
和从前说再见
看完前面两篇文章,开发者们不淡定了,有很多朋友私信麒麟子说:
“加了这么多东西,性能能行吗?”
能行,不仅没降,反而在某些方面有大幅提升!
因为“性能提升”也是 3.6 作为重要的 Cocos Creator 里程碑版本规划中需要完成的目标。
这篇文章我们就来看看 Cocos Creator 3.6 中关于性能方面改进。
Cocos Creator 3.x 自推出以来,一直就被开发者们催更性能优化。 主要集中在几个方面:
- 原生性能
- 粒子性能
- 2D渲染性能
关注这几个问题的朋友们,是时候打开香槟,启动 Cocos Creator 3.6 ,和它们说再见了!
接下来,我们从实测结果数据,以及引擎为此所做的改动这两个层面,分别讲解 3.6 中带来的性能提升。
原生性能
测试数据
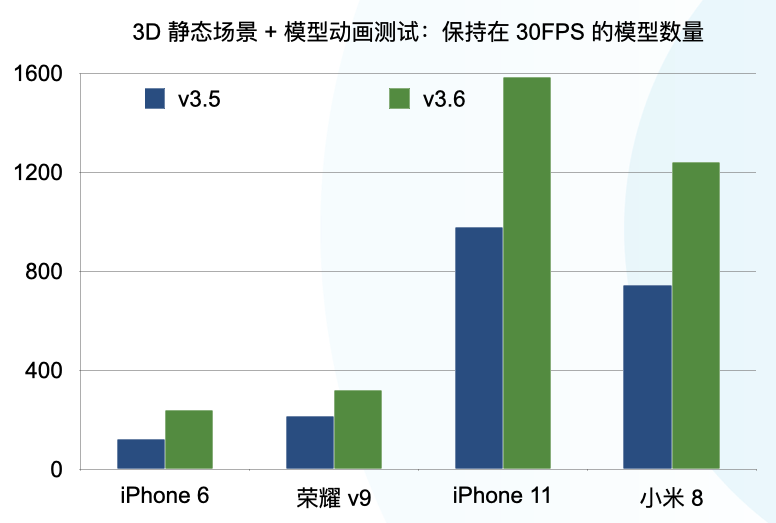
为了尽可能模拟复杂的执行环境,引擎组选择了静态场景+动画模型混合的测试用例。
从上图中可以明显地看到,同样的测试用例, v3.6 比 v3.5 高出了50%以上。
引擎原生化
在和引擎组交流后,得到的答复是:“方法比较简单,就是将原来处于TS层的场景管理、资源管理等模块,用C++重新实现了一遍”。
方法简单但并不表示工作量小,引擎组为此付出了一年多的努力。
但从结果上看,这一切努力都是值得的,自 Cocos Creator 3.6 版本开始, Cocos 引擎可以称得上 “双核引擎”了,即在原生平台为C++内核,在非原生平台为JS/TS内核。
这种做法在业内并不多见,因为它成本极高。需要使两套引擎核心保持对等架构,并且维持相同的渲染效果。
但也只有这样,才能更好地服务相应平台,在极端情况下为相应平台做最精细的优化。
V3.3 vs. V3.6

左图为 Cocos Creator 3.3 原生化状态,蓝色为C++部分,红色为TS部分,可以看出 v3.3 的状态为:
- TS模块:SeneGraph、Data Driven、AssetManager、Assets
- C++&TS模块:RenderScene
- C++模块:RenderPipeline、GFX、FrameGraph
右图为 Cocos Creator 3.6 原生化状态,绿色为C++部分,蓝色为TS部分,可以看出 v3.6 的状态为:
- TS模块:AssetManager
- C++&TS模块:Assets、Data Driven
- C++模块:SeneGraph、RenderScene、RenderPipeline、GFX、FrameGraph
从这个对比中可以看出,RenderScene 和 SceneGraph 模块的完全原生化,应该对此次的性能提升起到了主要作用。
从进展来看,目前 Assets、Data Driven 的原生化即将完成,AssetManager 也应该会在后面的版本中得到解决。 离完全原生化的目标实现不远了,相信届时 Cocos Creator 的原生端性能又会提升不少。
粒子性能
Created with Cocos Creator v3.6
上面的截图,来自于团队同事用 Cocos Creator 做的一个项目,里面的每一根蜡烛,地上的每一团火焰,都是由若干个粒子发射器组成的。 在 v3.5 中,这个场景跑起来特别吃力,只能关闭一些粒子特效。 但在 v3.6 版本中,场景特效全开的情况下,依然特别流畅。

