背景知识
什么是 SDF 字体
传统的位图字体(BMFont)将每个字符渲染成像素图片,拼在一张大的纹理图集上。这种方式有一个明显的缺点:放大后会模糊,缩小后会丢失细节。
SDF(Signed Distance Field,有符号距离场)字体用了一种不同的思路:它不直接存储字符的像素颜色,而是存储每个像素到字符边缘的距离。
- 距离值 > 0.5:像素在字符内部
- 距离值 < 0.5:像素在字符外部
- 距离值 = 0.5:像素恰好在边缘上

渲染时,shader 读取这个距离值,用阈值 0.5 判断"这个像素应该显示还是透明"。因为距离场是连续的数学量,无论怎么缩放,边缘都可以被精确重建——这就是 SDF 字体在任意尺寸下都保持锐利的原因。
什么是纹理通道
一张纹理图片的每个像素由四个分量组成:R(红)、G(绿)、B(蓝)、A(透明度),即 RGBA 四通道。
你可以把一张 RGBA 纹理想象成四张叠在一起的灰度图,每张各自独立,互不干扰:
| 通道 | 含义 | 取值范围 |
|---|---|---|
| R | 红色分量 | 0.0 ~ 1.0 |
| G | 绿色分量 | 0.0 ~ 1.0 |
| B | 蓝色分量 | 0.0 ~ 1.0 |
| A | 透明度 | 0.0 ~ 1.0 |
普通的彩色图片需要 RGB 三个通道配合才能表达颜色。但 SDF 字体的数据只是一个"距离值"——单通道灰度数据,一个通道就够了。
问题
理解了上面两个概念,问题就清晰了。
SDF 字体的本质是单通道数据,但常规做法是把它存成灰度图——RGBA 四个通道的值完全相同:
一张常规 SDF 字体纹理(2048 x 2048)
通道 存储内容 示例值 R 距离值 0.73 G 距离值 0.73 B 距离值 0.73 A 距离值 0.73 四个通道存了完全相同的数据。有效信息 1 份,实际占用 4 份,空间利用率仅 25%。
对于英文来说,ASCII 可打印字符不到 100 个,一张纹理绰绰有余,浪费就浪费了。
但如果你的游戏需要支持中文——光"常用汉字"就有 3500 个,加上标点符号和常用字更多——纹理空间会非常紧张。在移动端,一张 2048x2048 的纹理已经不小了。如果装不下,就得用两张纹理,带来额外的纹理切换开销和显存占用。
一个自然的想法是:既然 SDF 只需要一个通道的数据,能不能让 RGBA 四个通道各自独立存储一批字符?
理想情况:通道合并后的 SDF 字体纹理
通道 存储内容 R 第 1 组字符的距离值 G 第 2 组字符的距离值 B 第 3 组字符的距离值 A 第 4 组字符的距离值 同样一张纹理,容量变为 4 倍。
写入容易——生成工具可以控制把数据写到哪个通道。难点在读取:渲染时,shader 怎么知道当前这个字符应该从哪个通道读?
常规思路及其代价
最直接的方法是显式告诉 shader 通道信息:
| 方法 | 做法 | 代价 |
|---|---|---|
| 加顶点属性 | 在每个字符的顶点数据中加一个 channelIndex 字段 |
需要修改引擎的顶点格式和 Label 组件 |
| 传 Uniform | 每帧通过 uniform 变量告诉 shader 当前通道 | 同一批次的字符必须属于同一通道,否则打断合批 |
| 改 .fnt 格式 | 在字体文件中新增 channel 字段 | 需要修改引擎的 .fnt 解析器 |
这些方法都能工作,但都有一个共同的问题:需要修改引擎代码。 对于一个编辑器插件来说,这意味着用户需要修改引擎源码才能使用——门槛太高,也不利于维护。
有没有一种方式,不改引擎、不改数据格式、不加额外传参,就能让 shader 自行推算出该读哪个通道?
