
最近看了很多关于ui Drawcall 合批的策略,但是发现大部分的策略都是需要改动引擎层面去实现。但是这是我所不想的。然后反复看了3.5.2ui层渲染合批的代码终于找到了一个比较好的合批策略,并且在虚拟列表上应用,效果如下
测试项目可以参看我的开源项目
https://github.com/xzben/creatorFrame
(为了让大家更清楚的对比两者的区别,特别重新录制了视频给大家对比性能)
demo为一个100个item的虚拟列表
优化后结果:
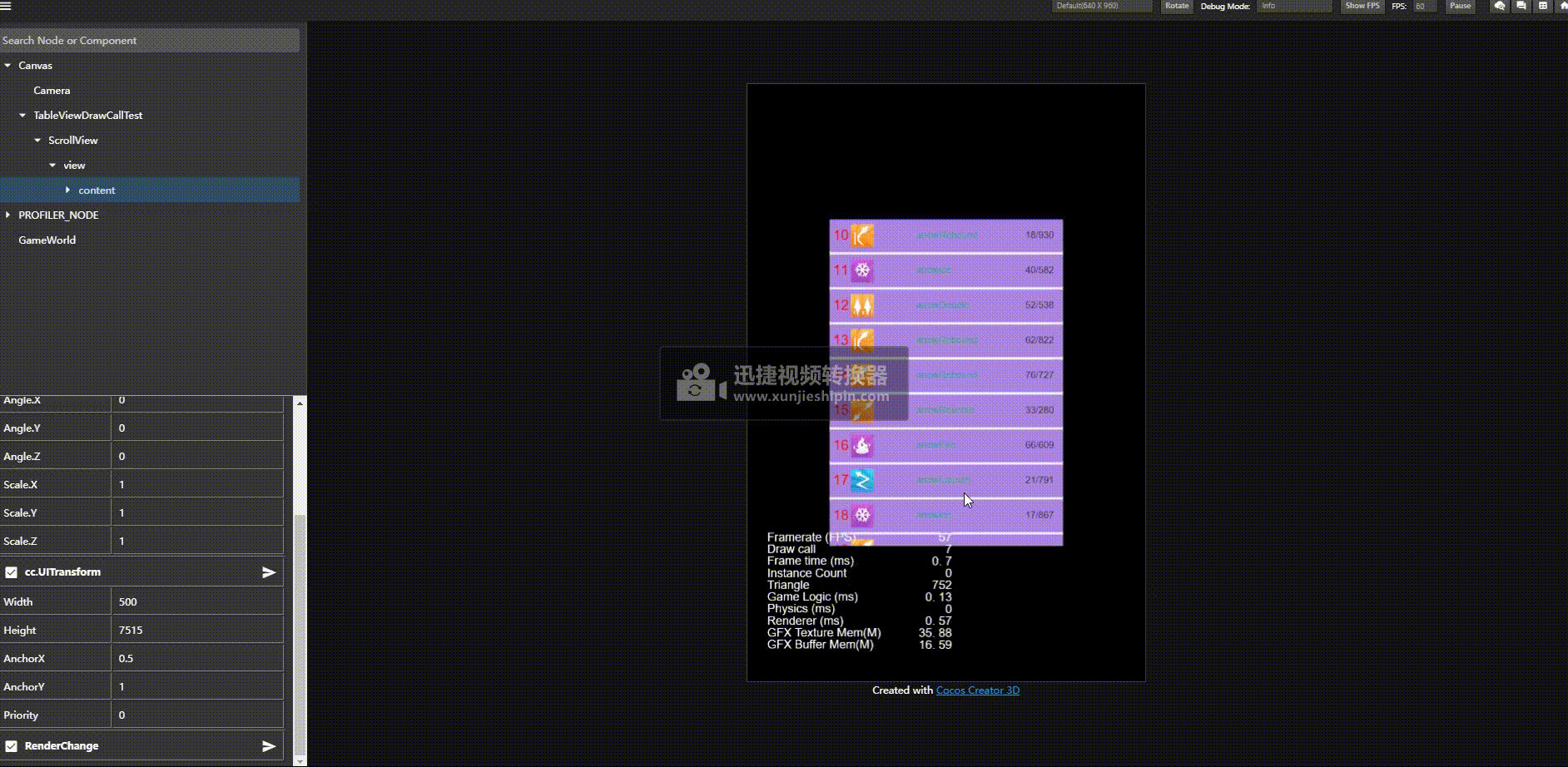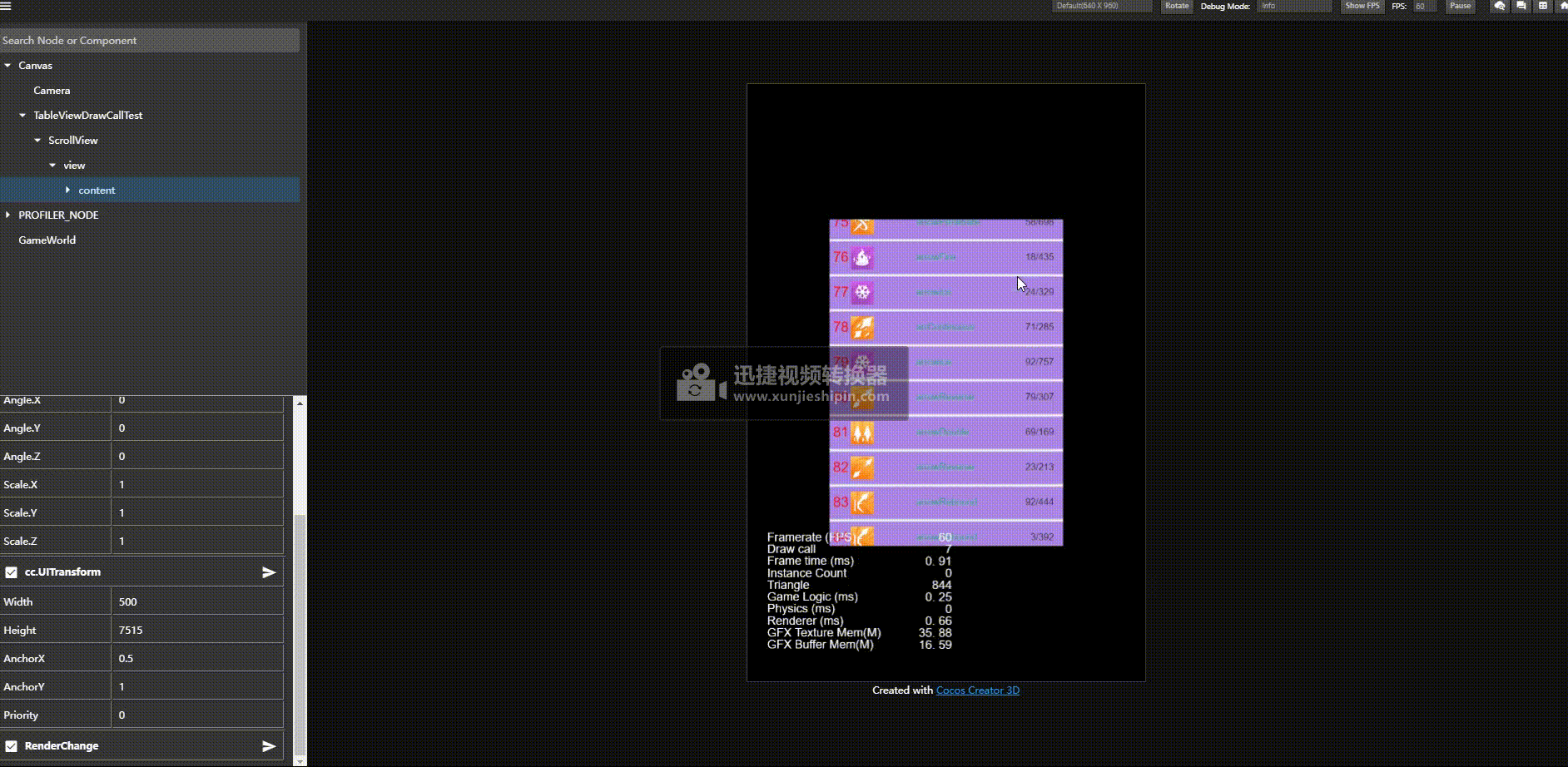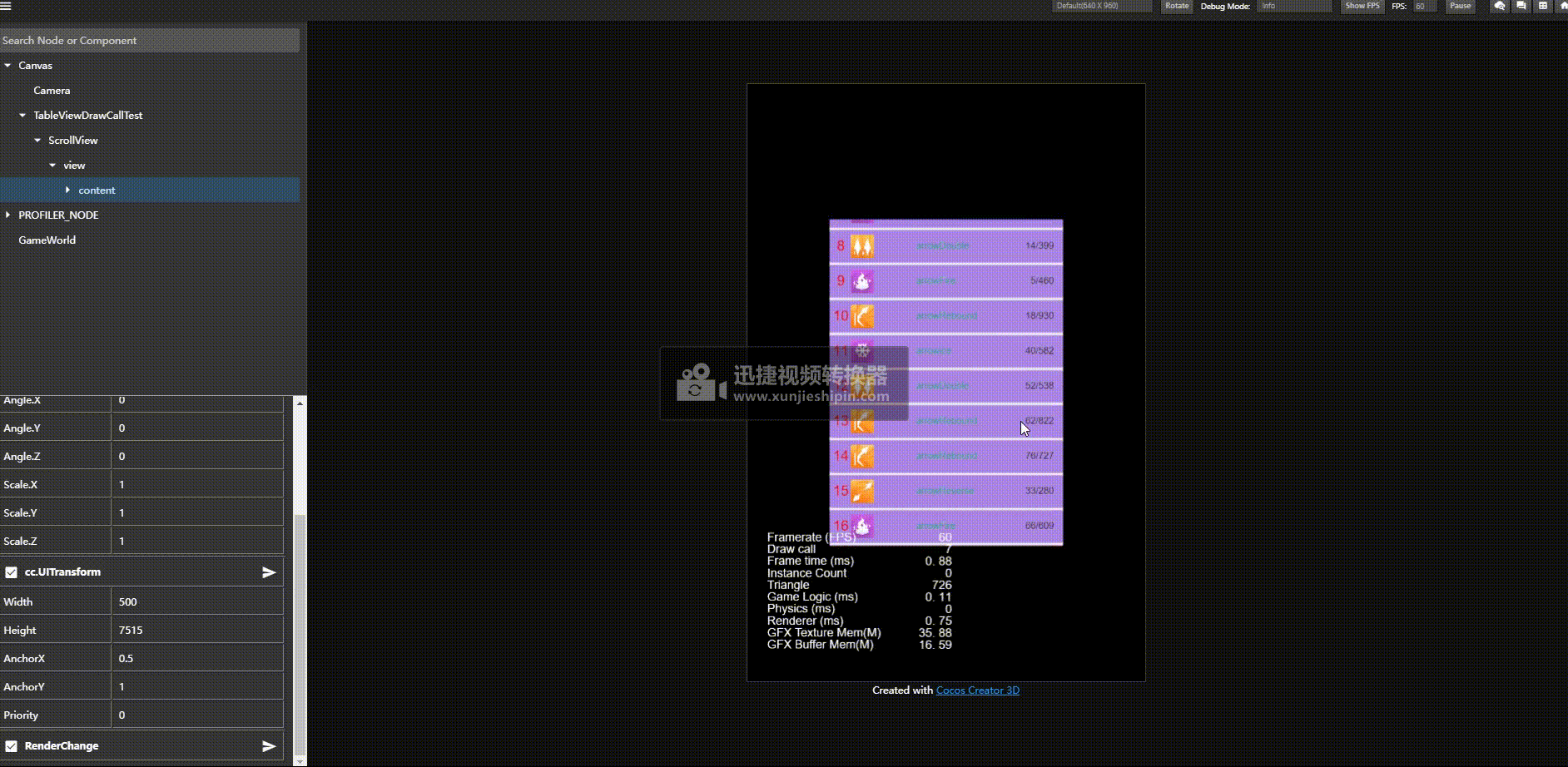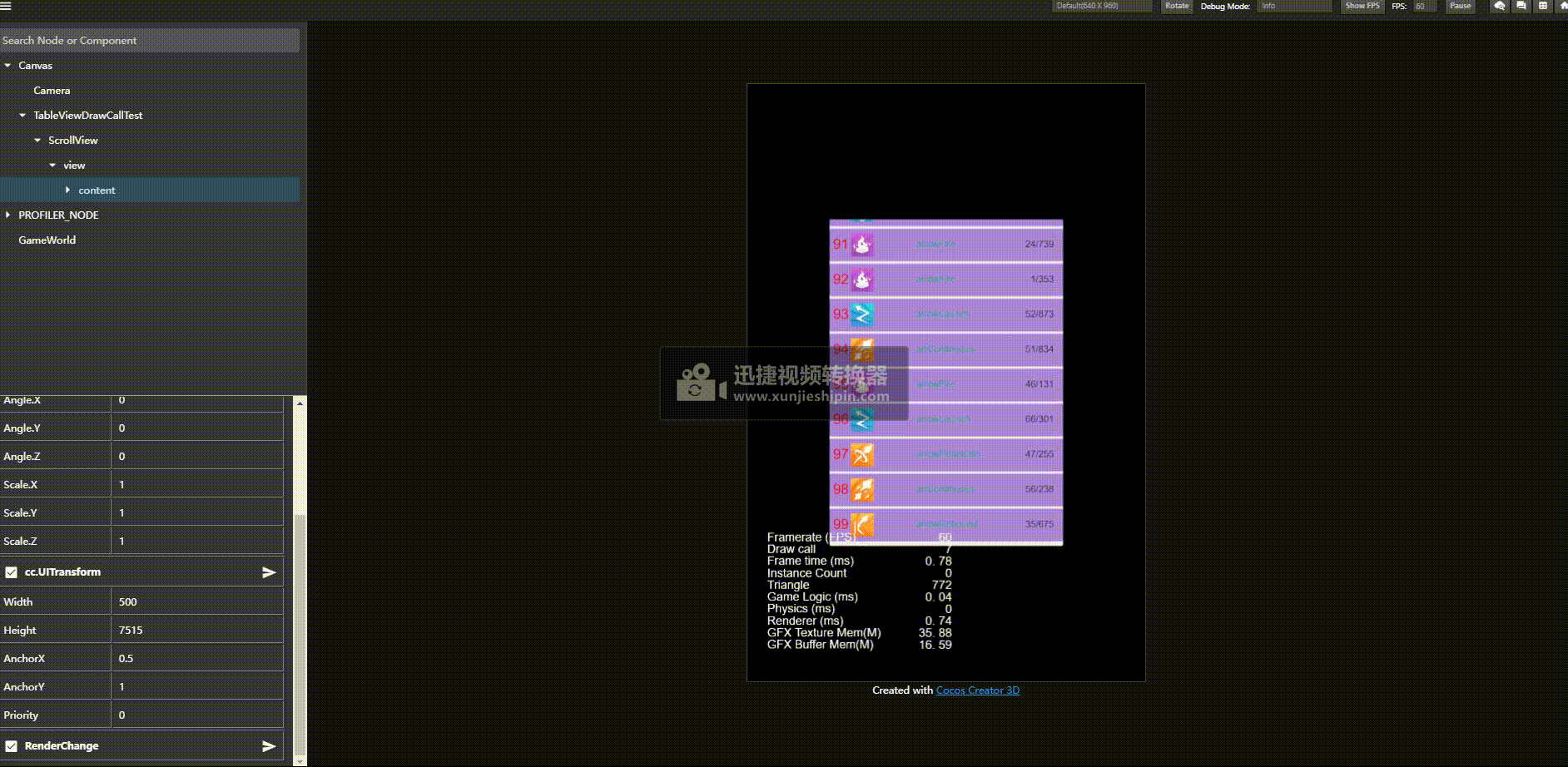
