
【本文参与征文活动】
异名最近负责了一个微信小游戏的项目,在版本迭代间隙对游戏的性能调优进行了一次尝试。
参数指标
引擎和小游戏都有一个性能面板,给开发者们暴露了下面几个性能指标:
-
Frame time(ms)
每一帧的时间。《RAIL模型》建议在10毫秒或更短的时间内制作动画中的每一帧。从技术上讲,每帧的最大预算为16毫秒(1000毫秒/每秒60帧≈16毫秒),但是浏览器需要大约6毫秒才能渲染每帧,因此建议每帧10毫秒或者更短。 -
Framerate(FPS)
帧率,也叫每秒传输帧数(FPS:Frames Per Second),是指画面每秒传输帧数,通俗来讲就是指动画或视频的画面数;每秒钟帧数越多,所显示的动作就会越流畅,举个例子电影的帧频是24,也就是说1s需要播放24张图片,但是实际上在游戏过程中一般人能接受的最低FPS约为30Hz。帧率也非越高越好,因为显卡处理能力=分辨率×刷新率,分辨率不变的情况下,帧频越高,GPU处理的数据量也会激增,引起卡顿。同理,分辨率也不是约高越好。在某些终端的性能面板下也会展示这三个相关的参数: rt-fps(runtime fps):实时帧率;ex-fps:极限帧率;min-fps:最小帧率; -
Draw call
CPU和GPU是并行工作的,它们之间存在一个命令缓冲区。当CPU需要调用图形编程接口的时候就会往命令缓冲区里面增加命令,当GPU完成上一次渲染命令的时候就会继续从命令缓冲区中执行下一条命令,命令缓冲区里面的命令有很多中,而drawcall就是其中的一种。CPU在提交drawcall的时候需要处理很多东西,比如一些数据、状态、命令等等,有些渲染卡顿问题就是因为GPU渲染速度比drawcall的提交速度快,可能上一次渲染完了,CPU还在计算drawcall,所以drawcall的性能瓶颈在于CPU。优化drawcall最有效的方法合批渲染,就是把大量小的drawcall合并成大的drawcall,减少drawcall的数量。 -
Tris 和 Verts
Tris和Verts是渲染的三角面数以及顶点数,在webgl中只有三种基本图元,分别是点、线段和三角形,无论多么复杂的模型本质上都是由这三个基本图元绘制而来的,无论形状多么怪异,它们的本质都是由一个个顶点组成,GPU 将这些点用三角图元绘制成一个个的微小平面,再把这些三角行互相连接,就能绘制出各种复杂的物体了;一般来说模型的顶点和三角形数越低,模型的复杂度就会越低,所以这两个参数在3D模型中比较有参考意义,设计师在输出3D模型的时候一般都会帮忙去合并一下网格。但是在大部分情况下,我们都会认为性能瓶颈在