方案:用坐标编码通道
核心思路
.fnt(BMFont 字体描述文件)中,每个字符有一个位置坐标 (x, y) 和纹理尺寸 (scaleW, scaleH)。引擎计算纹理坐标(UV)的方式是简单的除法:
UV.x = char.x / scaleW
UV.y = char.y / scaleH
正常情况下,所有字符都在纹理范围内,所以 char.x < scaleW,UV 在 [0, 1) 之间。
关键洞察:如果我们在生成 .fnt 时,故意让某些字符的坐标超出纹理尺寸,UV 就会超过 1.0。
超出多少、往哪个方向超出——这本身就是信息。我们可以利用这一点,把"应该读哪个通道"这个信息藏在坐标里。
编码:生成阶段
生成时,将字符分成最多 4 组,分别写入 RGBA 四个通道。每组字符的坐标加上不同的偏移:
// 四组字符的坐标偏移
const offsets = [
{ x: 0, y: 0 }, // 第 1 组 → R 通道, 不偏移
{ x: texWidth, y: 0 }, // 第 2 组 → G 通道, x 方向偏移一个纹理宽度
{ x: 0, y: texHeight }, // 第 3 组 → B 通道, y 方向偏移一个纹理高度
{ x: texWidth, y: texHeight }, // 第 4 组 → A 通道, x 和 y 都偏移
];
// 写入 .fnt 时:实际位置 + 通道偏移
charData.x = rect.x + offsets[channelIndex].x;
charData.y = rect.y + offsets[channelIndex].y;
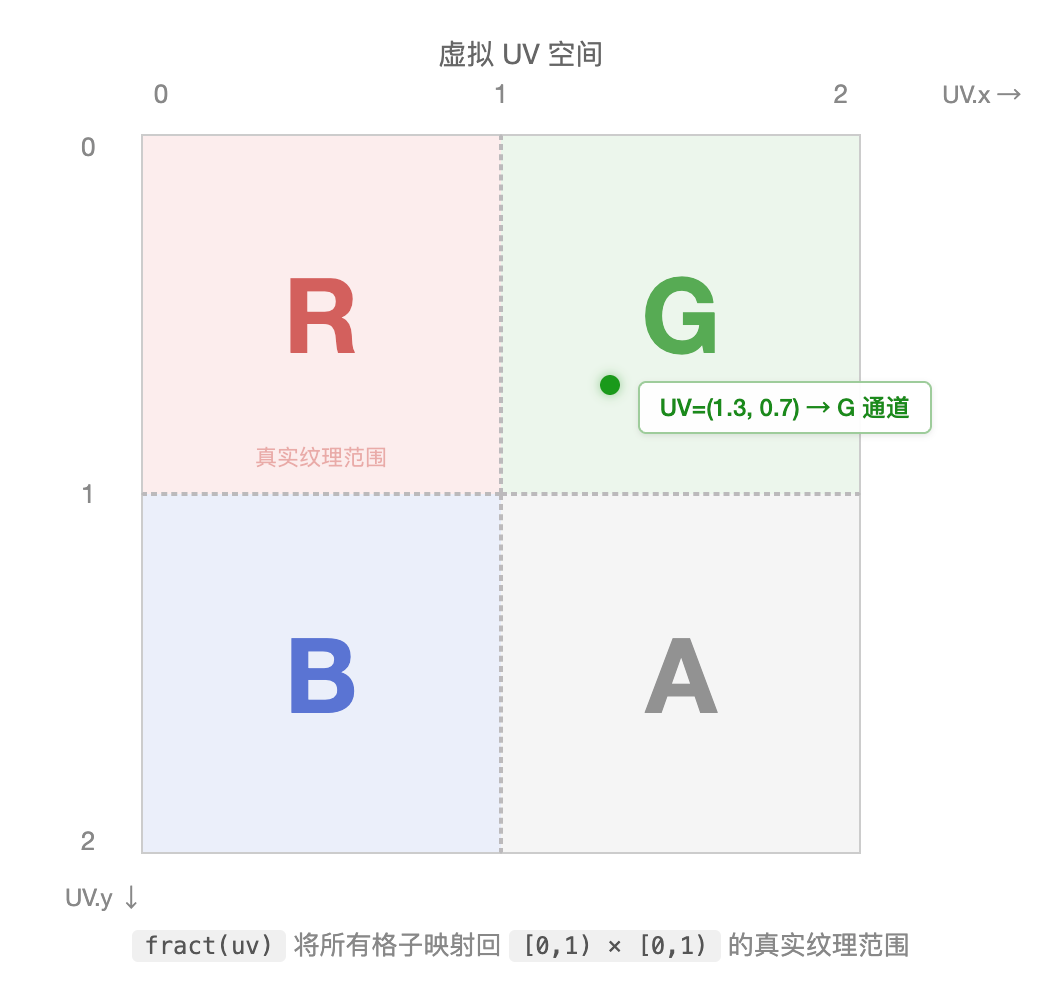
引擎拿到这些坐标后,照常做除法计算 UV。由于坐标可能超过纹理尺寸,UV 的范围从 [0, 1) 扩展到了 [0, 2)。
整个 UV 空间被分成了四个象限,每个象限对应一个通道:
| UV.x ∈ [0, 1) | UV.x ∈ [1, 2) | |
|---|---|---|
| UV.y ∈ [0, 1) | R 通道 | G 通道 |
| UV.y ∈ [1, 2) | B 通道 | A 通道 |
UV 落在哪个象限,就说明这个字符的 SDF 数据存在哪个通道里。
.fnt 格式本身没有任何改变——它只是存了一些"看起来比较大"的坐标值。引擎也不需要知道这些坐标有什么特殊含义。
一个关键细节:边缘 padding。 解码算法依赖 step(1.0, uv) 判断象限,这个判断发生在顶点着色器中——也就是说,同一个字符的四个顶点必须落在同一个象限里。如果某个字符恰好骑在 UV=1.0 的边界上,四个顶点可能被分到不同象限,导致通道判断错误。
生成工具在矩形装箱时通过 border 参数确保了这一点——所有字符与纹理边缘之间保留了足够的间距,不会出现骑线的情况:
// 矩形装箱器配置: border 确保字符不贴着纹理边缘
