
你没理解什么是gpu动画
补了一下知识点,似乎有些理解了
为什么是 VAT
看完上面的数据,回到问题本身:装饰物、背景动效、循环特效这类被动播放、不参与交互的 spine,大部分根本不需要 sp.Skeleton 的运行时灵活性——没有 IK、没有动态挂点、没有换 skin。它们就是"一段已经确定的顶点位置和颜色序列"。
这正是 VAT(Vertex Animation Texture)的用武之地:离线把每帧每个顶点的状态写进 PNG,运行时 shader 通过 frame 和 vertexID 采样。CPU 完全不参与骨骼,整个动画播放挪到 GPU 一侧,sp.Skeleton 不再承担这类实例的主路径。
下面讲核心编码协议。
从 spine cache 模式说起
spine 官方 runtime 早就提供了 cache 模式——同一个动画第二次播放时不重新计算骨骼,直接读上一次的顶点缓存。
这个机制已经承认了一件事:对行为静态的 spine,骨骼计算的输出是一段确定的顶点序列,可以预先缓存。
但 cache 模式停在 CPU 内存。每帧仍要:取顶点 → 复制到 GPU buffer → shader 才能渲染。CPU 不算骨骼了,但"取 + 传"的开销还在主线程。
这不是 spine runtime 做得不够激进,而是它的设计目标不同。sp.Skeleton 的核心价值,是保留每一帧仍可被运行时接管的能力:可以换 skin,可以改 attachment,可以接 IK,可以响应逻辑状态,也可以在动画播放过程中继续做局部控制。这些能力本身就是它的产品边界,性能成本则是这条边界的价格。
所以 cache 模式本质上已经是"运行时灵活性 vs 性能"之间很深的折中:它缓存已经算过的结果,但仍保留结果随时可能失效、重建、被运行时修改的前提。只要这个前提不变,缓存就很难彻底离开 CPU,也很难把实例变成纯粹的 GPU 数据。
VAT 不是在同一个目标下继续优化 spine runtime。它换了一个目标:承认一部分 spine 不需要运行时控制,把它们从"可被逻辑随时操纵的骨骼对象"改造成"已经确定的动画资源"。它放弃的是运行时灵活性,换来的是 GPU 侧吞吐和多实例共享。
这个取舍是否成立,关键看场景。对于主角、交互物、状态复杂的角色,运行时控制价值很高,VAT 不划算;但对于大量背景装饰、循环氛围物、静态展示对象,每个实例除了位置、缩放、播放进度之外几乎没有独立行为,运行时控制的价值趋近于零。这时继续为"可能会变"付费,就是浪费。
VAT 把缓存推到 GPU 纹理
VAT 是 cache 模式的下一步——把顶点缓存从 CPU 内存搬到 GPU 纹理。
一旦缓存进了纹理,shader 自己就能采样。CPU 完全不接触骨骼数据,只负责:
-
当前帧索引(一个数字)
-
节点 transform(2D 矩阵)
多个相同 spine 同时播时纹理共享,N 个实例不再各自携带一份骨骼计算状态。它们共享同一份动画数据,只保留自己的 transform 和时间进度。换句话说,VAT 让这类 spine 实例接近"无状态资源":数据在纹理里,状态在很小的实例参数里,CPU 不再维护一套完整的骨骼对象生命周期。
这是一种很典型的 GPU 时代架构模式:数据共享 + 状态独立。共享的是大块、只读、可复用的数据;独立的是每个实例少量、低成本的状态。粒子系统也是这样,许多粒子共享材质和发射规则,各自只带位置、速度、生命期;GPU Instancing 也是这样,许多对象共享 mesh 和 material,各自只带变换与少量参数。
VAT 只是把这个范式应用到了 spine 顶点动画上。原来每个 spine 都像一个需要运行时照看的对象;烘焙之后,它更像一份可被很多实例读取的数据资产。GPU 适合这件事,是因为 vertex shader 天然按顶点并行,texture fetch 足够便宜,同时还能省掉 CPU/GPU 每帧传顶点数据的同步和带宽开销。
顶点动画本质上就是 2D 数据
为什么"顶点缓存"能塞进纹理?