drawcall上,比如有两种情形,情形一是有1000个物体,每个物体的顶点数是10,情景二是有10个物体,每个物体的顶点数是1000,哪个情景的性能更好?首先我们要明白GPU的渲染速度是非常快的,渲染10个顶点组成的三角图元和1000个顶点组成的三角图元通常没啥区别,所以这两种情形中产生drawcall更少的情形二性能更好。当然如果你在shader里面对顶点做了一些特殊的处理,比如复杂的计算啥的,那就得权衡一下这两个指标的大小影响了
实操
降低DrawCall
想要减少drawcall就要从影响渲染状态的因素入手,比如纹理图片、纹理的渲染模式、Blend方式等等。但是在大部分项目中其实我们也不会有多大的需求去单独修改引擎的默认渲染参数,如果你动手了,那肯定是会打断合批的
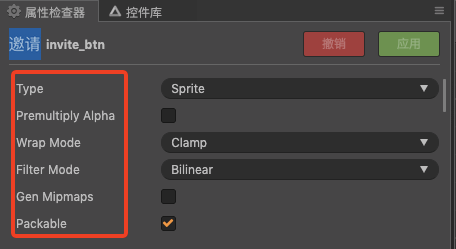
因此在绝大部分情况下,在项目中降低drawcall收益比最大的其实是就是利用引擎提供的静态合图和动态合图的功能。静态合图就是自动图集了,或者使用第三方的图集工具TexturePacker,把资源中的散图进行合并,尽量让画面中的节点都使用一张图集,因为同一张图集的纹理状态都是一致的,所以能够达到渲染批次合并对纹理状态的要求;引擎中的动态合图有两种,一种作用对象是图片资源,是引擎默认启用的,如果不希望使用就在资源面板中把Packable勾掉,或者把全局的合图开关关掉cc.dynamicAtlasManager.enabled = false; ;一种是针对label的,可以在label的cache模式中进行不同的模式切换。下面就介绍一下异名在这个项目中针对drawcall做的一些处理和收益:
合理管理节点
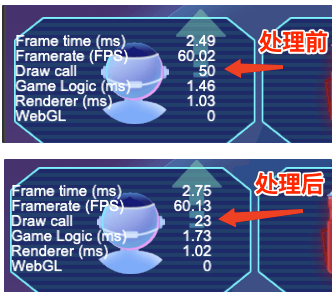
画面外的节点可以直接移除,drawcall从50降到了23:
合理设置label的cache模式
把首页上三个label的cache模式改为bitmap,首页上的drawcall从79降低到50

有一些频繁更改的label,当cache模式改为char的时候,在我的苹果手机上差别不大,但是在小伙伴的安卓手机上流畅度上升十分明显
