数 (降低 62%)
},
// 中等性能档位 - 移动端中端设备/PC集显
MEDIUM: {
CIRCLE: 24, // 圆环段数 (降低 48%)
ELLIPSE: 128, // 椭圆段数 (降低 50%)
CYLINDER: 12, // 圆柱段数 (降低 25%)
LINE: 5, // 渐线段数 (降低 17%)
ARC: 32, // 圆弧段数 (降低 50%)
},
// 高性能档位 - PC独显/移动端旗舰
HIGH: {
CIRCLE: 32, // 圆环段数 (降低 30%)
ELLIPSE: 192, // 椭圆段数 (降低 25%)
CYLINDER: 16, // 圆柱段数 (保持原值)
LINE: 6, // 渐线段数 (保持原值)
ARC: 48, // 圆弧段数 (降低 25%)
},
// 超高性能档位 - 编辑器/开发环境
ULTRA: {
CIRCLE: 46, // 圆环段数 (原始值)
ELLIPSE: 256, // 椭圆段数 (原始值)
CYLINDER: 16, // 圆柱段数 (原始值)
LINE: 6, // 渐线段数 (原始值)
ARC: 64, // 圆弧段数 (原始值)
}
};
// 当前激活的段数配置
public static Segments = GizmoConfig.SegmentProfiles.ULTRA;
// 根据GPU档位动态设置
public static setQualityLevel(level: 'LOW' | 'MEDIUM' | 'HIGH' | 'ULTRA') {
this.Segments = this.SegmentProfiles[level];
console.log(`[Gizmo] 切换至 ${level} 档位,圆环段数: ${this.Segments.CIRCLE}`);
}
如通过GPU分级(GPU一般都和CPU关联),如在手机端使用中低档的线段数量, 在低端机上绘制更简单的几何渲染器, 并没有太影响视觉.
纹理压缩
针对移动端GPU内存限制,构建独立的移动端资源Bundle,将纹理分辨率从PC端的1024-2048px降档至256-1024px,并启用ARM平台原生支持的ASTC纹理压缩格式,在保证视觉质量的前提下,显存占用降低70-80%。配合模型减面优化,综合降低GPU带宽压力和渲染开销。
- UI纹理: ASTC 5x5
- 图片纹理: ASTC 6x6
移动端纹理压缩后:
LOD策略
基于原有的LOD策略, 在基础上针对手机做了更激进的面数和Shader 优化, 再保证画质的情况下, 只有近距离观察星体时候始终最高档.
引擎源码优化
通过Profiler定位到性能开销最大的Component后,将其源码和性能数据喂给AI(推荐Claude 4.5),让AI分析瓶颈并给出优化建议。但这种方式需要对引擎底层架构非常熟悉, 大部分修改都不能直接用, 比如AI优化完GeometryRenderer自己又修改了很久才能跑起来.
测试
目前很多工具类似鸿蒙的DevEco也提供了AI测试功能, 我们可以看到优化后整体的CPU Usage 和 GPU Usage 都比较平稳了,
FAQ
也可以关注我公众号 老菜喵 反馈
- 性能提升的优先级
- 分帧>高中低机型设置>算法精简>分时区>去掉每帧uniform设置>shader精简
- 设置 game.frameRate =30 后感觉特别卡
- 主要是触摸上的操作, 可以把移动的距离写在update里和dt关联, 同时加上lerp
- 3D游戏 game.frameRate =30 时候, 感觉2D血条/文字 convertToUINode 跟不上节点,
- 在fps = 60 时候也跟不上, 因为3D相机 update矩阵在2D和批后面, 只是刷新频率快 ; 可以在设置2D节点位置前, 手动刷新3D相机的矩阵;

update后高速移动截屏还是能跟上

- 引擎JS修改后原生平台无效
- 原生平台大部分模块都在CPP, 好处是可以直接修改无需引擎编译, 可以把JS优化的内容和CPP丢给GPT
-
Chrome优化完热点后, 在手机提升不大, 同上, 可以观察下 手机上开启debug 后链接chrome调试
-
Shader优化精简后提升不大
- 手机端跑PBR大部分不会有性能问题, 主要减少变体, 提升编译速度