const rectPacker = new MaxRectsPacker(texWidth, texHeight, texturePadding, {
border: 2 + texturePadding, // 字符到纹理边缘的最小距离
});
解码:渲染阶段
shader 拿到 UV 后,需要做两件事:
- 判断通道:UV 在哪个象限 → 应该读哪个通道
- 还原坐标:去掉偏移部分,得到真正的纹理采样坐标
这两件事分别由 step 和 fract 完成。
顶点着色器(每个字符执行一次):
// 生成时, 四组字符被放到了不同位置:
// R 通道: 坐标不偏移 → UV.x < 1, UV.y < 1
// G 通道: x 偏移了一个纹理宽 → UV.x ≥ 1, UV.y < 1
// B 通道: y 偏移了一个纹理高 → UV.x < 1, UV.y ≥ 1
// A 通道: x 和 y 都偏移了 → UV.x ≥ 1, UV.y ≥ 1
//
// 所以只需要回答两个问题:
// 1. UV.x 是否 ≥ 1? (x 方向有没有偏移过)
// 2. UV.y 是否 ≥ 1? (y 方向有没有偏移过)
// 两个问题的答案组合起来, 就能确定是哪个通道。
// step 回答这两个问题: ≥ 1 返回 1, < 1 返回 0
vec2 hv = step(vec2(1.0), a_texCoord);
// 取反: "没有偏移" = 1, "偏移了" = 0
vec2 lv = 1.0 - hv;
// 现在把两个问题的答案组合成四选一:
// 乘法 = "且": 两个条件都满足时结果才为 1
channelMask = vec4(lv.x * lv.y, // x 没偏移 且 y 没偏移 → R
hv.x * lv.y, // x 偏移了 且 y 没偏移 → G
lv.x * hv.y, // x 没偏移 且 y 偏移了 → B
hv.x * hv.y); // x 偏移了 且 y 偏移了 → A
// 去掉偏移, 还原到 [0,1) 的真实采样坐标
uv = fract(a_texCoord);
片元着色器(每个像素执行一次):
// 用还原后的 UV 采样纹理,得到 RGBA 四个通道的值
vec4 texColor = texture(sdfTexture, uv);
// dot(点积): 把四个通道的值与 mask 逐个相乘再相加
// 由于 mask 只有一个分量为 1, 点积的结果就是那个通道的值
float sdf = dot(texColor, channelMask);
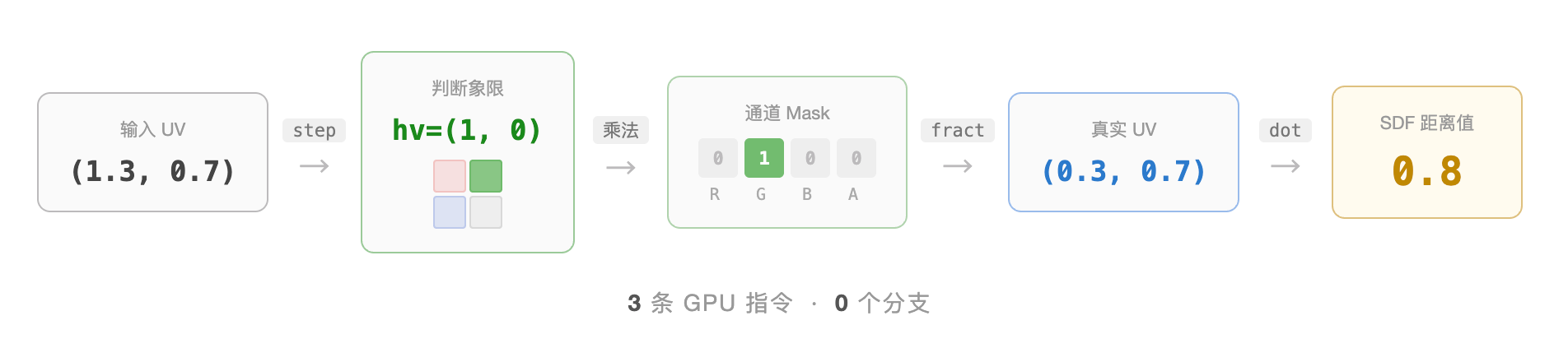
举个具体的例子。 假设某个字符的 UV 是 (1.3, 0.7):
第一步:step 判断象限
hv = step(1.0, (1.3, 0.7)) = (1, 0)— x ≥ 1,y < 1,落在右上象限
lv = 1.0 - hv = (0, 1)
第二步:计算通道 mask