合并图集
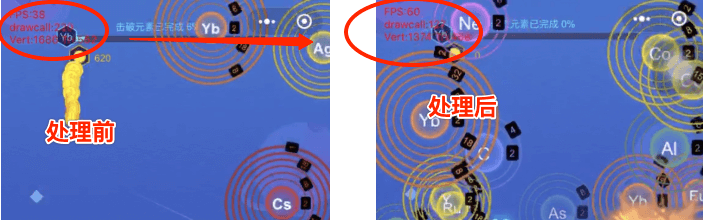
在合并图集的时候需要根据画面的内容去做划分,尽量把同一个画面用的的图片资源打包成一个图集。以游戏中的一个中后关卡为例(前面关卡的画面节点太少,差异不明显),drawcall均值从190降到了90,drawcall峰值从220降到了127。
通过Performance排查问题
在开发中的时候,异名会使用Chrome的DevTools,如果是在浏览器中排查性能问题需要屏蔽所有的浏览器插件,最好就是打开隐私模式来调试,因为插件在后台运行会造成干扰。但是在上线前异名会选择使用微信开发者工具的DevTools来再查看一下性能,因为在浏览器的中跑的项目是调试模式,一来没有做合图,而来它也没有经过小游戏的编译,所以为了减少和最终项目效果的偏差,最终会以微信开发者工具中的指标为最终的参考指标。
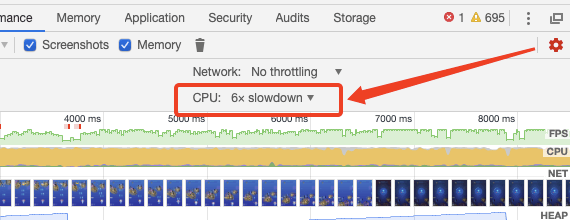
和手机终端环境相比,我们的电脑的CPU是很快的,为了尽可能模拟用户的终端硬件情况,我们首先需要对CPU做一下节流,例如我现在选中的6x slowdown就会使我们本地CPU的运算速率比正常情况下降6倍。
这时候我们重新去生成录制结果,就可以发现面板上已经出现了醒目的红色告警信息了:

Recurring handler
聚焦放大然后把轴线定位到每个小的告警信息处,可以在Summary中看到浏览器给出的警告信息,我发现这里面的告警信息都是一样的,都是Recurring handler,而且有规律地出现,可以通过Initiator去查看重复出现的地方以及具体的执行代码:
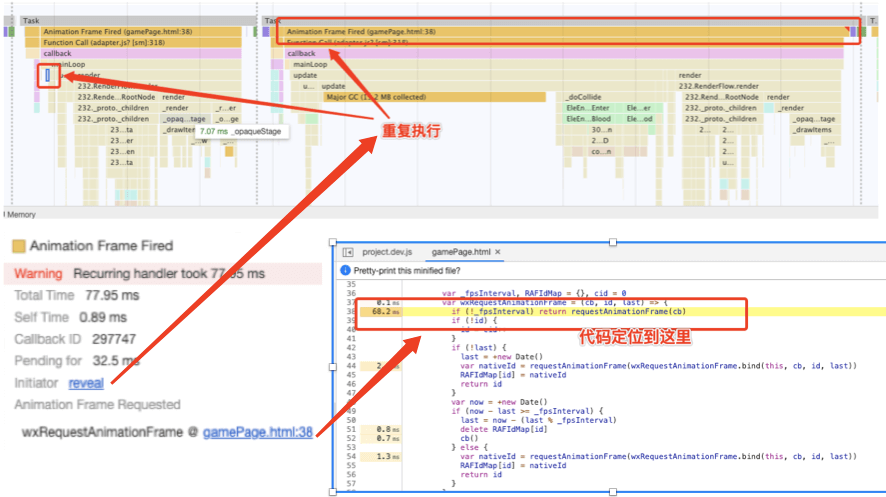
虽然我们已经看到了代码执行的具体位置是requestAnimateFrame,但是这个api调用不是我们的业务逻辑,而是引擎的封装调用,引擎的帧回调应该是用requestAnimateFrame实现的,也就是说在update的钩子里面可能存在重复调用的逻辑,在这里就需要进一步地去分析了。我们需要根据Main面板中火焰图也就是JS调用栈一步步去寻找并落实到具体的业务代码调用细节,如果能够定位到我们逻辑中的调用函数,马上对症下药就能解决了。