因为顶点动画的输出本质上是一个二维数据表:行 = 帧,列 = 顶点,每个单元格 = 一个顶点的状态。这正是一张纹理的形态。GPU 拿 (frame, vertexID) 两个索引就能采到对应像素。
这背后更大的思想是:时变数据可以用纹理表达。纹理不一定只表示颜色,也可以表示高度、速度、法线、位移、权重、状态。只要数据能被规整成二维索引,GPU 就可以把它当 lookup table 读出来。对顶点动画来说,"时间"和"顶点编号"天然就是两个索引轴。
这不是某个项目里的奇技淫巧,而是被反复验证过的工程哲学。Houdini VAT 是 SideFX 官方提供的工作流,用纹理把复杂模拟结果带到实时引擎;Unity 生态里也有成熟的 Vertex Animation Texture 流程,用来把网格动画烘焙成材质可读取的数据;UE 侧常见的顶点烘焙管线,同样是在把离线动画结果变成运行时友好的 GPU 数据。
这些方案的共同点不是"用了一张特殊贴图",而是把 CPU 难以高并发维护的逐实例动态过程,提前转换成 GPU 容易并行读取的稳定数据。spine VAT 只是这个思想在 2D 骨骼动画上的一次落地。
落到工程上,VAT 把整段动画需要的所有数据——每一帧、每一个顶点的位置和颜色——全部打包进一张 PNG 图片里。一张图就承载了完整的顶点动画。
这张图长得不像艺术贴图:如果直接用图片查看器打开,会看到一些彩色的"噪点"或者奇怪的色块,因为里面存的根本不是给人眼看的画面,而是按规则编码的顶点数据。文件具体叫什么名字不重要,下文统一称作「数据图」。
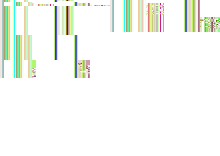
一张真实的"数据图"——你看到的彩色噪点不是图坏了,每个像素都在编码某一帧、某个顶点的位置或颜色。
数据图内部怎么分段
看上去是噪点,其实数据图内部有一套清晰的分区规则:
| 维度 | 分法 |
|—|---|
| 上下分两半 | 上半 = 位置图层,下半 = 颜色图层,两种数据各占一区 |
| 每一行一帧 | 从上往下数,每一行存的是动画第 0、1、2… 帧的全部顶点状态 |
| 每一列一个顶点 | 横向数,每一列对应一个固定的顶点 ID。shader 拿到顶点 ID 就知道去哪一列采样 |
| A 通道当开关 | 颜色图层里 RGB 存色彩,A 通道专门标记"这个顶点这帧是否可见"。attachment 切换瞬间 A 跳变 0/1,shader 立刻知道这一帧不能插值 |
到这里思路就完整了:一张图、按"帧 × 顶点"两个轴排列、上位置下颜色、A 通道当开关。剩下的就是这套分段思想落地时绕不开的几个工程决策。
几个绕不开的工程取舍
分段思想本身很干净,但落到 PNG 这个具体介质上,还有几个绕不开的取舍:
-
精度:单通道 8-bit 装不下顶点坐标,必须用 RGBA 多通道凑精度——本质是承认"图里存的是数据,不是颜色"
-
采样:烘焙 30Hz、渲染 60Hz,中间帧靠双帧插值补;但插值前必须看 A 通道,否则会把"剑出现/消失"插出中间态
-
导入:数据图必须按数据处理(禁压缩、禁过滤、禁 mip),不能让 ASTC 压缩或者 GPU 默认的双线性过滤把像素值"美化"掉。和主图集的导入策略要分开管
这些都不是协议本身的核心,是介质决定的工程决策。
边界
不适合 VAT 的场景:IK、动态挂点、运行时换 skin、强依赖 DrawOrderTimeline、超大顶点数或超长动画。只要动画结果依赖运行时决策,离线烘焙就不再是天然正确的表达方式。
被动播放的装饰类 spine 适合 VAT;主角、强交互物继续走 sp.Skeleton。混合方案,不要试图统一。
收益清晰:CPU 骨骼开销大幅下降,GPU 持平或微增。代价是多一份烘焙产物、多一套 shader、多一些资源流程约束。值不值得做,取决于项目对 CPU 预算有多敏感——做 H5 小游戏或低端机覆盖率高的项目,这套方案能解决不少问题。
这条路还能走多远
文章讲的是「顶点烘焙」——直接把每帧每个顶点的最终状态烤成数据。
但 spine 动画里,最终的顶点位置其实是「骨骼变换 × 静态网格 × 蒙皮权重」一路推导出来的。如果不烤最终顶点,改去烤每帧每根骨骼的变换矩阵呢?
骨骼数远少于顶点数,数据图能小一截,但 shader 要多做一步蒙皮计算——本质是拿数据量去换 shader 复杂度。这是不是更划算?什么场景下值得?——是另一个故事。
2赞
论坛讨论就人味多一点 讲核心就行了 你贴ai我会认为你没有真实懂
文字功底太差了哈 如果你觉得我没懂 没关系 我东西是做出来的
嗯 。没啥。 显存变化不大就是你那张图太小 动画烘焙出的数据不大,所以看起来变化不大。整体没啥问题。值得一试的修改。
准备尝试下。对那种战场很多战斗非主要单位的动画收益会非常大
提升巨大,其实还可以合批所有的都放在一个vat上面,再配合上spine 多纹理合图 那就1个drawcall搞定
3D动画预烘焙/GPU动画性能提升更大,效果更明显;特别是顶点很多/绘制海量模型的时候