channelMask = (0×1, 1×1, 0×0, 1×0) = (0, 1, 0, 0)— 选中 G 通道
第三步:fract 还原真实 UV
fract(1.3, 0.7) = (0.3, 0.7)— 去掉整数部分,得到真实采样坐标
第四步:采样并提取
texture(tex, (0.3, 0.7))返回 RGBA =(0.2, 0.8, 0.1, 0.9)
dot((0.2, 0.8, 0.1, 0.9), (0, 1, 0, 0)) = 0×0.2 + 1×0.8 + 0×0.1 + 0×0.9 =0.8成功拿到 G 通道的 SDF 距离值。
整个解码过程只有三条 GPU 指令(step、fract、dot),没有 if/else 分支,对性能零影响。
兼容性:不用合并时也能正常工作
当纹理没有使用通道合并时,所有字符的 UV 自然落在 [0, 1) 范围内:
hv = step(1.0, uv) = (0, 0)— x 和 y 都小于 1
channelMask = (1×1, 0×1, 1×0, 0×0) = (1, 0, 0, 0)— 恒选 R 通道
fract(uv) = uv— UV 不变
无论是否使用通道合并,同一个 shader 都能正确工作,不需要条件编译,不需要维护多个版本。
为什么这个方案能在 Cocos Creator 中直接工作
这个方案有一个隐含的前提:从 .fnt 文件到顶点着色器,UV 不能在任何环节被截断(clamp)到 [0, 1] 范围。如果引擎在中间某一步把大于 1.0 的 UV 值"修正"回 1.0,通道信息就会丢失。
通过阅读 Cocos Creator 3.x 引擎源码,可以验证这个前提成立。UV 从 .fnt 文件到 GPU 的完整路径如下:
第一步:.fnt 解析 → 像素坐标原样存储
引擎加载 BitmapFont 资源时,将 .fnt 中的字符位置直接存储为像素坐标:
// cocos/2d/assets/bitmap-font.ts
const rect = info.rect;
letter.u = rect.x; // 直接存储 .fnt 中的像素坐标
letter.v = rect.y; // 没有除法, 没有 clamp, 原样保存
letter.w = rect.width;
letter.h = rect.height;
如果 .fnt 里写的是 x=1300,letter.u 就是 1300——哪怕纹理只有 1024 宽。
第二步:像素坐标 → UV,纯除法无截断
排版完成后,像素坐标被转换为 UV。这一步是关键:
// cocos/2d/assembler/label/bmfontUtils.ts
const texW = spriteFrame.width; // 纹理实际宽度, 例如 1024
const texH = spriteFrame.height;
l = (rect.x) / texW; // 1300 / 1024 = 1.27 ← 大于 1.0!