开发者们也不只一次提到过,粒子系统的性能限制了美术的发挥空间,导致游戏效果受限,希望能够加入粒子合批,提升性能。
3D渲染中的合批有两种方案:
- 网格合并(Merging Vertex Buffers)
- 几何体实例化(GPU Instancing)
由于几何体实例化需要硬件和系统支持,在前几年的系统中,引擎会选择在支持的设备中采用几何体实体化方案,在不支持的设备中退回到网格合并方案,以确保最大的可用性。
但 DrawCall 导致的性能瓶颈本身就以 CPU 侧为主,而网格合并又是以增加 CPU 运算负担为代价的,用网格合并换 DrawCall 无异于 CPU 资源换 CPU 资源,在某些情况下可能适得其反。
随着硬件的增强和新版图形API普及率的提升,几何体实例化的覆盖率已接近100%。因此此次粒子系统的合并选择了几何体实例化作为合批方案。
注意:Cocos Creator 3.6 及以上版本的 CPU 粒子和 GPU 粒子均支持几何体实例化(GPU Instancing)方式合批。
与此同时,Mesh 粒子也支持合批了,对于粒子系统而言,不管是 Billboard 还是 Mesh,二者在合批处理上并无差别。
麒麟子用引擎组给的测试用例测试了一下, CPU粒子在545个的情况下,依然能够保持在30帧以上,如下所示:

想要亲自尝试的朋友,可以自行下载测试案例:https://github.com/cocos/cocos-benchmark ,从 lobby 场景进入。
2D渲染性能
Cocos Creator 3.x 的 2D 渲染性能一直备受关注,开发者最希望的就是有一天 3.x 的性能能够赶上 2.x 版本。
令人惊喜的是,在 7 月 22 日的社区公测版本中,就已经包含了原生平台 2D 渲染性能优化。如下图所示:

忍不住要摘抄一下:2D性能在原生平台各项性能测试已赶上2.x。
从下图中我们可以看出,在低端设备(HUAWEI-荣耀v9 Android 、iPhone 6s iOS)和中端设备(XIAOMI8 Android、iPhone 11 iOS)上,都取得了满意的表现。
数据来源于Cocos引擎测试报告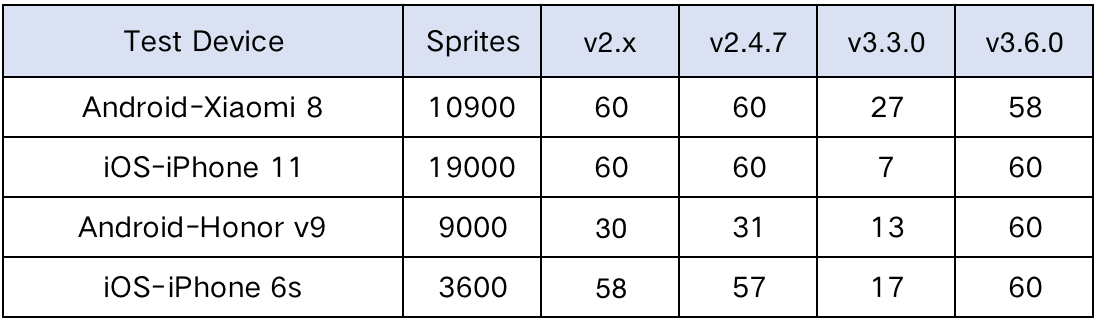
费了好大的力气,麒麟子找到了负责这一次2D渲染优化升级的引擎工程师之一,鸭舌同学。了解到了一些2D性能提升的主要工作。
引擎原生化
受益于引擎原生化,许多计算由 TS 改为了 C++,仅从语言运算能力层面的就提升了不少性能。
当模块改为C++后,C++本身的语言特性,使引擎团队可以用更多的方法去优化性能。 这一部分又带来了不少提升。
内存优化
各位没看错,2D的内存使用量也优化了。之所以内存优化出现在性能优化这里,是因为内存优化也是受 C++ 语言特性而带来的。
在使用了一些字节对齐(Byte Alignment)和联合体(Union)之后,2D对象的内存使用量仅为原来的一半。
TS层优化
引擎原生化后,TS层变得更加简洁了,同时也带来了一次优化结构的机会。 在这个过程中,去除了一些冗余的运算,加入了惰性更新机制。当一个组件的某属性没有变化时,不会做运算。
管线优化
为了保持统一,减少故障率,3.x 版本中早期的 2D 对象渲染是共享的3D 对象渲染流程,但由于 3D 对象渲染流程的复杂度,无论从CPU开销,还是内存开销都比纯2D高出不少。
在做原生化的同时,也对这个问题做了优化,重新梳理了专门的 2D 管线,2D 对象与 3D 对象的渲染完全独立,确保了 2D 渲染以最小的开销进行,在CPU运算开销、DrawCall、内存使用量、IO过高导致的耗电和发烫等方面均有显著提升。
总结
性能的提升是一个常态化工作,是每一个版本都会迭代增强的部分。
Cocos Creator 3.6 并不完美,如在包体、内存、加载速度等方面还有很大的提升空间,官方的性能测试也不能覆盖所有的项目情况,更多实际的数据还需要开发者自行验证并给予反馈。
不过,麒麟子相信,只要持续不断地优化,将来肯定会全方位超越 2.x,成为一个优秀的2D&3D一体化双核引擎。
不管是 原生性能 、粒子性能还是2D渲染性能,都是开发者在项目中经常遇到且无法绕过的坎,只有引擎将此完善,开发者才能将自己的产品做得更好。
在这个移动、便携、可穿戴设备日益精细化发展的年代,追求性能与效果的极致,成为了最矛盾却又最刚性的需求。
很高兴看到 Cocos Creator 始终在不遗余力地完善编辑器功能、提升开发效率,与此同时,在增强渲染特性、提升渲染效果的同时依然保持了它双核引擎(Native与Web)、伸缩性架构(高性能、低功耗,易定制)的优势。
不管是“让游戏开发变得更简单”,还是“以技术驱动数字内容行业效率提升”。 在提升生产效率这个关键点上,Cocos 始终初心未改,砥砺前行。
写在最后

至此,关于 Cocos Creator 3.6 新特性的盘点就结束了。
如前文所说,做这个 3.6 版本特性盘点的初衷,是希望给没有时间去分析新特性的朋友们一个详细的解释,挖掘 3.6 中的重要特性、功能改进的价值并呈现到大家面前,以供项目选型和升级决策提供一个有根据的参考。
值得惊喜的是,通过这一次的盘点,麒麟子也收获不少。
在盘点的过程中,麒麟子认真学习并梳理了相关细节,全方位的了解了 3.6 的升级过程以及覆盖的要点,在以后和开发者的交流中会更高效、更准确。
在对细节进行梳理的过程中,也遇上过许多缺失的信息、问题,在与相关同事交流的过程中,更加熟悉了同事们的工作状态和方案考量因素,更能理解引擎的发展路线和下一步规划。 同时也特别感谢被我打扰过的同事们,每一位都是知无不言,有的人还手把手教会了我如何使用新特性。
期待下一个引擎版本,这样的文章,麒麟子还想继续写!
想第一时间获得内容更新的朋友,可以关注麒麟子公众号:

或者 知乎主页
Cocos Creator 3.6 新特性详解 1/3:编辑器篇
Cocos Creator 3.6 新特性详解 2/3:渲染篇


 厦大这么有名,居然人才不足,是不是都被上海吸了
厦大这么有名,居然人才不足,是不是都被上海吸了