优化前:
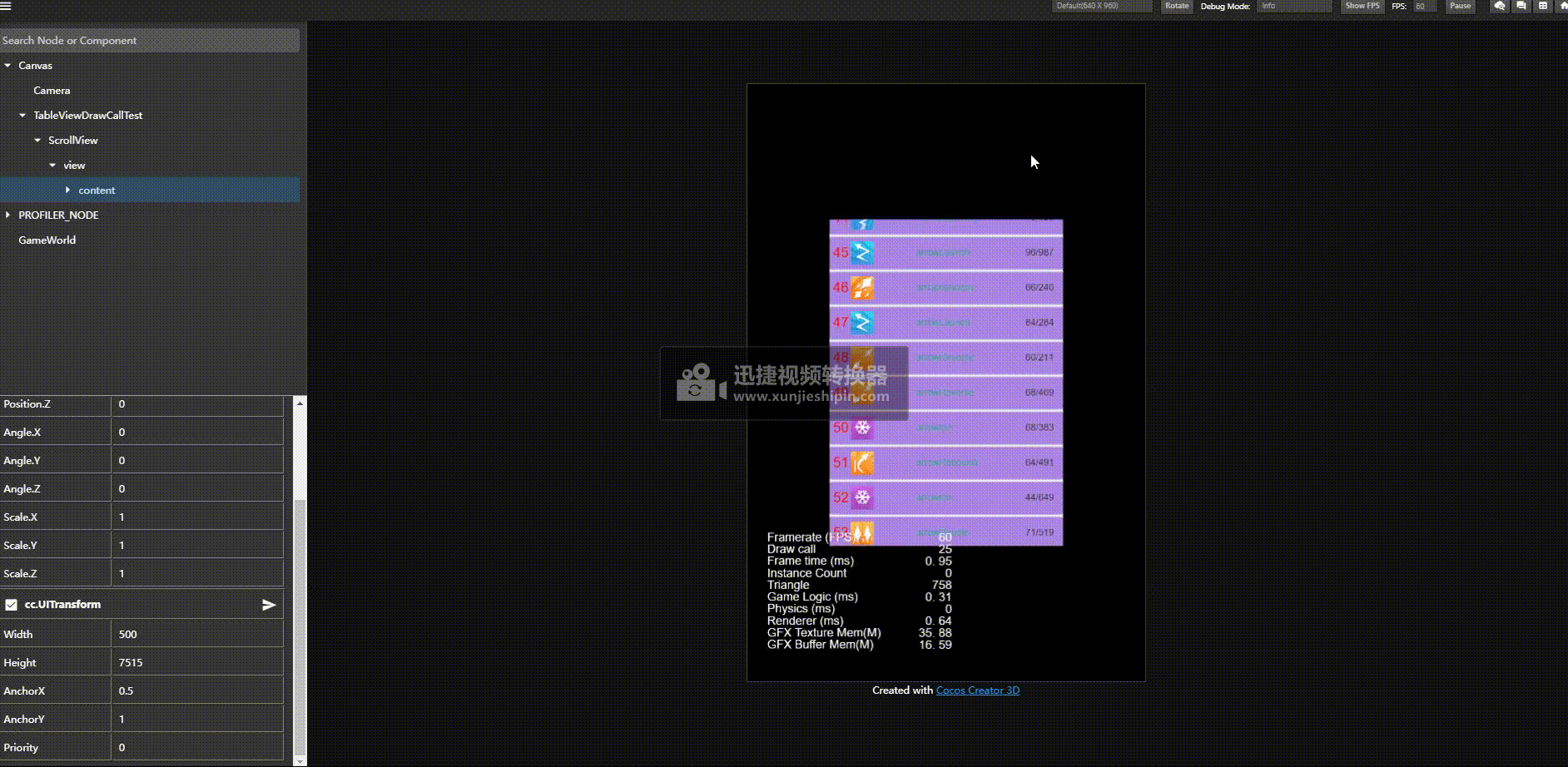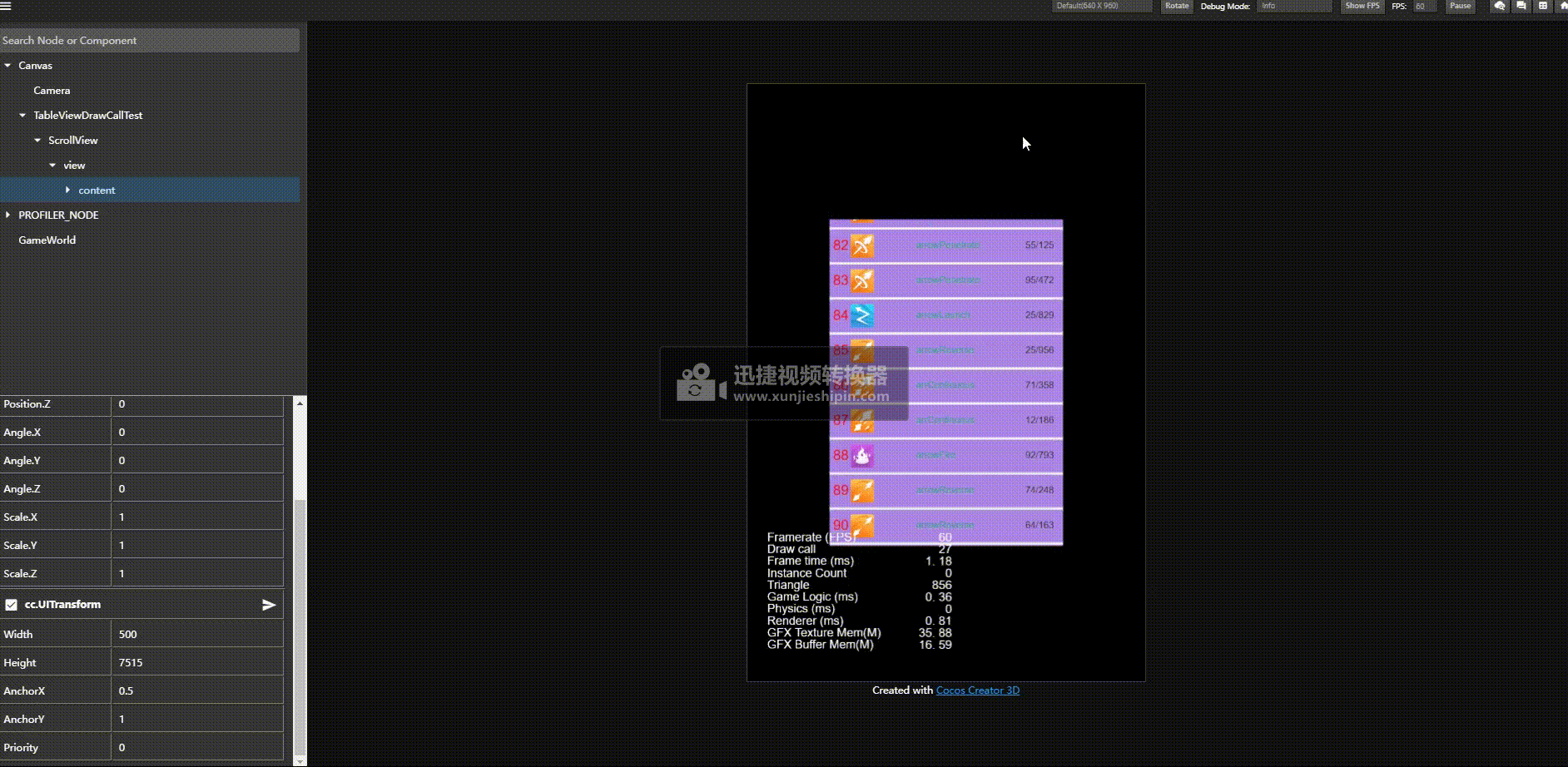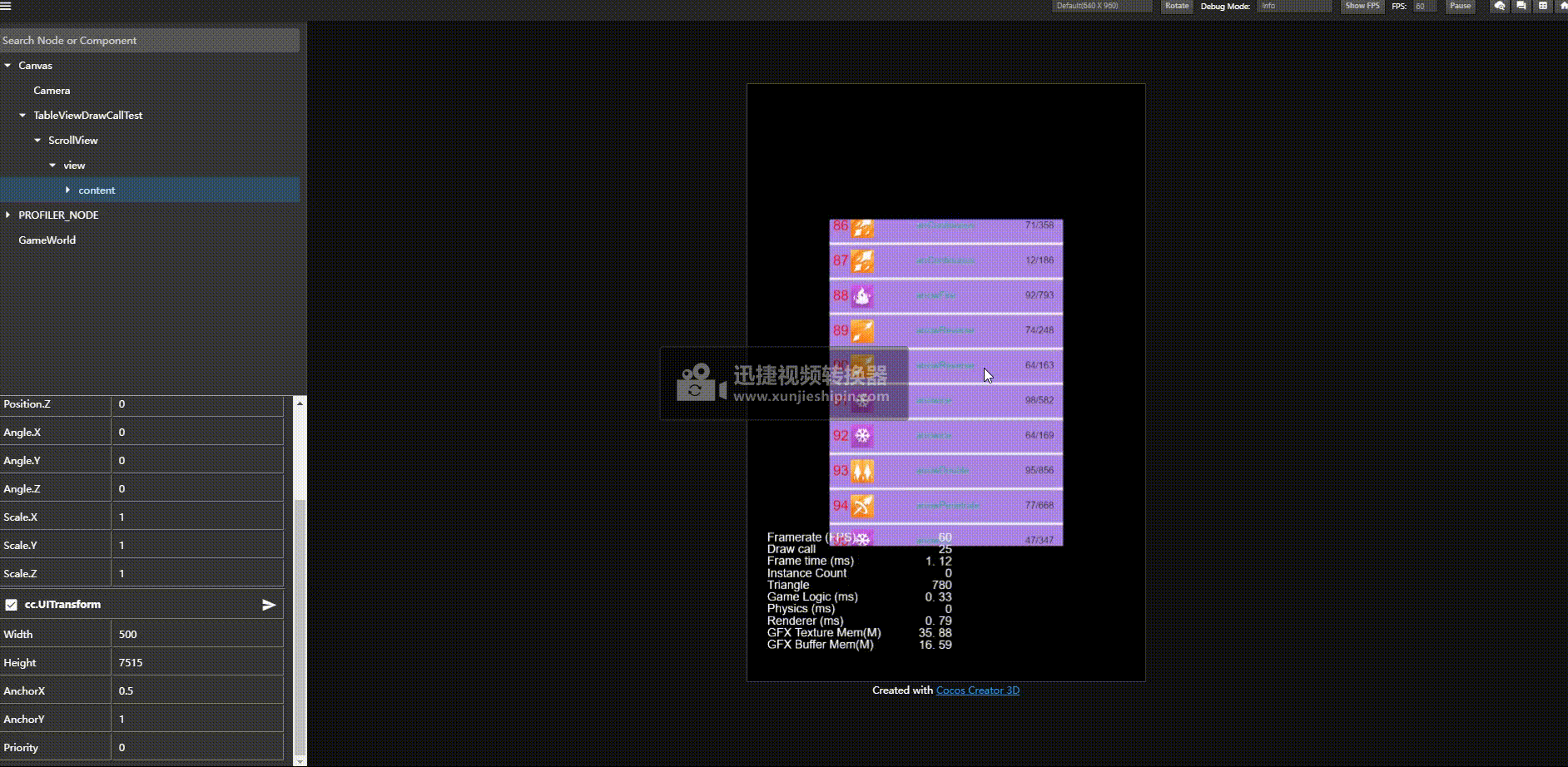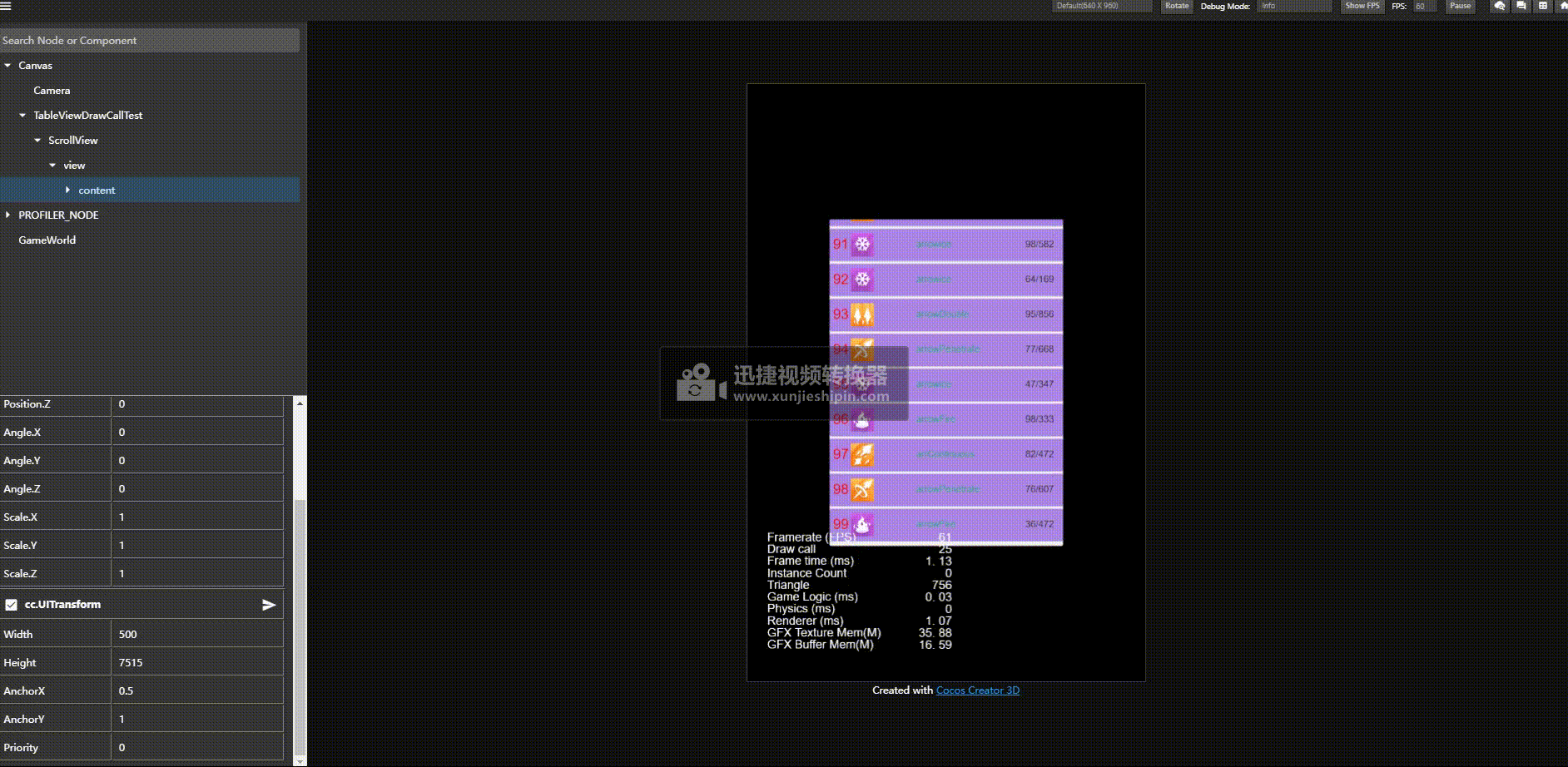
关键的点是,我们不需要改业务层,继续使用一个item一个预制体的方式,不需要层次。
实现方案主要利用了 Renderable2D 提供出来的 updateAssembler postUpdateAssembler 这一对接口,这对接口是渲染前置回调和节点所有节点渲染完毕的回调。
另外我们仔细查看 Render2D 的渲染过程发现
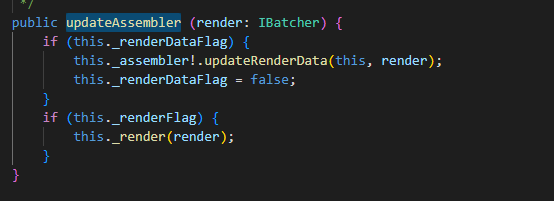