r = (rect.x + rectWidth) / texW; // 纯数学运算, 没有 clamp
b = (rect.y + rectHeight) / texH;
t = (rect.y) / texH;
dataList[dataOffset].u = l; // 1.27 直接赋值, 不做任何修正
dataList[dataOffset].v = b;
引擎不关心 UV 是否大于 1.0——它只做了一次除法,然后把结果原样传递下去。
第三步:UV → 顶点缓冲区,直写 GPU
最后,UV 被写入 GPU 可以直接读取的顶点缓冲区:
// cocos/2d/assembler/label/bmfontUtils.ts
updateUVs (label: Label): void {
const vData = renderData.chunk.vb; // 顶点缓冲区
for (let i = 0; i < vertexCount; i++) {
const vert = dataList[i];
vData[vertexOffset] = vert.u; // float 直接写入
vData[vertexOffset + 1] = vert.v; // shader 中的 a_texCoord 就是这个值
vertexOffset += stride;
}
}
完整路径总结
| 阶段 | 数据 | 操作 | 结果 |
|---|---|---|---|
| .fnt 文件 | char.x = 1300 |
— | 1300 |
| 引擎解析 | letter.u |
原样存储 | 1300 |
| UV 计算 | 1300 / 1024 |
纯除法,无 clamp | 1.27 |
| 顶点缓冲区 | vData[i] |
原样写入 | 1.27 |
| 顶点着色器 | a_texCoord.x |
原样接收 | 1.27 |
从文件到 GPU,全程没有任何一行代码会截断 UV。 这条数据通路是"透明"的——引擎只做了数学运算,没有引入任何语义假设。这是方案能零侵入工作的根本原因。
完整数据流总览
从生成到渲染的完整链路:
生成阶段
- 输入 TTF 字体文件和字符集
- 对每个字符生成 SDF 灰度图
- 矩形装箱,将字符排列到纹理上(最多产生 4 个 bin)
- 每个 bin 的数据写入纹理的一个通道,坐标加上对应偏移:
| Bin | 写入通道 | x 偏移 | y 偏移 |
|---|---|---|---|
| 0 | R | 0 | 0 |
| 1 | G | +texWidth | 0 |
| 2 | B | 0 | +texHeight |
| 3 | A | +texWidth | +texHeight |
- 输出一张 RGBA 纹理(.png)和一个字体描述文件(.fnt)
.fnt 中部分字符的坐标 > 纹理尺寸——这是有意为之。
引擎阶段(Cocos Creator,无需修改)
- 解析 .fnt,将字符坐标原样存储为像素值
- 排版时,UV = 像素坐标 / 纹理尺寸(纯除法,无截断)
- UV 写入顶点缓冲区,范围 [0, 2)
引擎不知道 UV > 1.0 有什么特殊含义,它只是透明地传递了数据。
渲染阶段(自定义 Shader)
顶点着色器:
-
step→ 判断 UV 所在象限,生成通道选择 mask -
fract→ 去掉偏移,还原真实采样坐标
片元着色器:
-
texture→ 采样纹理,得到 RGBA 四通道值 -
dot→ 用 mask 提取目标通道的 SDF 距离值 - 用距离值渲染字符(阈值判断 / 平滑过渡 / 描边 / 阴影等)
效果
容量计算
单通道的理论容量可以用一个简单的公式估算:
每字符像素边长 ≈ fontSize + distanceRange
单通道容量 ≈ (texWidth × texHeight) / (每字符像素边长)²
四通道容量 ≈ 单通道容量 × 4
以一张 2048×2048 的纹理为例:
| 字号 | 距离场范围 | 每字符约占 | 单通道容量 | 四通道容量 |
|---|---|---|---|---|
| 32 | 4 | 36×36 px | ~3,200 | ~12,800 |
| 40 | 8 | 48×48 px | ~1,820 | ~7,280 |
| 48 | 8 | 56×56 px | ~1,338 | ~5,352 |
以上为理论值。实际受矩形装箱效率影响,通常能达到理论值的 65%~85%。例如某个实际项目中,字号 40 + 距离场范围 8,一张 2048×2048 纹理通过四通道合并装入了 5,933 个中文字符。
收益
在移动端,少一张纹理意味着少一次纹理切换、少一个 draw call、少一份显存占用。对于需要大量 CJK 字符的游戏,这是实实在在的优化。
注意: 此方案仅适用于单通道的 SDF 模式。MSDF(Multi-channel SDF)本身就使用 RGB 三个通道存储不同方向的距离信息,通道已经各有用途,无法再用来打包不同字符。
特别注意 此方案由笔者设计,但文章由 AI 书写,如有错漏敬请谅解。
字体生成插件是在链接文章中插件基础上修改的,感兴趣的可以让 AI 帮忙修改下,这里就不提供了
 感谢分享
感谢分享