但是在异名的这个项目中Recurring handler给到的信息很难定位,task下面调用栈调用的都是引擎自身的渲染方法,当然横向去看调用的先后顺序的话,它在touchMove事件后面运行,这是一个排查方向,需要去分析自己的代码运行调用。如果像异名遇到的这种情况,控制台只能定位到一堆引擎的渲染函数,而不能很明确地定位到我们的具体业务逻辑中,异名会建议放一放,因为重复渲染的问题可能会在long task拆分的过程中被fix掉。
Long task
可以通俗理解为一段执行时间很长的js逻辑就是长任务,"长任务"占用着主线程,即使我们的页面看上去准备好了,但是也不能响应用户的操作和点击等交互。至于这个执行时间多长才算是“长”呢?《RAIL模型》建议我们每个任务最好都控制在50毫秒内,Chrome在控制台中也给出了醒目的长任务提示:
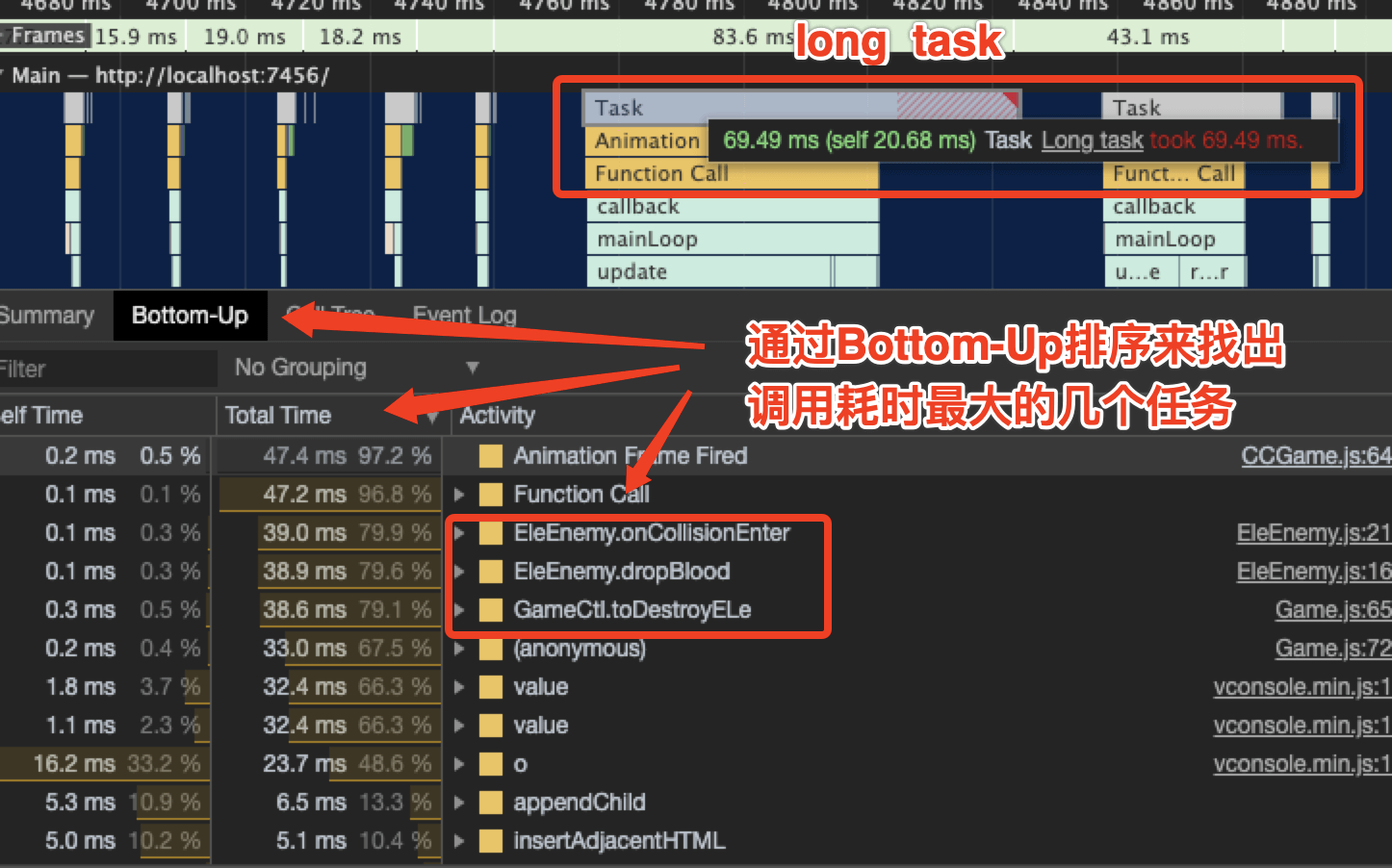
大型的脚本是长任务的主要原因,异名这里先举一个在项目中拆分长任务的简单的例子。异名的游戏中有个复活的逻辑,会在碰撞的回调中会处理一下血量和相关的掉血交互,然后当玩家血量耗尽就会唤起一个复活弹窗,这段逻辑就产生了一个long task,耗时55.74ms,火焰图如下:
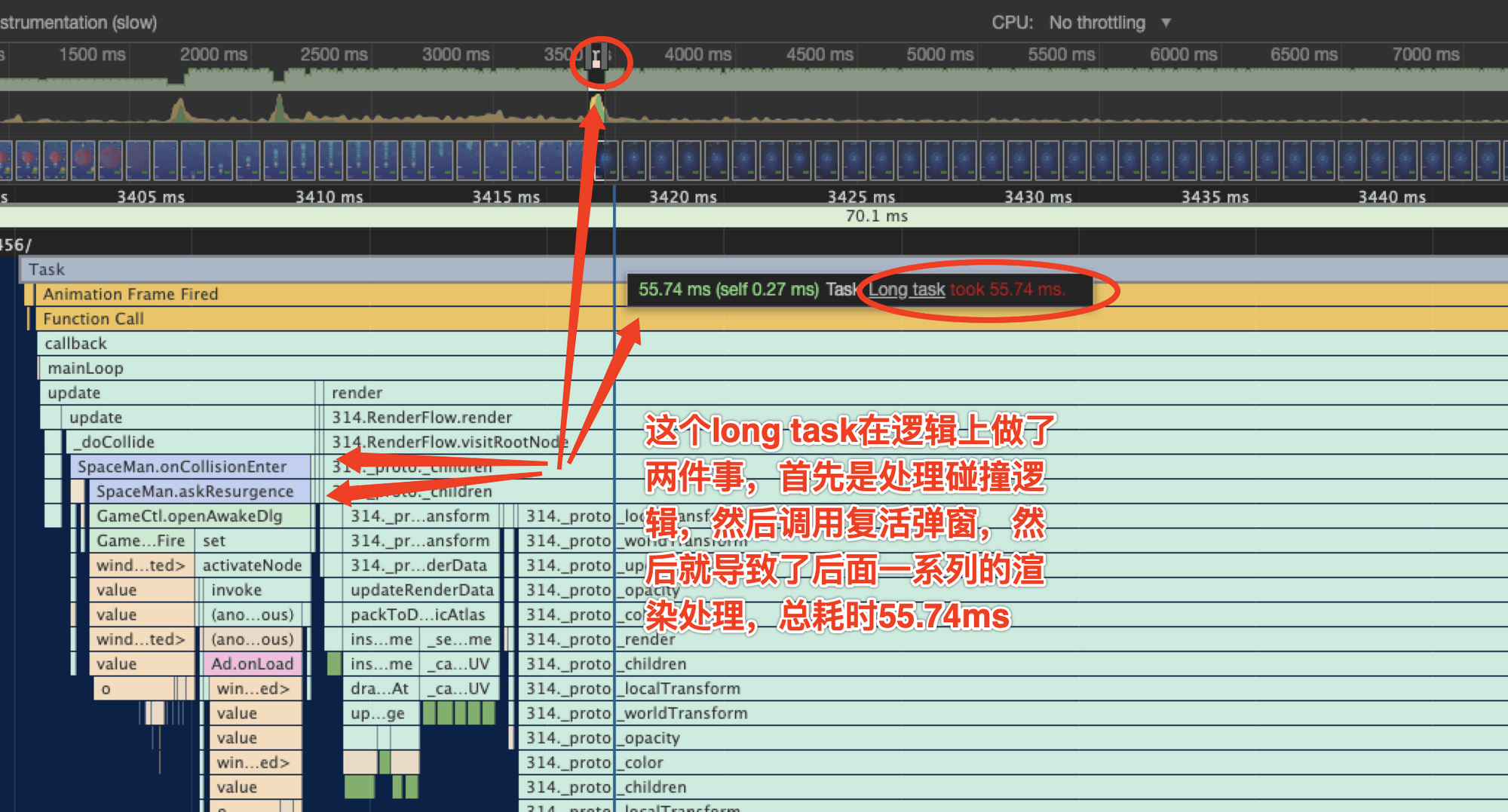
仔细分析一下,我的碰撞的逻辑处理和唤起复活弹窗虽然是顺序调用,但是它们之间算是一个比较清晰的逻辑界线,而且askResurgence这个函数是一个唤起UI弹窗的函数,既然产生了性能限制,我们就在这里做一个任务拆分:
// 用setTimeout包裹一下,把它放在下个宏任务执行
setTimeout(() => {
this.askResurgence();
})

这时候我们再看拆分后的火焰图,long task标记已经消失了,本来一个长任务,被拆分成了3个任务(中间一个是GC),而且三个任务的耗时相加和开始的长任务相比是折半了的。异名通过排查梳理之后,发现一些很明确的UI状态过渡都很容易造成长任务,异名的项目中还有好几处都是这种界线分明混合逻辑,当你遇到性能压力的时候或许可以像我一样做一下处理。