我们渲染是先触发渲染数据更新然后调用 _render 去触发渲染命令提交,并且是否能够合批也是在渲染命令提交的时候检测是否和之前渲染的能否合并否则开启新的渲染批次。
基于这一原理,那么我们是否可以前期收集要渲染的对象,然后架空 _render 回调,然后在我们主动根据我们希望的顺序去提交渲染命令达到将能合批的对象一个批次提交然后达到合批的策略呢。亲测有效。
基于前面的源码阅读,于是我在 scrollview 的content节点上添加一个 特殊的 Renderable2D 组件,将其子节点的渲染顺序重定义
import * as cc from 'cc';
const { ccclass, property } = cc._decorator;
interface IDelayRender{
_renderFlag : boolean;
_realRenderFunc(batcher: any);
}
@ccclass('RenderChange')
export class RenderChange extends cc.Renderable2D {
private m_renderlist : Array<string> = new Array();
private m_renderGroup : Map<string, Array<IDelayRender>> = new Map();
onDisable()
{
let renders = this.node.getComponentsInChildren(cc.Renderable2D);
renders.forEach(( render : cc.Renderable2D)=>{
let rendertemp = render as any;
if(rendertemp._realRenderFunc != null)
{
rendertemp._render = rendertemp._realRenderFunc
rendertemp._realRenderFunc = null!;
}
if(rendertemp._realPostRender != null)
{
rendertemp._postRender = rendertemp._realPostRender
rendertemp._realPostRender = null!;
}
});
}
private renderChild(node : cc.Node, prename : string)
{
if(!node.activeInHierarchy)return;
let curname = `${prename}$${node.name}`;
let render = node.getComponent(cc.Renderable2D);
if(render)
{
let arr = this.m_renderGroup.get(curname);
let isnewarr = false;
if(arr == null)
{
isnewarr = true;
arr = new Array();
this.m_renderlist.push(curname)
this.m_renderGroup.set(curname, arr);
}
let rendertemp = render as any;
if(rendertemp._realRenderFunc == null)
{
rendertemp._realRenderFunc = rendertemp._render;
rendertemp._render = function(){}
}
arr.push(rendertemp);
node.children.forEach(( ch : cc.Node )=>{
this.renderChild(ch, curname);
})
}
else
{
node.children.forEach(( ch : cc.Node )=>{
this.renderChild(ch, curname);
})
}
}
public updateAssembler (batcher: any) {
this.m_renderlist.length = 0;
this.m_renderGroup.clear();
this.node.children.forEach(( ch : cc.Node )=>{
this.renderChild(ch, "");
})
}
public postUpdateAssembler (batcher: any) {
this.m_renderlist.forEach(( name : string)=>{
let arr = this.m_renderGroup.get(name);
if(arr)
{
arr.forEach(( idrender : IDelayRender)=>{
if(idrender._renderFlag)
idrender._realRenderFunc(batcher);
})
}
})
}
}
本方案目前不支持 item中存在 Mask 组件,因为Mask目前合批过程中存在一定问题,正在研究中。