总结一下拆解大型脚本的时候首先需要把大段的js逻辑重新梳理一遍,可以把一些能提前或者延后的状态拆解到我们应用的空闲阶段去初始化或者变更,比如在首页就先把游戏过程中需要的数据加载进来,游戏过程的的逻辑中就不用再去加载这部分数据了,但是这属于比较“宏观的”逻辑变更,但是大部分情况下我们的状态和逻辑变更都是很难提前或者延后的。我们还可以做一些时间颗粒度更小的逻辑拆分,那就是结合js的事件循环机制来处理我们的逻辑,像用Promise.then或者setTimeout去做一下任务延迟,甚至可以建立一个任务队列去做事件缓存等,这篇《idle-until-urgent》有介绍到一些比较具体的拆解脚本措施。任务拆分是有风险的,无论是在应用的层面去提升或者延后逻辑,还是利用js的微任务或者宏任务去延后状态逻辑,都会有可能导致你的应用状态同步出现问题,所以在实操之后记得好好测试一下整个流程。
长任务还可以通过精简自身的逻辑来优化,像在一些循环中,如果可以做跳出判断自己是否有做;还有在一些地方你写的逻辑是否执行冗余或者无用,比如在异名的项目中这段交互逻辑
// 效果甚微的动画交互,干掉
this.node.setScale(1.2);
const frequency = getRandom(15, 40) / 100;
this.centerNode.runAction(
cc.sequence(
cc.scaleBy(frequency, 1.1),
cc.scaleTo(frequency, 1)
).repeatForever()
);
它只是一个呼吸变化,在实际的画面效果中,这种小变化其实是很微弱的,可以认为它是一个可有可无的动画逻辑,那我们在做性能优化的时候就需要果断地把它给删除了,把这些冗余的逻辑干掉之后,game logic的数值就已经可以很明确地降低下来了。
其他
目前还存在较明显的性能方面:发热、敌人数量增多时容易卡顿
发热是个比较综合的问题,一般来说CPU导致发热,降低CPU的工作会有效减少发热。卡顿则受到帧频和drawcall的影响比较大,通常有以下这些优化手段
- 降低帧数:目前已动态设置帧频,游戏过程60帧,非游戏过程30帧
- 减少帧回调:目前update中还有很大的逻辑优化空间
- 减少内存使用:这块目前也有很大的优化空间,GC回收,节点池,对象和节点复用、缓存等等,甚至包括一些贴图的引用释放等
- drawcall优化:其实还可以借助一些帧调试工具去进一步分析,项目的后期应该还会对
drawcall优化进行再深入一点的探索,到时候如果有别的收获就再和大家分享

 点赞! 跟着异名/皮皮学优化!
点赞! 跟着异名/皮皮学优化!